 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Smart Contract Vulnerability Detection via Contrastive Learning-Enhanced Granular-ball Training
Mar 29, 2026Deep neural networks (DNNs) have emerged as a prominent approach for detecting smart contract vulnerabilities, driven by the growing contract datasets and advanced deep learning techniques. However, DNNs typically require large-scale labeled datasets to model the relationships between contract features and vulnerability labels. In practice, the labeling process often depends on existing open-sourced tools, whose accuracy cannot be guaranteed. Consequently, label noise poses a significant challenge for the accuracy and robustness of the smart contract, which is rarely explored in the literature. To this end, we propose Contrastive learning-enhanced Granular-Ball smart Contracts training, CGBC, to enhance the robustness of contract vulnerability detection. Specifically, CGBC first introduces a Granular-ball computing layer between the encoder layer and the classifier layer, to group similar contracts into Granular-Balls (GBs) and generate new coarse-grained representations (i.e., the center and the label of GBs) for them, which can correct noisy labels based on the most correct samples. An inter-GB compactness loss and an intra-GB looseness loss are combined to enhance the effectiveness of clustering. Then, to improve the accuracy of GBs, we pretrain the model through unsupervised contrastive learning supported by our novel semantic-consistent smart contract augmentation method. This procedure can discriminate contracts with different labels by dragging the representation of similar contracts closer, assisting CGBC in clustering. Subsequently, we leverage the symmetric cross-entropy loss function to measure the model quality, which can combat the label noise in gradient computations. Finally, extensive experiments show that the proposed CGBC can significantly improve the robustness and effectiveness of the smart contract vulnerability detection when contrasted with baselines.
From Representation to Clusters: A Contrastive Learning Approach for Attributed Hypergraph Clustering
Mar 10, 2026Contrastive learning has demonstrated strong performance in attributed hypergraph clustering. Typically, existing methods based on contrastive learning first learn node embeddings and then apply clustering algorithms, such as k-means, to these embeddings to obtain the clustering results.However, these methods lack direct clustering supervision, risking the inclusion of clustering-irrelevant information in the learned graph.To this end, we propose a Contrastive learning approach for Attributed Hypergraph Clustering (CAHC), an end-to-end method that simultaneously learns node embeddings and obtains clustering results. CAHC consists of two main steps: representation learning and cluster assignment learning. The former employs a novel contrastive learning approach that incorporates both node-level and hyperedge-level objectives to generate node embeddings.The latter joint embedding and clustering optimization to refine these embeddings by clustering-oriented guidance and obtains clustering results simultaneously.Extensive experimental results demonstrate that CAHC outperforms baselines on eight datasets.
Theoretically and Practically Efficient Resistance Distance Computation on Large Graphs
Jan 16, 2026The computation of resistance distance is pivotal in a wide range of graph analysis applications, including graph clustering, link prediction, and graph neural networks. Despite its foundational importance, efficient algorithms for computing resistance distances on large graphs are still lacking. Existing state-of-the-art (SOTA) methods, including power iteration-based algorithms and random walk-based local approaches, often struggle with slow convergence rates, particularly when the condition number of the graph Laplacian matrix, denoted by $κ$, is large. To tackle this challenge, we propose two novel and efficient algorithms inspired by the classic Lanczos method: Lanczos Iteration and Lanczos Push, both designed to reduce dependence on $κ$. Among them, Lanczos Iteration is a near-linear time global algorithm, whereas Lanczos Push is a local algorithm with a time complexity independent of the size of the graph. More specifically, we prove that the time complexity of Lanczos Iteration is $\tilde{O}(\sqrtκ m)$ ($m$ is the number of edges of the graph and $\tilde{O}$ means the complexity omitting the $\log$ terms) which achieves a speedup of $\sqrtκ$ compared to previous power iteration-based global methods. For Lanczos Push, we demonstrate that its time complexity is $\tilde{O}(κ^{2.75})$ under certain mild and frequently established assumptions, which represents a significant improvement of $κ^{0.25}$ over the SOTA random walk-based local algorithms. We validate our algorithms through extensive experiments on eight real-world datasets of varying sizes and statistical properties, demonstrating that Lanczos Iteration and Lanczos Push significantly outperform SOTA methods in terms of both efficiency and accuracy.
