 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA performance characteristic curve for model evaluation: the application in information diffusion prediction
Sep 19, 2023



The information diffusion prediction on social networks aims to predict future recipients of a message, with practical applications in marketing and social media. While different prediction models all claim to perform well, general frameworks for performance evaluation remain limited. Here, we aim to identify a performance characteristic curve for a model, which captures its performance on tasks of different complexity. We propose a metric based on information entropy to quantify the randomness in diffusion data, then identify a scaling pattern between the randomness and the prediction accuracy of the model. Data points in the patterns by different sequence lengths, system sizes, and randomness all collapse into a single curve, capturing a model's inherent capability of making correct predictions against increased uncertainty. Given that this curve has such important properties that it can be used to evaluate the model, we define it as the performance characteristic curve of the model. The validity of the curve is tested by three prediction models in the same family, reaching conclusions in line with existing studies. Also, the curve is successfully applied to evaluate two distinct models from the literature. Our work reveals a pattern underlying the data randomness and prediction accuracy. The performance characteristic curve provides a new way to systematically evaluate models' performance, and sheds light on future studies on other frameworks for model evaluation.
Combining Machine Learning and Social Network Analysis to Reveal the Organizational Structures
Jun 23, 2019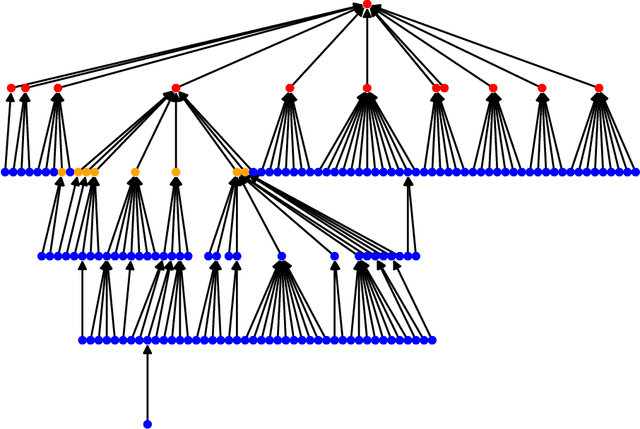


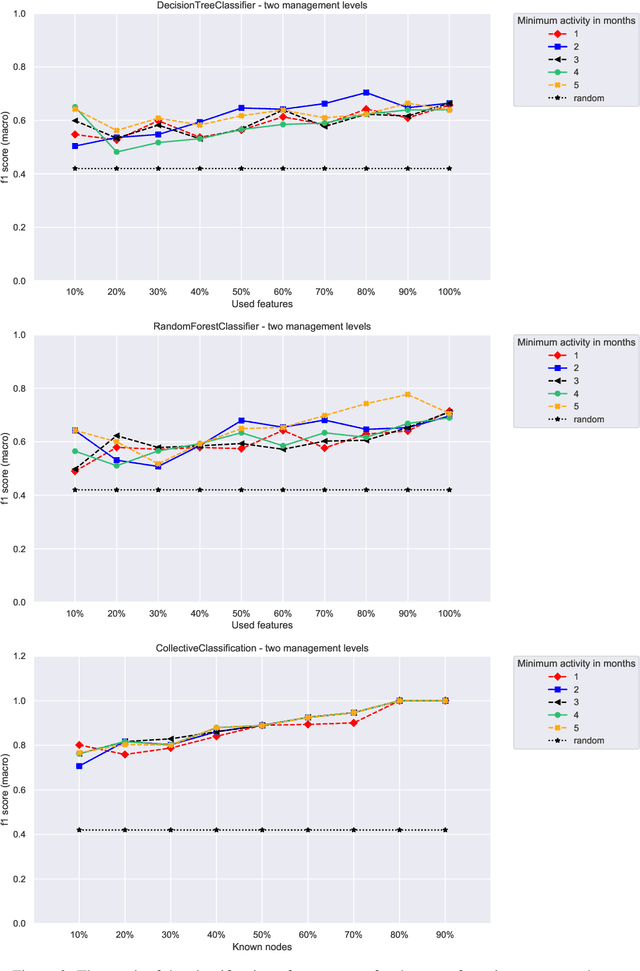
Formation of a hierarchy within an organization is a natural way of optimizing the duties, responsibilities and flow of information. Only for the smallest organizations the lack of the hierarchy is possible, yet, if they grow, its appearance is inevitable. Most often, its existence results in a different nature of the tasks and duties of its members located at different organizational levels. On the other hand, employees often send dozens of emails each day, and by doing so, and also by being engaged in other activities, they naturally form an informal social network where nodes are individuals and edges are the actions linking them. At first, such a social network may seem distinct from the organizational one. However, the analysis of this network may lead to reproducing the organizational hierarchy of companies. This is due to the fact that that people holding a similar position in the hierarchy can possibly share also a similar way of behaving and communicating attributed to their role. The key concept of this work is to evaluate how well social network measures when combined with other features gained from the feature engineering align with the classification of the members of organizational social network. As a technique for answering the research question, machine learning apparatus was employed. Here, for the classification task, Decision Tree and Random Forest algorithms where used, as well as a simple collective classification algorithm, which is also proposed in this paper. The used approach allowed to compare how traditional methods of machine learning classification, while supported by social network analysis, performed in comparison to a typical graph algorithm.
Learning in Unlabeled Networks - An Active Learning and Inference Approach
Oct 05, 2015

