 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-HGCN: A Dual-Stream Hypergraph Convolutional Network for Predicting Student Engagement via Social Contagion
Dec 23, 2025Student engagement is a critical factor influencing academic success and learning outcomes. Accurately predicting student engagement is essential for optimizing teaching strategies and providing personalized interventions. However, most approaches focus on single-dimensional feature analysis and assessing engagement based on individual student factors. In this work, we propose a dual-stream multi-feature fusion model based on hypergraph convolutional networks (DS-HGCN), incorporating social contagion of student engagement. DS-HGCN enables accurate prediction of student engagement states by modeling multi-dimensional features and their propagation mechanisms between students. The framework constructs a hypergraph structure to encode engagement contagion among students and captures the emotional and behavioral differences and commonalities by multi-frequency signals. Furthermore, we introduce a hypergraph attention mechanism to dynamically weigh the influence of each student, accounting for individual differences in the propagation process. Extensive experiments on public benchmark datasets demonstrate that our proposed method achieves superior performance and significantly outperforms existing state-of-the-art approaches.
End-to-end Graph Learning Approach for Cognitive Diagnosis of Student Tutorial
Oct 30, 2024Cognitive diagnosis (CD) utilizes students' existing studying records to estimate their mastery of unknown knowledge concepts, which is vital for evaluating their learning abilities. Accurate CD is extremely challenging because CD is associated with complex relationships and mechanisms among students, knowledge concepts, studying records, etc. However, existing approaches loosely consider these relationships and mechanisms by a non-end-to-end learning framework, resulting in sub-optimal feature extractions and fusions for CD. Different from them, this paper innovatively proposes an End-to-end Graph Neural Networks-based Cognitive Diagnosis (EGNN-CD) model. EGNN-CD consists of three main parts: knowledge concept network (KCN), graph neural networks-based feature extraction (GNNFE), and cognitive ability prediction (CAP). First, KCN constructs CD-related interaction by comprehensively extracting physical information from students, exercises, and knowledge concepts. Second, a four-channel GNNFE is designed to extract high-order and individual features from the constructed KCN. Finally, CAP employs a multi-layer perceptron to fuse the extracted features to predict students' learning abilities in an end-to-end learning way. With such designs, the feature extractions and fusions are guaranteed to be comprehensive and optimal for CD. Extensive experiments on three real datasets demonstrate that our EGNN-CD achieves significantly higher accuracy than state-of-the-art models in CD.
ResEnsemble-DDPM: Residual Denoising Diffusion Probabilistic Models for Ensemble Learning
Dec 04, 2023Nowadays, denoising diffusion probabilistic models have been adapted for many image segmentation tasks. However, existing end-to-end models have already demonstrated remarkable capabilities. Rather than using denoising diffusion probabilistic models alone, integrating the abilities of both denoising diffusion probabilistic models and existing end-to-end models can better improve the performance of image segmentation. Based on this, we implicitly introduce residual term into the diffusion process and propose ResEnsemble-DDPM, which seamlessly integrates the diffusion model and the end-to-end model through ensemble learning. The output distributions of these two models are strictly symmetric with respect to the ground truth distribution, allowing us to integrate the two models by reducing the residual term. Experimental results demonstrate that our ResEnsemble-DDPM can further improve the capabilities of existing models. Furthermore, its ensemble learning strategy can be generalized to other downstream tasks in image generation and get strong competitiveness.
Resfusion: Prior Residual Noise embedded Denoising Diffusion Probabilistic Models
Nov 25, 2023



Recently, Denoising Diffusion Probabilistic Models have been widely used in image segmentation, by generating segmentation masks conditioned on the input image. However, previous works can not seamlessly integrate existing end-to-end models with denoising diffusion models. Existing research can only select acceleration steps based on experience rather than calculating them specifically. Moreover, most methods are limited to small models and small-scale datasets, unable to generalize to general datasets and a wider range of tasks. Therefore, we propose Resfusion with a novel resnoise-diffusion process, which gradually generates segmentation masks or any type of target image, seamlessly integrating state-of-the-art end-to-end models and denoising diffusion models. Resfusion bridges the discrepancy between the likelihood output and the ground truth output through a Markov process. Through the novel smooth equivalence transformation in resnoise-diffusion process, we determine the optimal acceleration step. Experimental results demonstrate that Resfusion combines the capabilities of existing end-to-end models and denoising diffusion models, further enhancing performance and achieving outstanding results. Moreover, Resfusion is not limited to segmentation tasks, it can easily generalize to any general tasks of image generation and exhibit strong competitiveness.
