 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Representation Using Residual Frames with 3D CNN
Paper and Code
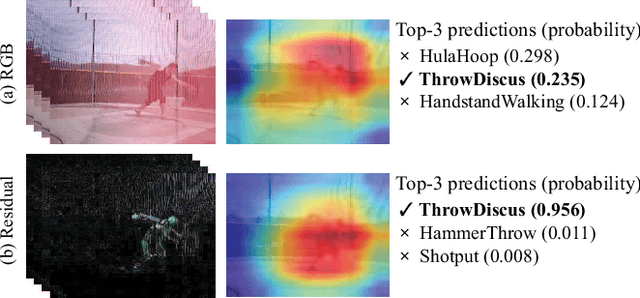
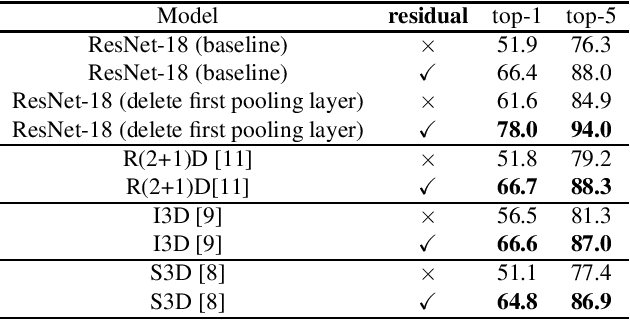


Recently, 3D convolutional networks (3D ConvNets) yield good performance in action recognition. However, optical flow stream is still needed to ensure better performance, the cost of which is very high. In this paper, we propose a fast but effective way to extract motion features from videos utilizing residual frames as the input data in 3D ConvNets. By replacing traditional stacked RGB frames with residual ones, 35.6% and 26.6% points improvements over top-1 accuracy can be obtained on the UCF101 and HMDB51 datasets when ResNet-18 models are trained from scratch. And we achieved the state-of-the-art results in this training mode. Analysis shows that better motion features can be extracted using residual frames compared to RGB counterpart. By combining with a simple appearance path, our proposal can be even better than some methods using optical flow streams.