 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: AI for Science Should Treat Measurement-to-Dataset Pipelines as Inference Components
May 23, 2026AI for Science (AI4Science) workflows often treat the released dataset as a fixed interface to the underlying system. However, in domains relying on \emph{indirect observation}, the learner observes a derivative representation produced by multi-stage measurement, reconstruction, and preprocessing pipelines. \textbf{We argue that these measurement-to-dataset pipelines are inference components: treating their outputs as ``given data'' freezes an observation model and obscures uncertainty over feasible pipeline choices.} We identify three failure modes arising from this ``frozen lens'': \textbf{(C1) hidden hypothesis space}, where the released dataset does not specify the pipeline configuration or its validity conditions; \textbf{(C2) uncertified transportability}, where a pipeline may be documented but its regime of validity is untested, so failures under distribution shift cannot be adjudicated; \textbf{(C3) ungoverned multiplicity}, where many defensible pipelines exist and dispersion is real but not propagated into uncertainty-aware evidence. We stress-test these claims with a large-scale neuroscience empirical audit, finding a survival rate of $\approx 0.0004\%$ under a cross-dataset stability criterion. We call on the AI4Science community to make pipelines \emph{computable} inference objects via domain-specific Computable Observation Frameworks. This shift enables quantifying pipeline adequacy and stability, converting implicit implementation choices into auditable, reproducible, and cumulative scientific evidence.
Accelerating Benchmarking of Functional Connectivity Modeling via Structure-aware Core-set Selection
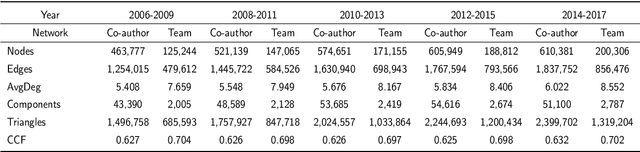
Feb 05, 2026Benchmarking the hundreds of functional connectivity (FC) modeling methods on large-scale fMRI datasets is critical for reproducible neuroscience. However, the combinatorial explosion of model-data pairings makes exhaustive evaluation computationally prohibitive, preventing such assessments from becoming a routine pre-analysis step. To break this bottleneck, we reframe the challenge of FC benchmarking by selecting a small, representative core-set whose sole purpose is to preserve the relative performance ranking of FC operators. We formalize this as a ranking-preserving subset selection problem and propose Structure-aware Contrastive Learning for Core-set Selection (SCLCS), a self-supervised framework to select these core-sets. SCLCS first uses an adaptive Transformer to learn each sample's unique FC structure. It then introduces a novel Structural Perturbation Score (SPS) to quantify the stability of these learned structures during training, identifying samples that represent foundational connectivity archetypes. Finally, while SCLCS identifies stable samples via a top-k ranking, we further introduce a density-balanced sampling strategy as a necessary correction to promote diversity, ensuring the final core-set is both structurally robust and distributionally representative. On the large-scale REST-meta-MDD dataset, SCLCS preserves the ground-truth model ranking with just 10% of the data, outperforming state-of-the-art (SOTA) core-set selection methods by up to 23.2% in ranking consistency (nDCG@k). To our knowledge, this is the first work to formalize core-set selection for FC operator benchmarking, thereby making large-scale operators comparisons a feasible and integral part of computational neuroscience. Code is publicly available on https://github.com/lzhan94swu/SCLCS
LIR$^3$AG: A Lightweight Rerank Reasoning Strategy Framework for Retrieval-Augmented Generation
Dec 20, 2025Retrieval-Augmented Generation (RAG) effectively enhances Large Language Models (LLMs) by incorporating retrieved external knowledge into the generation process. Reasoning models improve LLM performance in multi-hop QA tasks, which require integrating and reasoning over multiple pieces of evidence across different documents to answer a complex question. However, they often introduce substantial computational costs, including increased token consumption and inference latency. To better understand and mitigate this trade-off, we conduct a comprehensive study of reasoning strategies for reasoning models in RAG multi-hop QA tasks. Our findings reveal that reasoning models adopt structured strategies to integrate retrieved and internal knowledge, primarily following two modes: Context-Grounded Reasoning, which relies directly on retrieved content, and Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge. To this end, we propose a novel Lightweight Rerank Reasoning Strategy Framework for RAG (LiR$^3$AG) to enable non-reasoning models to transfer reasoning strategies by restructuring retrieved evidence into coherent reasoning chains. LiR$^3$AG significantly reduce the average 98% output tokens overhead and 58.6% inferencing time while improving 8B non-reasoning model's F1 performance ranging from 6.2% to 22.5% to surpass the performance of 32B reasoning model in RAG, offering a practical and efficient path forward for RAG systems.