Aligning Language Models with Offline Reinforcement Learning from Human Feedback
Aug 23, 2023Learning from human preferences is crucial for language models (LMs) to effectively cater to human needs and societal values. Previous research has made notable progress by leveraging human feedback to follow instructions. However, these approaches rely primarily on online reinforcement learning (RL) techniques like Proximal Policy Optimization (PPO), which have been proven unstable and challenging to tune for language models. Moreover, PPO requires complex distributed system implementation, hindering the efficiency of large-scale distributed training. In this study, we propose an offline reinforcement learning from human feedback (RLHF) framework to align LMs using pre-generated samples without interacting with RL environments. Specifically, we explore maximum likelihood estimation (MLE) with filtering, reward-weighted regression (RWR), and Decision Transformer (DT) to align language models to human preferences. By employing a loss function similar to supervised fine-tuning, our methods ensure more stable model training than PPO with a simple machine learning system~(MLSys) and much fewer (around 12.3\%) computing resources. Experimental results demonstrate the DT alignment outperforms other Offline RLHF methods and is better than PPO.
Transforming Graphs for Enhanced Attribute-Based Clustering: An Innovative Graph Transformer Method
Jun 21, 2023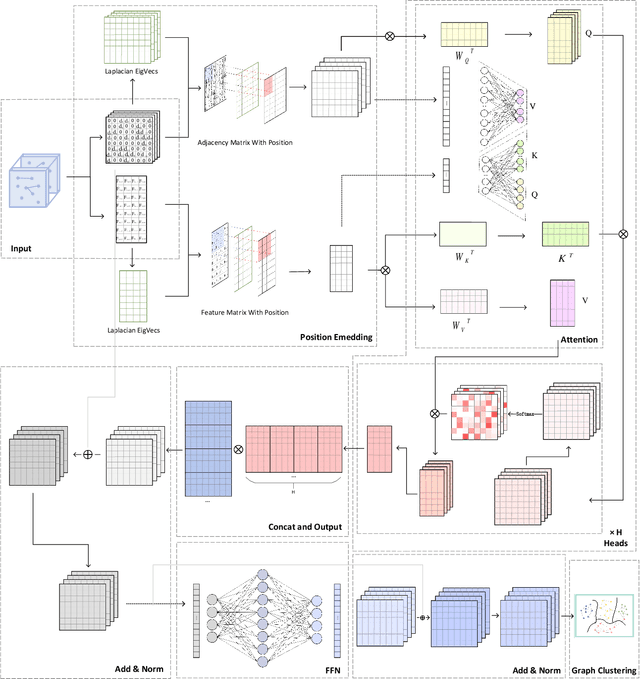

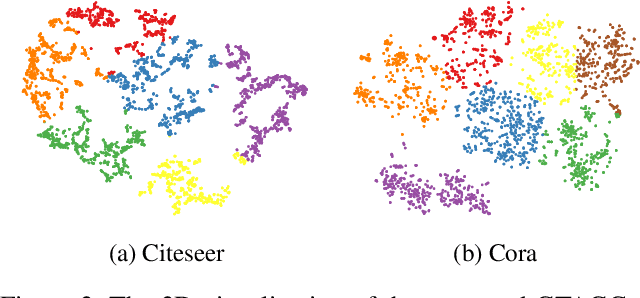
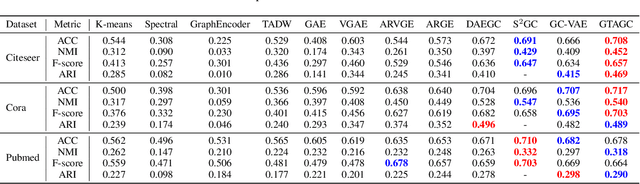
Graph Representation Learning (GRL) is an influential methodology, enabling a more profound understanding of graph-structured data and aiding graph clustering, a critical task across various domains. The recent incursion of attention mechanisms, originally an artifact of Natural Language Processing (NLP), into the realm of graph learning has spearheaded a notable shift in research trends. Consequently, Graph Attention Networks (GATs) and Graph Attention Auto-Encoders have emerged as preferred tools for graph clustering tasks. Yet, these methods primarily employ a local attention mechanism, thereby curbing their capacity to apprehend the intricate global dependencies between nodes within graphs. Addressing these impediments, this study introduces an innovative method known as the Graph Transformer Auto-Encoder for Graph Clustering (GTAGC). By melding the Graph Auto-Encoder with the Graph Transformer, GTAGC is adept at capturing global dependencies between nodes. This integration amplifies the graph representation and surmounts the constraints posed by the local attention mechanism. The architecture of GTAGC encompasses graph embedding, integration of the Graph Transformer within the autoencoder structure, and a clustering component. It strategically alternates between graph embedding and clustering, thereby tailoring the Graph Transformer for clustering tasks, whilst preserving the graph's global structural information. Through extensive experimentation on diverse benchmark datasets, GTAGC has exhibited superior performance against existing state-of-the-art graph clustering methodologies. This pioneering approach represents a novel contribution to the field of graph clustering, paving the way for promising avenues in future research.
