 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Video Representation Using Pretext-Contrastive Learning
Paper and Code


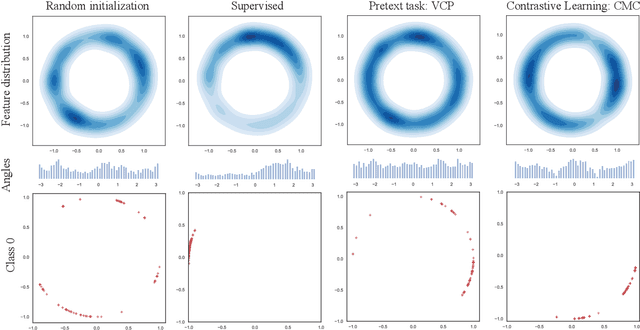
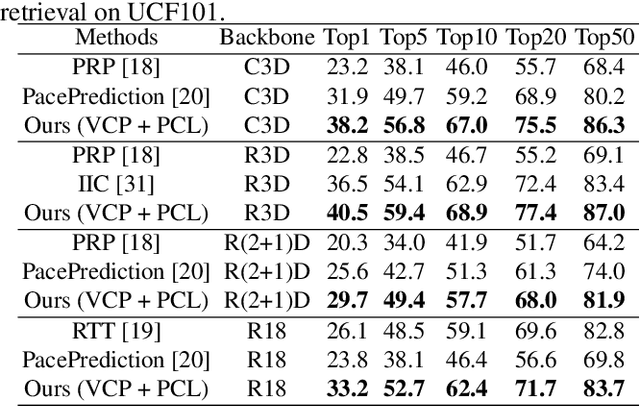
Pretext tasks and contrastive learning have been successful in self-supervised learning for video retrieval and recognition. In this study, we analyze their optimization targets and utilize the hyper-sphere feature space to explore the connections between them, indicating the compatibility and consistency of these two different learning methods. Based on the analysis, we propose a self-supervised training method, referred as Pretext-Contrastive Learning (PCL), to learn video representations. Extensive experiments based on different combinations of pretext task baselines and contrastive losses confirm the strong agreement with their self-supervised learning targets, demonstrating the effectiveness and the generality of PCL. The combination of pretext tasks and contrastive losses showed significant improvements in both video retrieval and recognition over the corresponding baselines. And we can also outperform current state-of-the-art methods in the same manner. Further, our PCL is flexible and can be applied to almost all existing pretext task methods.