Deep learning framework for predicting stochastic take-off and die-out of early spreading
Oct 06, 2025Large-scale outbreaks of epidemics, misinformation, or other harmful contagions pose significant threats to human society, yet the fundamental question of whether an emerging outbreak will escalate into a major epidemic or naturally die out remains largely unaddressed. This problem is challenging, partially due to inadequate data during the early stages of outbreaks and also because established models focus on average behaviors of large epidemics rather than the stochastic nature of small transmission chains. Here, we introduce the first systematic framework for forecasting whether initial transmission events will amplify into major outbreaks or fade into extinction during early stages, when intervention strategies can still be effectively implemented. Using extensive data from stochastic spreading models, we developed a deep learning framework that predicts early-stage spreading outcomes in real-time. Validation across Erd\H{o}s-R\'enyi and Barab\'asi-Albert networks with varying infectivity levels shows our method accurately forecasts stochastic spreading events well before potential outbreaks, demonstrating robust performance across different network structures and infectivity scenarios.To address the challenge of sparse data during early outbreak stages, we further propose a pretrain-finetune framework that leverages diverse simulation data for pretraining and adapts to specific scenarios through targeted fine-tuning. The pretrain-finetune framework consistently outperforms baseline models, achieving superior performance even when trained on limited scenario-specific data. To our knowledge, this work presents the first framework for predicting stochastic take-off versus die-out. This framework provides valuable insights for epidemic preparedness and public health decision-making, enabling more informed early intervention strategies.
PSNE: Efficient Spectral Sparsification Algorithms for Scaling Network Embedding
Aug 05, 2024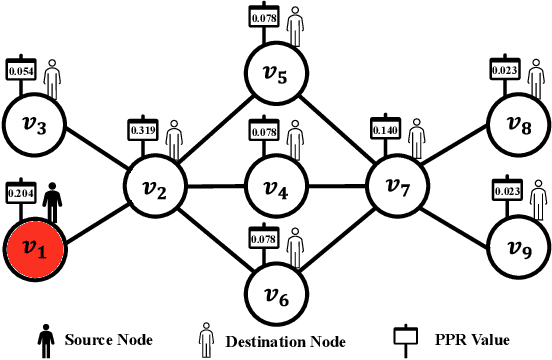

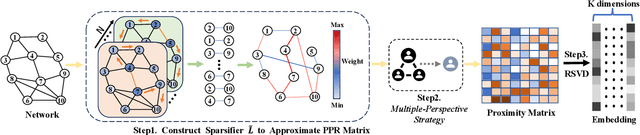
Network embedding has numerous practical applications and has received extensive attention in graph learning, which aims at mapping vertices into a low-dimensional and continuous dense vector space by preserving the underlying structural properties of the graph. Many network embedding methods have been proposed, among which factorization of the Personalized PageRank (PPR for short) matrix has been empirically and theoretically well supported recently. However, several fundamental issues cannot be addressed. (1) Existing methods invoke a seminal Local Push subroutine to approximate \textit{a single} row or column of the PPR matrix. Thus, they have to execute $n$ ($n$ is the number of nodes) Local Push subroutines to obtain a provable PPR matrix, resulting in prohibitively high computational costs for large $n$. (2) The PPR matrix has limited power in capturing the structural similarity between vertices, leading to performance degradation. To overcome these dilemmas, we propose PSNE, an efficient spectral s\textbf{P}arsification method for \textbf{S}caling \textbf{N}etwork \textbf{E}mbedding, which can fast obtain the embedding vectors that retain strong structural similarities. Specifically, PSNE first designs a matrix polynomial sparser to accelerate the calculation of the PPR matrix, which has a theoretical guarantee in terms of the Frobenius norm. Subsequently, PSNE proposes a simple but effective multiple-perspective strategy to enhance further the representation power of the obtained approximate PPR matrix. Finally, PSNE applies a randomized singular value decomposition algorithm on the sparse and multiple-perspective PPR matrix to get the target embedding vectors. Experimental evaluation of real-world and synthetic datasets shows that our solutions are indeed more efficient, effective, and scalable compared with ten competitors.