Three-way causal attribute partial order structure analysis
Mar 29, 2023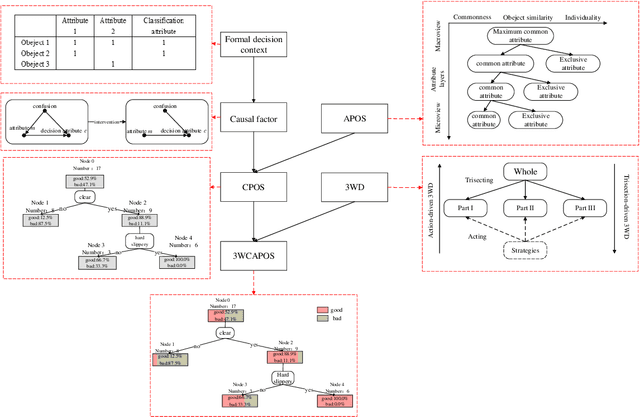
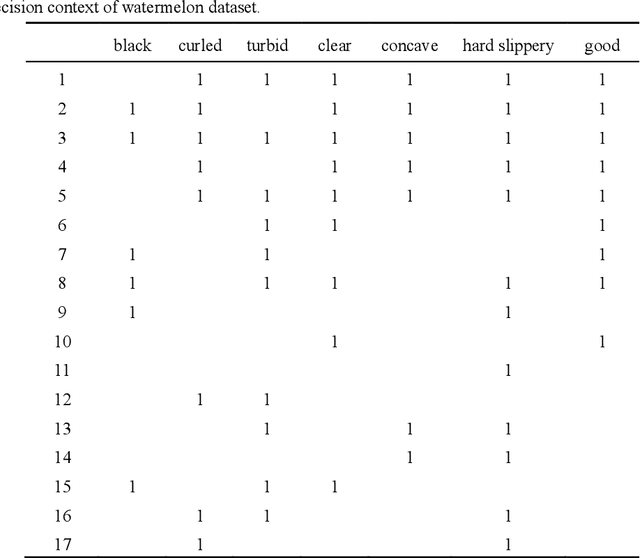
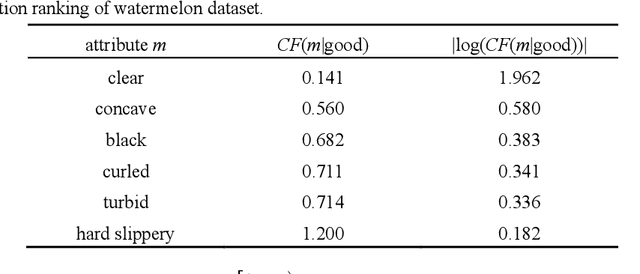
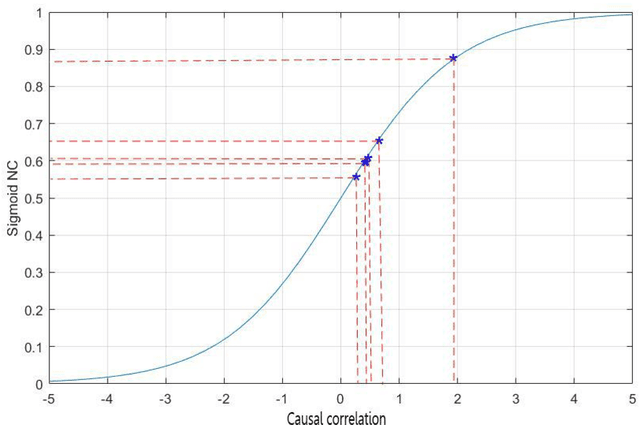
As an emerging concept cognitive learning model, partial order formal structure analysis (POFSA) has been widely used in the field of knowledge processing. In this paper, we propose the method named three-way causal attribute partial order structure (3WCAPOS) to evolve the POFSA from set coverage to causal coverage in order to increase the interpretability and classification performance of the model. First, the concept of causal factor (CF) is proposed to evaluate the causal correlation between attributes and decision attributes in the formal decision context. Then, combining CF with attribute partial order structure, the concept of causal attribute partial order structure is defined and makes set coverage evolve into causal coverage. Finally, combined with the idea of three-way decision, 3WCAPOS is formed, which makes the purity of nodes in the structure clearer and the changes between levels more obviously. In addition, the experiments are carried out from the classification ability and the interpretability of the structure through the six datasets. Through these experiments, it is concluded the accuracy of 3WCAPOS is improved by 1% - 9% compared with classification and regression tree, and more interpretable and the processing of knowledge is more reasonable compared with attribute partial order structure.
Significant Ties Graph Neural Networks for Continuous-Time Temporal Networks Modeling
Nov 12, 2022



