 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAR: Named Entity and Attribute Recognition of clinical concepts
Aug 30, 2022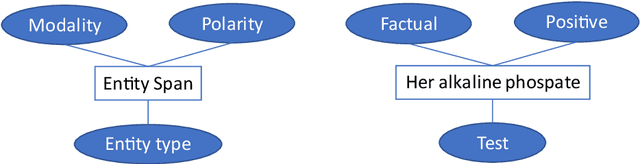

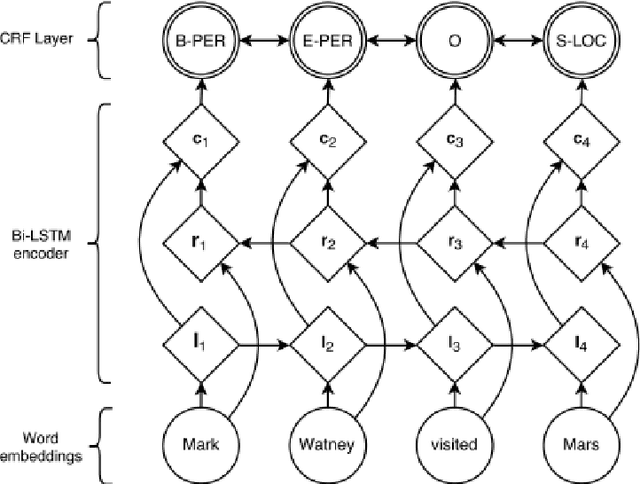
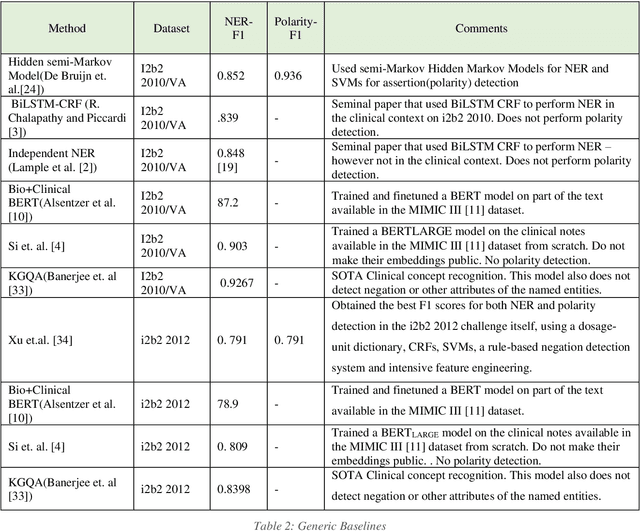
Named Entity Recognition (NER) or the extraction of concepts from clinical text is the task of identifying entities in text and slotting them into categories such as problems, treatments, tests, clinical departments, occurrences (such as admission and discharge) and others. NER forms a critical component of processing and leveraging unstructured data from Electronic Health Records (EHR). While identifying the spans and categories of concepts is itself a challenging task, these entities could also have attributes such as negation that pivot their meanings implied to the consumers of the named entities. There has been little research dedicated to identifying the entities and their qualifying attributes together. This research hopes to contribute to the area of detecting entities and their corresponding attributes by modelling the NER task as a supervised, multi-label tagging problem with each of the attributes assigned tagging sequence labels. In this paper, we propose 3 architectures to achieve this multi-label entity tagging: BiLSTM n-CRF, BiLSTM-CRF-Smax-TF and BiLSTM n-CRF-TF. We evaluate these methods on the 2010 i2b2/VA and the i2b2 2012 shared task datasets. Our different models obtain best NER F1 scores of 0. 894 and 0.808 on the i2b2 2010/VA and i2b2 2012 respectively. The highest span based micro-averaged F1 polarity scores obtained were 0.832 and 0.836 on the i2b2 2010/VA and i2b2 2012 datasets respectively, and the highest macro-averaged F1 polarity scores obtained were 0.924 and 0.888 respectively. The modality studies conducted on i2b2 2012 dataset revealed high scores of 0.818 and 0.501 for span based micro-averaged F1 and macro-averaged F1 respectively.
* 11 pages, 7 figures, 9 tables