Collaborative Team Recognition: A Core Plus Extension Structure
Jun 07, 2024
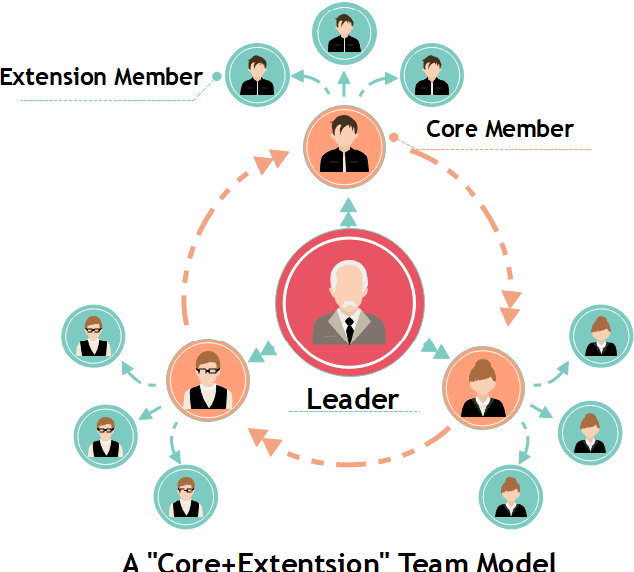
Scientific collaboration is a significant behavior in knowledge creation and idea exchange. To tackle large and complex research questions, a trend of team formation has been observed in recent decades. In this study, we focus on recognizing collaborative teams and exploring inner patterns using scholarly big graph data. We propose a collaborative team recognition (CORE) model with a "core + extension" team structure to recognize collaborative teams in large academic networks. In CORE, we combine an effective evaluation index called the collaboration intensity index with a series of structural features to recognize collaborative teams in which members are in close collaboration relationships. Then, CORE is used to guide the core team members to their extension members. CORE can also serve as the foundation for team-based research. The simulation results indicate that CORE reveals inner patterns of scientific collaboration: senior scholars have broad collaborative relationships and fixed collaboration patterns, which are the underlying mechanisms of team assembly. The experimental results demonstrate that CORE is promising compared with state-of-the-art methods.
A performance characteristic curve for model evaluation: the application in information diffusion prediction
Sep 19, 2023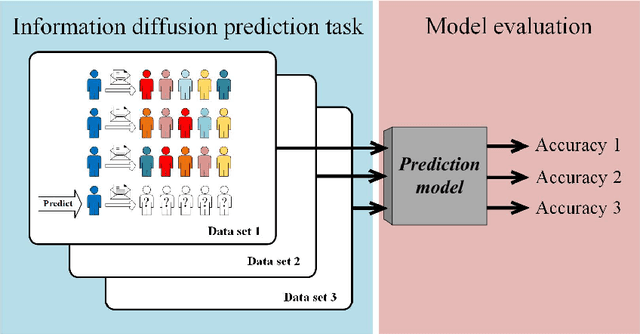



The information diffusion prediction on social networks aims to predict future recipients of a message, with practical applications in marketing and social media. While different prediction models all claim to perform well, general frameworks for performance evaluation remain limited. Here, we aim to identify a performance characteristic curve for a model, which captures its performance on tasks of different complexity. We propose a metric based on information entropy to quantify the randomness in diffusion data, then identify a scaling pattern between the randomness and the prediction accuracy of the model. Data points in the patterns by different sequence lengths, system sizes, and randomness all collapse into a single curve, capturing a model's inherent capability of making correct predictions against increased uncertainty. Given that this curve has such important properties that it can be used to evaluate the model, we define it as the performance characteristic curve of the model. The validity of the curve is tested by three prediction models in the same family, reaching conclusions in line with existing studies. Also, the curve is successfully applied to evaluate two distinct models from the literature. Our work reveals a pattern underlying the data randomness and prediction accuracy. The performance characteristic curve provides a new way to systematically evaluate models' performance, and sheds light on future studies on other frameworks for model evaluation.
Multi-feature concatenation and multi-classifier stacking: an interpretable and generalizable machine learning method for MDD discrimination with rsfMRI
Aug 18, 2023Major depressive disorder is a serious and heterogeneous psychiatric disorder that needs accurate diagnosis. Resting-state functional MRI (rsfMRI), which captures multiple perspectives on brain structure, function, and connectivity, is increasingly applied in the diagnosis and pathological research of mental diseases. Different machine learning algorithms are then developed to exploit the rich information in rsfMRI and discriminate MDD patients from normal controls. Despite recent advances reported, the discrimination accuracy has room for further improvement. The generalizability and interpretability of the method are not sufficiently addressed either. Here, we propose a machine learning method (MFMC) for MDD discrimination by concatenating multiple features and stacking multiple classifiers. MFMC is tested on the REST-meta-MDD data set that contains 2428 subjects collected from 25 different sites. MFMC yields 96.9% MDD discrimination accuracy, demonstrating a significant improvement over existing methods. In addition, the generalizability of MFMC is validated by the good performance when the training and testing subjects are from independent sites. The use of XGBoost as the meta classifier allows us to probe the decision process of MFMC. We identify 13 feature values related to 9 brain regions including the posterior cingulate gyrus, superior frontal gyrus orbital part, and angular gyrus, which contribute most to the classification and also demonstrate significant differences at the group level. The use of these 13 feature values alone can reach 87% of MFMC's full performance when taking all feature values. These features may serve as clinically useful diagnostic and prognostic biomarkers for mental disorders in the future.
