 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Benchmarking of Functional Connectivity Modeling via Structure-aware Core-set Selection
Feb 05, 2026Benchmarking the hundreds of functional connectivity (FC) modeling methods on large-scale fMRI datasets is critical for reproducible neuroscience. However, the combinatorial explosion of model-data pairings makes exhaustive evaluation computationally prohibitive, preventing such assessments from becoming a routine pre-analysis step. To break this bottleneck, we reframe the challenge of FC benchmarking by selecting a small, representative core-set whose sole purpose is to preserve the relative performance ranking of FC operators. We formalize this as a ranking-preserving subset selection problem and propose Structure-aware Contrastive Learning for Core-set Selection (SCLCS), a self-supervised framework to select these core-sets. SCLCS first uses an adaptive Transformer to learn each sample's unique FC structure. It then introduces a novel Structural Perturbation Score (SPS) to quantify the stability of these learned structures during training, identifying samples that represent foundational connectivity archetypes. Finally, while SCLCS identifies stable samples via a top-k ranking, we further introduce a density-balanced sampling strategy as a necessary correction to promote diversity, ensuring the final core-set is both structurally robust and distributionally representative. On the large-scale REST-meta-MDD dataset, SCLCS preserves the ground-truth model ranking with just 10% of the data, outperforming state-of-the-art (SOTA) core-set selection methods by up to 23.2% in ranking consistency (nDCG@k). To our knowledge, this is the first work to formalize core-set selection for FC operator benchmarking, thereby making large-scale operators comparisons a feasible and integral part of computational neuroscience. Code is publicly available on https://github.com/lzhan94swu/SCLCS
Multi-feature concatenation and multi-classifier stacking: an interpretable and generalizable machine learning method for MDD discrimination with rsfMRI
Aug 18, 2023Major depressive disorder is a serious and heterogeneous psychiatric disorder that needs accurate diagnosis. Resting-state functional MRI (rsfMRI), which captures multiple perspectives on brain structure, function, and connectivity, is increasingly applied in the diagnosis and pathological research of mental diseases. Different machine learning algorithms are then developed to exploit the rich information in rsfMRI and discriminate MDD patients from normal controls. Despite recent advances reported, the discrimination accuracy has room for further improvement. The generalizability and interpretability of the method are not sufficiently addressed either. Here, we propose a machine learning method (MFMC) for MDD discrimination by concatenating multiple features and stacking multiple classifiers. MFMC is tested on the REST-meta-MDD data set that contains 2428 subjects collected from 25 different sites. MFMC yields 96.9% MDD discrimination accuracy, demonstrating a significant improvement over existing methods. In addition, the generalizability of MFMC is validated by the good performance when the training and testing subjects are from independent sites. The use of XGBoost as the meta classifier allows us to probe the decision process of MFMC. We identify 13 feature values related to 9 brain regions including the posterior cingulate gyrus, superior frontal gyrus orbital part, and angular gyrus, which contribute most to the classification and also demonstrate significant differences at the group level. The use of these 13 feature values alone can reach 87% of MFMC's full performance when taking all feature values. These features may serve as clinically useful diagnostic and prognostic biomarkers for mental disorders in the future.
CoarSAS2hvec: Heterogeneous Information Network Embedding with Balanced Network Sampling
Oct 12, 2021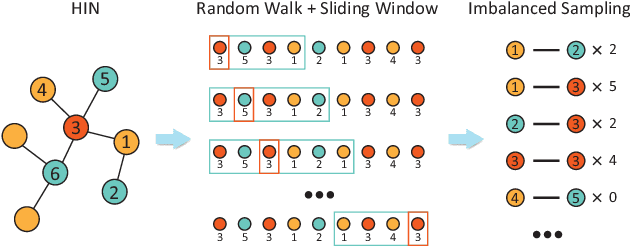


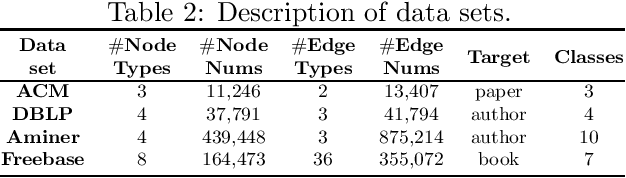
Heterogeneous information network (HIN) embedding aims to find the representations of nodes that preserve the proximity between entities of different nature. A family of approaches that are wildly adopted applies random walk to generate a sequence of heterogeneous context, from which the embedding is learned. However, due to the multipartite graph structure of HIN, hub nodes tend to be over-represented in the sampled sequence, giving rise to imbalanced samples of the network. Here we propose a new embedding method CoarSAS2hvec. The self-avoid short sequence sampling with the HIN coarsening procedure (CoarSAS) is utilized to better collect the rich information in HIN. An optimized loss function is used to improve the performance of the HIN structure embedding. CoarSAS2hvec outperforms nine other methods in two different tasks on four real-world data sets. The ablation study confirms that the samples collected by CoarSAS contain richer information of the network compared with those by other methods, which is characterized by a higher information entropy. Hence, the traditional loss function applied to samples by CoarSAS can also yield improved results. Our work addresses a limitation of the random-walk-based HIN embedding that has not been emphasized before, which can shed light on a range of problems in HIN analyses.