 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretically and Practically Efficient Resistance Distance Computation on Large Graphs
Jan 16, 2026The computation of resistance distance is pivotal in a wide range of graph analysis applications, including graph clustering, link prediction, and graph neural networks. Despite its foundational importance, efficient algorithms for computing resistance distances on large graphs are still lacking. Existing state-of-the-art (SOTA) methods, including power iteration-based algorithms and random walk-based local approaches, often struggle with slow convergence rates, particularly when the condition number of the graph Laplacian matrix, denoted by $κ$, is large. To tackle this challenge, we propose two novel and efficient algorithms inspired by the classic Lanczos method: Lanczos Iteration and Lanczos Push, both designed to reduce dependence on $κ$. Among them, Lanczos Iteration is a near-linear time global algorithm, whereas Lanczos Push is a local algorithm with a time complexity independent of the size of the graph. More specifically, we prove that the time complexity of Lanczos Iteration is $\tilde{O}(\sqrtκ m)$ ($m$ is the number of edges of the graph and $\tilde{O}$ means the complexity omitting the $\log$ terms) which achieves a speedup of $\sqrtκ$ compared to previous power iteration-based global methods. For Lanczos Push, we demonstrate that its time complexity is $\tilde{O}(κ^{2.75})$ under certain mild and frequently established assumptions, which represents a significant improvement of $κ^{0.25}$ over the SOTA random walk-based local algorithms. We validate our algorithms through extensive experiments on eight real-world datasets of varying sizes and statistical properties, demonstrating that Lanczos Iteration and Lanczos Push significantly outperform SOTA methods in terms of both efficiency and accuracy.
SAM 2++: Tracking Anything at Any Granularity
Oct 22, 2025Video tracking aims at finding the specific target in subsequent frames given its initial state. Due to the varying granularity of target states across different tasks, most existing trackers are tailored to a single task and heavily rely on custom-designed modules within the individual task, which limits their generalization and leads to redundancy in both model design and parameters. To unify video tracking tasks, we present SAM 2++, a unified model towards tracking at any granularity, including masks, boxes, and points. First, to extend target granularity, we design task-specific prompts to encode various task inputs into general prompt embeddings, and a unified decoder to unify diverse task results into a unified form pre-output. Next, to satisfy memory matching, the core operation of tracking, we introduce a task-adaptive memory mechanism that unifies memory across different granularities. Finally, we introduce a customized data engine to support tracking training at any granularity, producing a large and diverse video tracking dataset with rich annotations at three granularities, termed Tracking-Any-Granularity, which represents a comprehensive resource for training and benchmarking on unified tracking. Comprehensive experiments on multiple benchmarks confirm that SAM 2++ sets a new state of the art across diverse tracking tasks at different granularities, establishing a unified and robust tracking framework.
Fine-grained Video-Text Retrieval: A New Benchmark and Method
Dec 31, 2024



The ability of perceiving fine-grained spatial and temporal information is crucial for video-language retrieval. However, the existing video retrieval benchmarks, such as MSRVTT and MSVD, fail to efficiently evaluate the fine-grained retrieval ability of video-language models (VLMs) due to a lack of detailed annotations. To address this problem, we present FIBER, a FIne-grained BEnchmark for text to video Retrieval, containing 1,000 videos sourced from the FineAction dataset. Uniquely, our FIBER benchmark provides detailed human-annotated spatial annotations and temporal annotations for each video, making it possible to independently evaluate the spatial and temporal bias of VLMs on video retrieval task. Besides, we employ a text embedding method to unlock the capability of fine-grained video-language understanding of Multimodal Large Language Models (MLLMs). Surprisingly, the experiment results show that our Video Large Language Encoder (VLLE) performs comparably to CLIP-based models on traditional benchmarks and has a stronger capability of fine-grained representation with lower spatial-temporal bias. Project page: https://fiber-bench.github.io.
Scaling Up Graph Propagation Computation on Large Graphs: A Local Chebyshev Approximation Approach
Dec 14, 2024

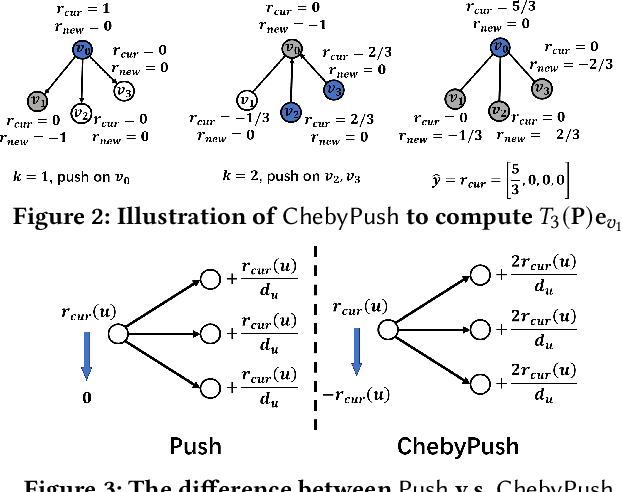

Graph propagation (GP) computation plays a crucial role in graph data analysis, supporting various applications such as graph node similarity queries, graph node ranking, graph clustering, and graph neural networks. Existing methods, mainly relying on power iteration or push computation frameworks, often face challenges with slow convergence rates when applied to large-scale graphs. To address this issue, we propose a novel and powerful approach that accelerates power iteration and push methods using Chebyshev polynomials. Specifically, we first present a novel Chebyshev expansion formula for general GP functions, offering a new perspective on GP computation and achieving accelerated convergence. Building on these theoretical insights, we develop a novel Chebyshev power iteration method (\ltwocheb) and a novel Chebyshev push method (\chebpush). Our \ltwocheb method demonstrates an approximate acceleration of $O(\sqrt{N})$ compared to existing power iteration techniques for both personalized PageRank and heat kernel PageRank computations, which are well-studied GP problems. For \chebpush, we propose an innovative subset Chebyshev recurrence technique, enabling the design of a push-style local algorithm with provable error guarantee and reduced time complexity compared to existing push methods. We conduct extensive experiments using 5 large real-world datasets to evaluate our proposed algorithms, demonstrating their superior efficiency compared to state-of-the-art approaches.
SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes
Apr 13, 2023Multi-object tracking in sports scenes plays a critical role in gathering players statistics, supporting further analysis, such as automatic tactical analysis. Yet existing MOT benchmarks cast little attention on the domain, limiting its development. In this work, we present a new large-scale multi-object tracking dataset in diverse sports scenes, coined as \emph{SportsMOT}, where all players on the court are supposed to be tracked. It consists of 240 video sequences, over 150K frames (almost 15\times MOT17) and over 1.6M bounding boxes (3\times MOT17) collected from 3 sports categories, including basketball, volleyball and football. Our dataset is characterized with two key properties: 1) fast and variable-speed motion and 2) similar yet distinguishable appearance. We expect SportsMOT to encourage the MOT trackers to promote in both motion-based association and appearance-based association. We benchmark several state-of-the-art trackers and reveal the key challenge of SportsMOT lies in object association. To alleviate the issue, we further propose a new multi-object tracking framework, termed as \emph{MixSort}, introducing a MixFormer-like structure as an auxiliary association model to prevailing tracking-by-detection trackers. By integrating the customized appearance-based association with the original motion-based association, MixSort achieves state-of-the-art performance on SportsMOT and MOT17. Based on MixSort, we give an in-depth analysis and provide some profound insights into SportsMOT. The dataset and code will be available at https://deeperaction.github.io/datasets/sportsmot.html.