An Interpretable Loan Credit Evaluation Method Based on Rule Representation Learner
Apr 03, 2023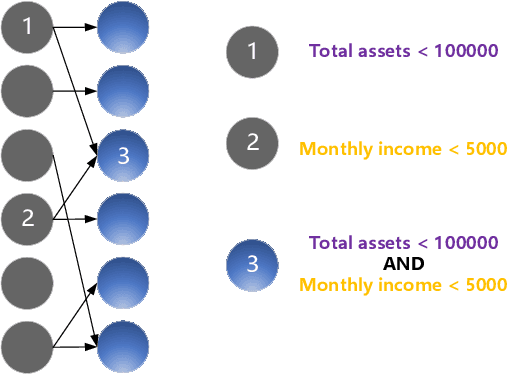
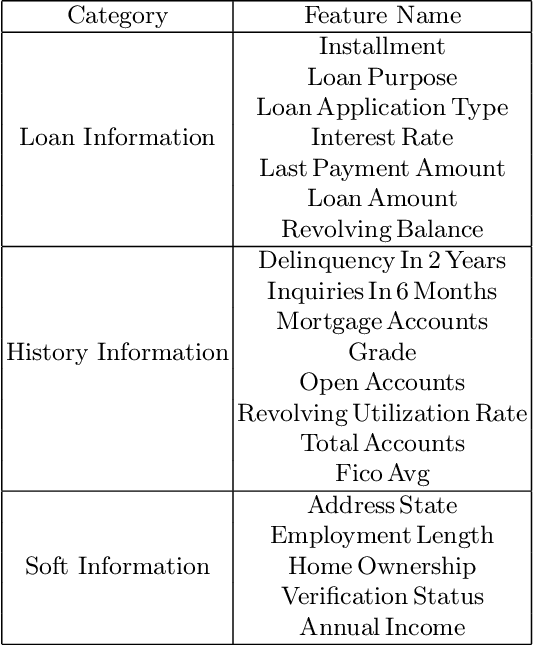


The interpretability of model has become one of the obstacles to its wide application in the high-stake fields. The usual way to obtain interpretability is to build a black-box first and then explain it using the post-hoc methods. However, the explanations provided by the post-hoc method are not always reliable. Instead, we design an intrinsically interpretable model based on RRL(Rule Representation Learner) for the Lending Club dataset. Specifically, features can be divided into three categories according to their characteristics of themselves and build three sub-networks respectively, each of which is similar to a neural network with a single hidden layer but can be equivalently converted into a set of rules. During the training, we learned tricks from previous research to effectively train binary weights. Finally, our model is compared with the tree-based model. The results show that our model is much better than the interpretable decision tree in performance and close to other black-box, which is of practical significance to both financial institutions and borrowers. More importantly, our model is used to test the correctness of the explanations generated by the post-hoc method, the results show that the post-hoc method is not always reliable.
Author Name Disambiguation via Heterogeneous Network Embedding from Structural and Semantic Perspectives
Dec 24, 2022Name ambiguity is common in academic digital libraries, such as multiple authors having the same name. This creates challenges for academic data management and analysis, thus name disambiguation becomes necessary. The procedure of name disambiguation is to divide publications with the same name into different groups, each group belonging to a unique author. A large amount of attribute information in publications makes traditional methods fall into the quagmire of feature selection. These methods always select attributes artificially and equally, which usually causes a negative impact on accuracy. The proposed method is mainly based on representation learning for heterogeneous networks and clustering and exploits the self-attention technology to solve the problem. The presentation of publications is a synthesis of structural and semantic representations. The structural representation is obtained by meta-path-based sampling and a skip-gram-based embedding method, and meta-path level attention is introduced to automatically learn the weight of each feature. The semantic representation is generated using NLP tools. Our proposal performs better in terms of name disambiguation accuracy compared with baselines and the ablation experiments demonstrate the improvement by feature selection and the meta-path level attention in our method. The experimental results show the superiority of our new method for capturing the most attributes from publications and reducing the impact of redundant information.