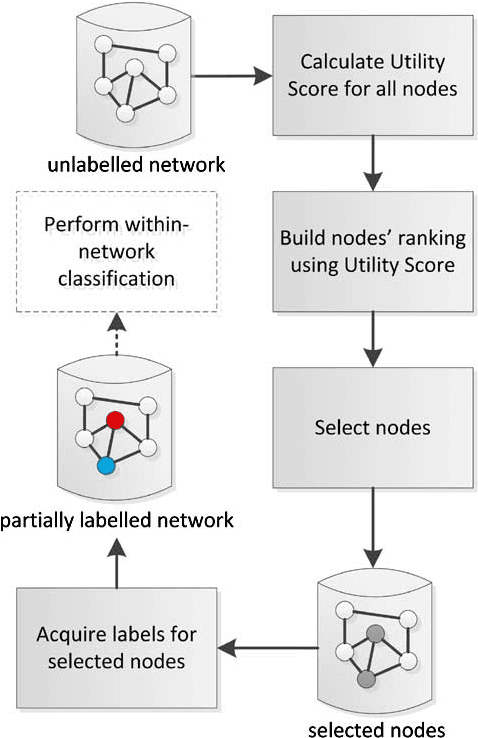
The task of determining labels of all network nodes based on the knowledge about network structure and labels of some training subset of nodes is called the within-network classification. It may happen that none of the labels of the nodes is known and additionally there is no information about number of classes to which nodes can be assigned. In such a case a subset of nodes has to be selected for initial label acquisition. The question that arises is: "labels of which nodes should be collected and used for learning in order to provide the best classification accuracy for the whole network?". Active learning and inference is a practical framework to study this problem. A set of methods for active learning and inference for within network classification is proposed and validated. The utility score calculation for each node based on network structure is the first step in the process. The scores enable to rank the nodes. Based on the ranking, a set of nodes, for which the labels are acquired, is selected (e.g. by taking top or bottom N from the ranking). The new measure-neighbour methods proposed in the paper suggest not obtaining labels of nodes from the ranking but rather acquiring labels of their neighbours. The paper examines 29 distinct formulations of utility score and selection methods reporting their impact on the results of two collective classification algorithms: Iterative Classification Algorithm and Loopy Belief Propagation. We advocate that the accuracy of presented methods depends on the structural properties of the examined network. We claim that measure-neighbour methods will work better than the regular methods for networks with higher clustering coefficient and worse than regular methods for networks with low clustering coefficient. According to our hypothesis, based on clustering coefficient we are able to recommend appropriate active learning and inference method.