 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Unlabeled Networks - An Active Learning and Inference Approach
Paper and Code
Oct 05, 2015

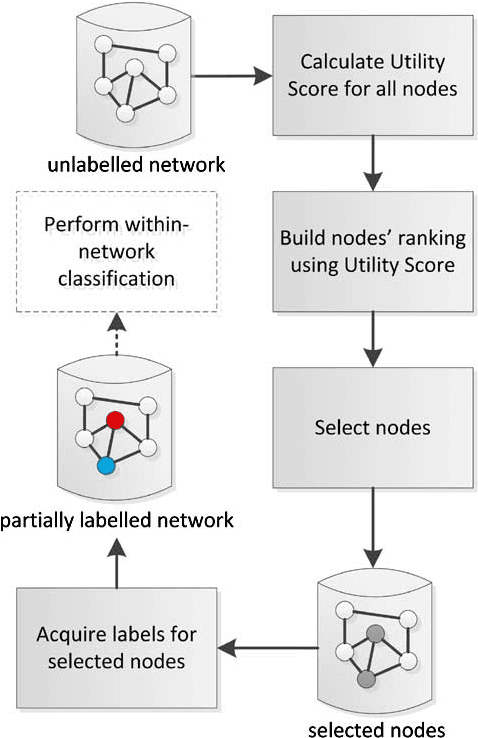
The task of determining labels of all network nodes based on the knowledge about network structure and labels of some training subset of nodes is called the within-network classification. It may happen that none of the labels of the nodes is known and additionally there is no information about number of classes to which nodes can be assigned. In such a case a subset of nodes has to be selected for initial label acquisition. The question that arises is: "labels of which nodes should be collected and used for learning in order to provide the best classification accuracy for the whole network?". Active learning and inference is a practical framework to study this problem. A set of methods for active learning and inference for within network classification is proposed and validated. The utility score calculation for each node based on network structure is the first step in the process. The scores enable to rank the nodes. Based on the ranking, a set of nodes, for which the labels are acquired, is selected (e.g. by taking top or bottom N from the ranking). The new measure-neighbour methods proposed in the paper suggest not obtaining labels of nodes from the ranking but rather acquiring labels of their neighbours. The paper examines 29 distinct formulations of utility score and selection methods reporting their impact on the results of two collective classification algorithms: Iterative Classification Algorithm and Loopy Belief Propagation. We advocate that the accuracy of presented methods depends on the structural properties of the examined network. We claim that measure-neighbour methods will work better than the regular methods for networks with higher clustering coefficient and worse than regular methods for networks with low clustering coefficient. According to our hypothesis, based on clustering coefficient we are able to recommend appropriate active learning and inference method.