Scaling Up Graph Propagation Computation on Large Graphs: A Local Chebyshev Approximation Approach
Dec 14, 2024

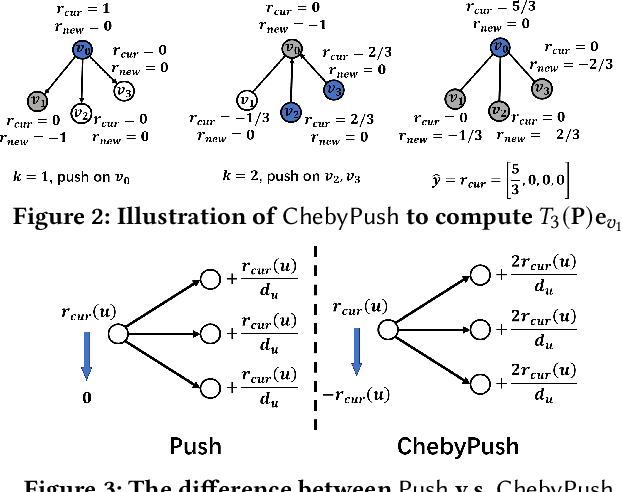

Graph propagation (GP) computation plays a crucial role in graph data analysis, supporting various applications such as graph node similarity queries, graph node ranking, graph clustering, and graph neural networks. Existing methods, mainly relying on power iteration or push computation frameworks, often face challenges with slow convergence rates when applied to large-scale graphs. To address this issue, we propose a novel and powerful approach that accelerates power iteration and push methods using Chebyshev polynomials. Specifically, we first present a novel Chebyshev expansion formula for general GP functions, offering a new perspective on GP computation and achieving accelerated convergence. Building on these theoretical insights, we develop a novel Chebyshev power iteration method (\ltwocheb) and a novel Chebyshev push method (\chebpush). Our \ltwocheb method demonstrates an approximate acceleration of $O(\sqrt{N})$ compared to existing power iteration techniques for both personalized PageRank and heat kernel PageRank computations, which are well-studied GP problems. For \chebpush, we propose an innovative subset Chebyshev recurrence technique, enabling the design of a push-style local algorithm with provable error guarantee and reduced time complexity compared to existing push methods. We conduct extensive experiments using 5 large real-world datasets to evaluate our proposed algorithms, demonstrating their superior efficiency compared to state-of-the-art approaches.
PSNE: Efficient Spectral Sparsification Algorithms for Scaling Network Embedding
Aug 05, 2024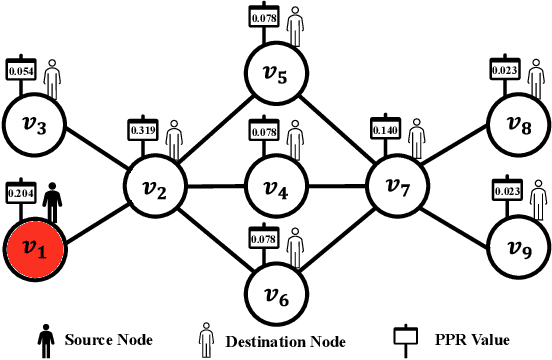

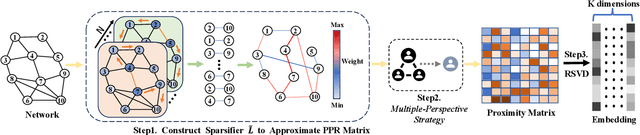
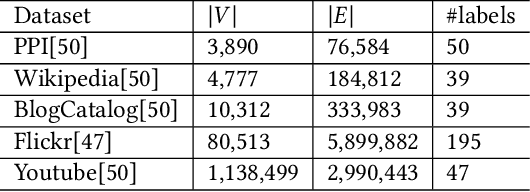
Network embedding has numerous practical applications and has received extensive attention in graph learning, which aims at mapping vertices into a low-dimensional and continuous dense vector space by preserving the underlying structural properties of the graph. Many network embedding methods have been proposed, among which factorization of the Personalized PageRank (PPR for short) matrix has been empirically and theoretically well supported recently. However, several fundamental issues cannot be addressed. (1) Existing methods invoke a seminal Local Push subroutine to approximate \textit{a single} row or column of the PPR matrix. Thus, they have to execute $n$ ($n$ is the number of nodes) Local Push subroutines to obtain a provable PPR matrix, resulting in prohibitively high computational costs