Temporal networks are suitable for modeling complex evolving systems. It has a wide range of applications, such as social network analysis, recommender systems, and epidemiology. Recently, modeling such dynamic systems has drawn great attention in many domains. However, most existing approaches resort to taking discrete snapshots of the temporal networks and modeling all events with equal importance. This paper proposes Significant Ties Graph Neural Networks (STGNN), a novel framework that captures and describes significant ties. To better model the diversity of interactions, STGNN introduces a novel aggregation mechanism to organize the most significant historical neighbors' information and adaptively obtain the significance of node pairs. Experimental results on four real networks demonstrate the effectiveness of the proposed framework.
Self-Supervised Video Representation Using Pretext-Contrastive Learning
Oct 29, 2020

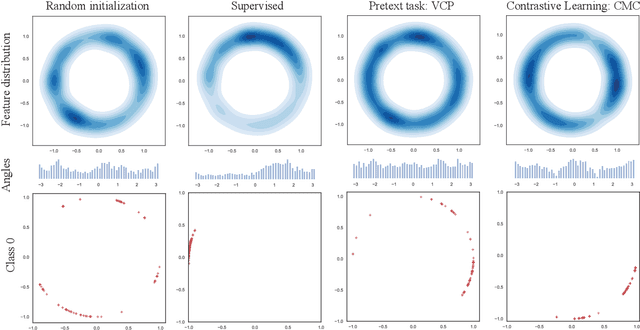
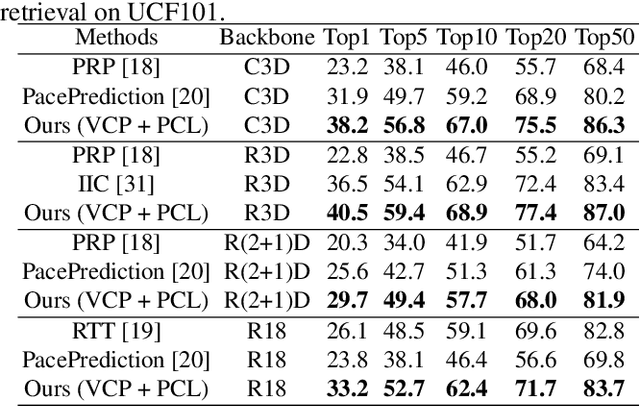
Pretext tasks and contrastive learning have been successful in self-supervised learning for video retrieval and recognition. In this study, we analyze their optimization targets and utilize the hyper-sphere feature space to explore the connections between them, indicating the compatibility and consistency of these two different learning methods. Based on the analysis, we propose a self-supervised training method, referred as Pretext-Contrastive Learning (PCL), to learn video representations. Extensive experiments based on different combinations of pretext task baselines and contrastive losses confirm the strong agreement with their self-supervised learning targets, demonstrating the effectiveness and the generality of PCL. The combination of pretext tasks and contrastive losses showed significant improvements in both video retrieval and recognition over the corresponding baselines. And we can also outperform current state-of-the-art methods in the same manner. Further, our PCL is flexible and can be applied to almost all existing pretext task methods.
