 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Subgraph Matching by Combining Algorithms and Graph Neural Networks
Jul 27, 2025Homomorphism is a key mapping technique between graphs that preserves their structure. Given a graph and a pattern, the subgraph homomorphism problem involves finding a mapping from the pattern to the graph, ensuring that adjacent vertices in the pattern are mapped to adjacent vertices in the graph. Unlike subgraph isomorphism, which requires a one-to-one mapping, homomorphism allows multiple vertices in the pattern to map to the same vertex in the graph, making it more complex. We propose HFrame, the first graph neural network-based framework for subgraph homomorphism, which integrates traditional algorithms with machine learning techniques. We demonstrate that HFrame outperforms standard graph neural networks by being able to distinguish more graph pairs where the pattern is not homomorphic to the graph. Additionally, we provide a generalization error bound for HFrame. Through experiments on both real-world and synthetic graphs, we show that HFrame is up to 101.91 times faster than exact matching algorithms and achieves an average accuracy of 0.962.
A performance characteristic curve for model evaluation: the application in information diffusion prediction
Sep 19, 2023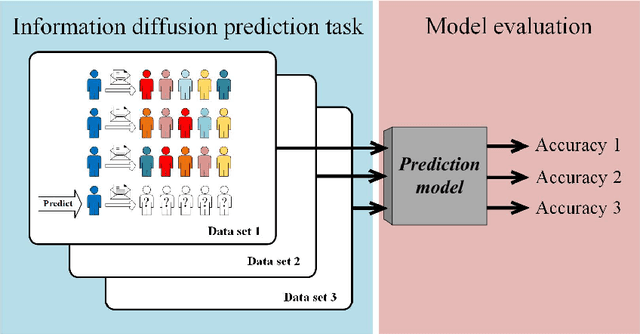



The information diffusion prediction on social networks aims to predict future recipients of a message, with practical applications in marketing and social media. While different prediction models all claim to perform well, general frameworks for performance evaluation remain limited. Here, we aim to identify a performance characteristic curve for a model, which captures its performance on tasks of different complexity. We propose a metric based on information entropy to quantify the randomness in diffusion data, then identify a scaling pattern between the randomness and the prediction accuracy of the model. Data points in the patterns by different sequence lengths, system sizes, and randomness all collapse into a single curve, capturing a model's inherent capability of making correct predictions against increased uncertainty. Given that this curve has such important properties that it can be used to evaluate the model, we define it as the performance characteristic curve of the model. The validity of the curve is tested by three prediction models in the same family, reaching conclusions in line with existing studies. Also, the curve is successfully applied to evaluate two distinct models from the literature. Our work reveals a pattern underlying the data randomness and prediction accuracy. The performance characteristic curve provides a new way to systematically evaluate models' performance, and sheds light on future studies on other frameworks for model evaluation.
Author Name Disambiguation via Heterogeneous Network Embedding from Structural and Semantic Perspectives
Dec 24, 2022Name ambiguity is common in academic digital libraries, such as multiple authors having the same name. This creates challenges for academic data management and analysis, thus name disambiguation becomes necessary. The procedure of name disambiguation is to divide publications with the same name into different groups, each group belonging to a unique author. A large amount of attribute information in publications makes traditional methods fall into the quagmire of feature selection. These methods always select attributes artificially and equally, which usually causes a negative impact on accuracy. The proposed method is mainly based on representation learning for heterogeneous networks and clustering and exploits the self-attention technology to solve the problem. The presentation of publications is a synthesis of structural and semantic representations. The structural representation is obtained by meta-path-based sampling and a skip-gram-based embedding method, and meta-path level attention is introduced to automatically learn the weight of each feature. The semantic representation is generated using NLP tools. Our proposal performs better in terms of name disambiguation accuracy compared with baselines and the ablation experiments demonstrate the improvement by feature selection and the meta-path level attention in our method. The experimental results show the superiority of our new method for capturing the most attributes from publications and reducing the impact of redundant information.
Independent Asymmetric Embedding Model for Cascade Prediction on Social Network
May 18, 2021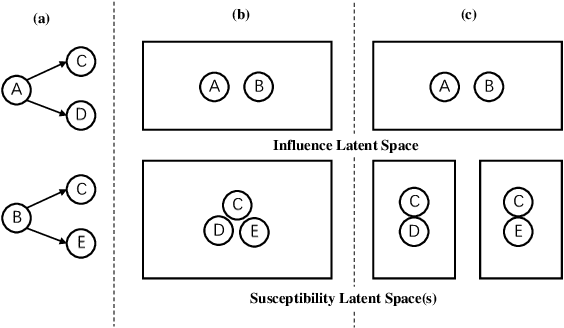
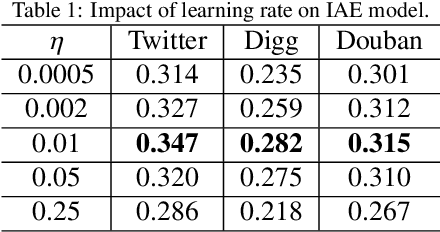
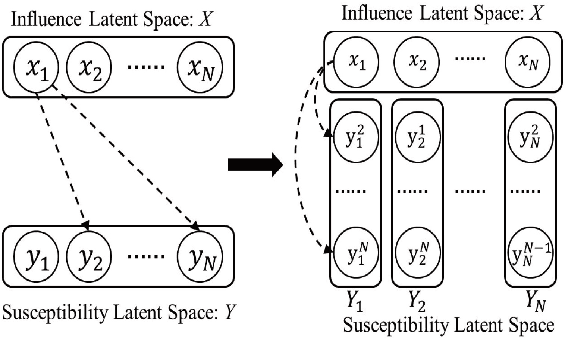
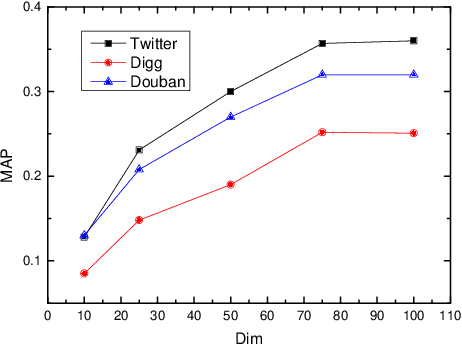
The prediction for information diffusion on social networks has great practical significance in marketing and public opinion control. Cascade prediction aims to predict the individuals who will potentially repost the message on the social network. One kind of methods either exploit demographical, structural, and temporal features for prediction, or explicitly rely on particular information diffusion models. The other kind of models are fully data-driven and do not require a global network structure. Thus massive diffusion prediction models based on network embedding are proposed. These models embed the users into the latent space using their cascade information, but are lack of consideration for the intervene among users when embedding. In this paper, we propose an independent asymmetric embedding method to learn social embedding for cascade prediction. Different from existing methods, our method embeds each individual into one latent influence space and multiple latent susceptibility spaces. Furthermore, our method captures the co-occurrence regulation of user combination in cascades to improve the calculating effectiveness. The results of extensive experiments conducted on real-world datasets verify both the predictive accuracy and cost-effectiveness of our approach.