for large $n$. (2) The PPR matrix has limited power in capturing the structural similarity between vertices, leading to performance degradation. To overcome these dilemmas, we propose PSNE, an efficient spectral s\textbf{P}arsification method for \textbf{S}caling \textbf{N}etwork \textbf{E}mbedding, which can fast obtain the embedding vectors that retain strong structural similarities. Specifically, PSNE first designs a matrix polynomial sparser to accelerate the calculation of the PPR matrix, which has a theoretical guarantee in terms of the Frobenius norm. Subsequently, PSNE proposes a simple but effective multiple-perspective strategy to enhance further the representation power of the obtained approximate PPR matrix. Finally, PSNE applies a randomized singular value decomposition algorithm on the sparse and multiple-perspective PPR matrix to get the target embedding vectors. Experimental evaluation of real-world and synthetic datasets shows that our solutions are indeed more efficient, effective, and scalable compared with ten competitors.
Scalable and Effective Conductance-based Graph Clustering
Nov 22, 2022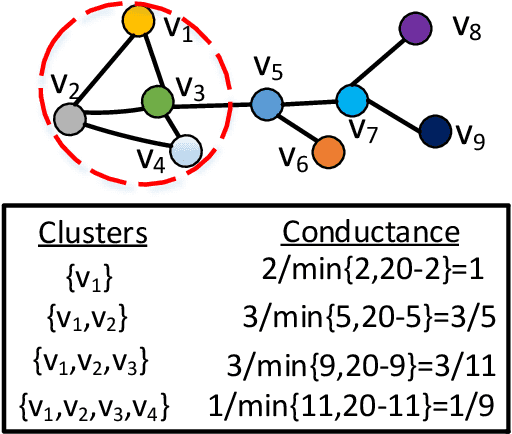

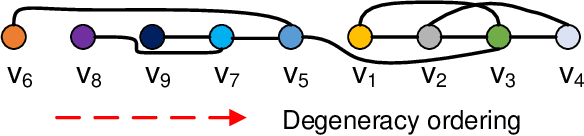
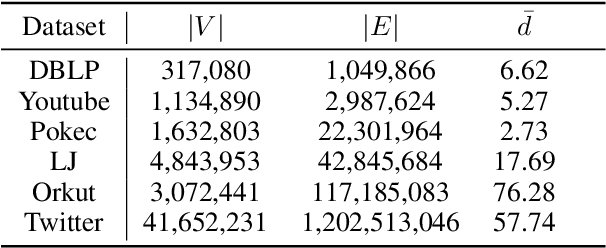
Conductance-based graph clustering has been recognized as a fundamental operator in numerous graph analysis applications. Despite the significant success of conductance-based graph clustering, existing algorithms are either hard to obtain satisfactory clustering qualities, or have high time and space complexity to achieve provable clustering qualities. To overcome these limitations, we devise a powerful \textit{peeling}-based graph clustering framework \textit{PCon}. We show that many existing solutions can be reduced to our framework. Namely, they first define a score function for each vertex, then iteratively remove the vertex with the smallest score. Finally, they output the result with the smallest conductance during the peeling process. Based on our framework, we propose two novel algorithms \textit{PCon\_core} and \emph{PCon\_de} with linear time and space complexity, which can efficiently and effectively identify clusters from massive graphs with more than a few billion edges. Surprisingly, we prove that \emph{PCon\_de} can identify clusters with near-constant approximation ratio, resulting in an important theoretical improvement over the well-known quadratic Cheeger bound. Empirical results on real-life and synthetic datasets show that our algorithms can achieve 5$\sim$42 times speedup with a high clustering accuracy, while using 1.4$\sim$7.8 times less memory than the baseline algorithms.