Self-supervised Video Representation Learning Using Inter-intra Contrastive Framework
Aug 12, 2020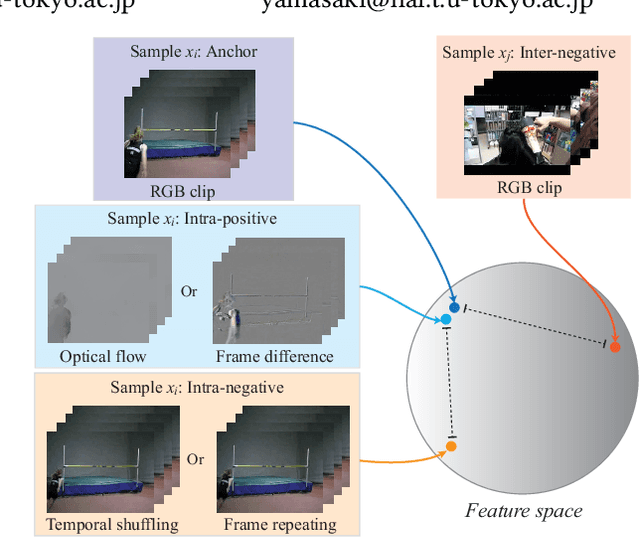

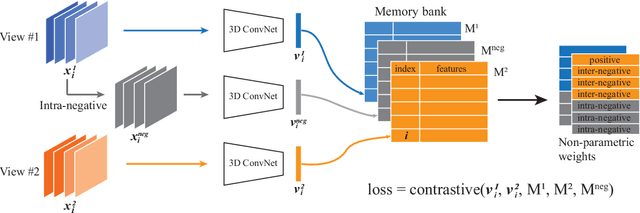
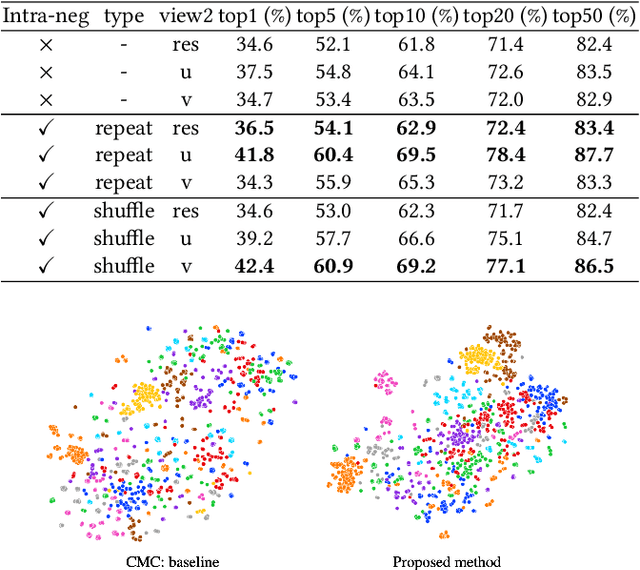
We propose a self-supervised method to learn feature representations from videos. A standard approach in traditional self-supervised methods uses positive-negative data pairs to train with contrastive learning strategy. In such a case, different modalities of the same video are treated as positives and video clips from a different video are treated as negatives. Because the spatio-temporal information is important for video representation, we extend the negative samples by introducing intra-negative samples, which are transformed from the same anchor video by breaking temporal relations in video clips. With the proposed Inter-Intra Contrastive (IIC) framework, we can train spatio-temporal convolutional networks to learn video representations. There are many flexible options in our IIC framework and we conduct experiments by using several different configurations. Evaluations are conducted on video retrieval and video recognition tasks using the learned video representation. Our proposed IIC outperforms current state-of-the-art results by a large margin, such as 16.7% and 9.5% points improvements in top-1 accuracy on UCF101 and HMDB51 datasets for video retrieval, respectively. For video recognition, improvements can also be obtained on these two benchmark datasets. Code is available at https://github.com/BestJuly/Inter-intra-video-contrastive-learning.