 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the 'extreme learning machine' algorithm
Jul 22, 2015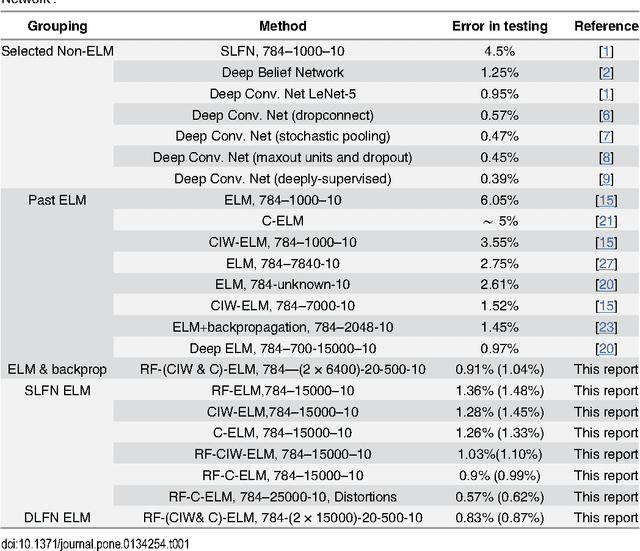
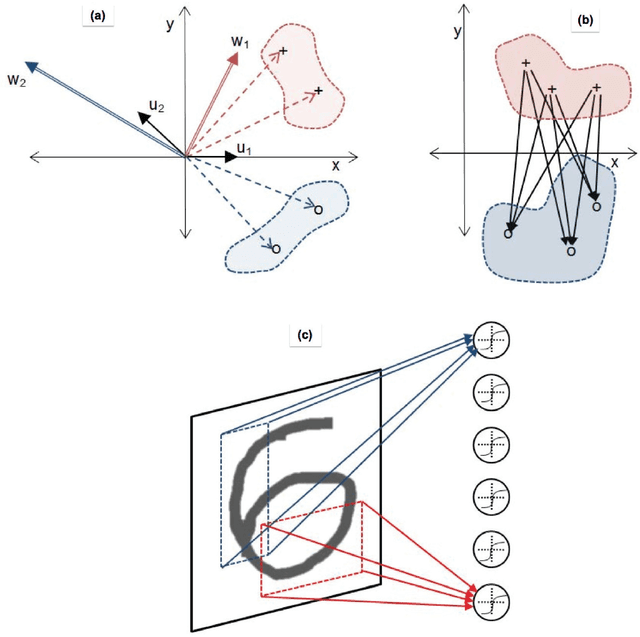
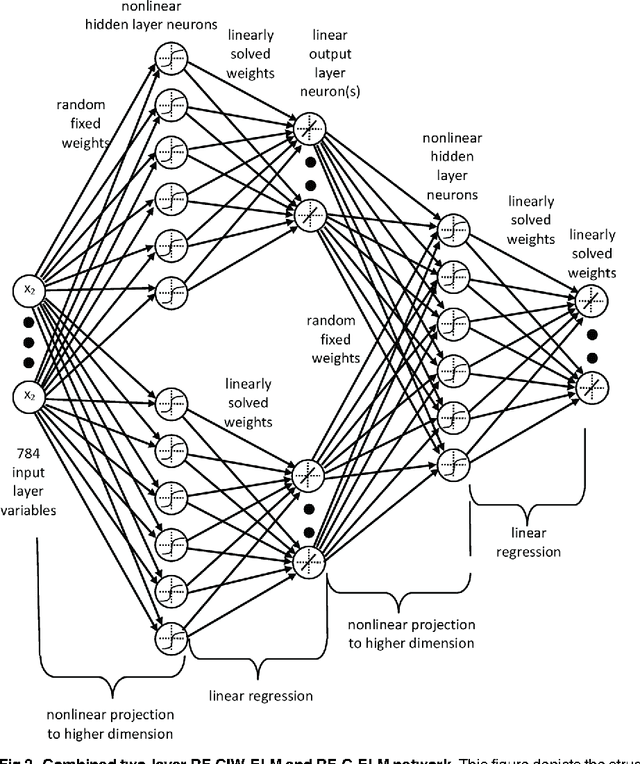
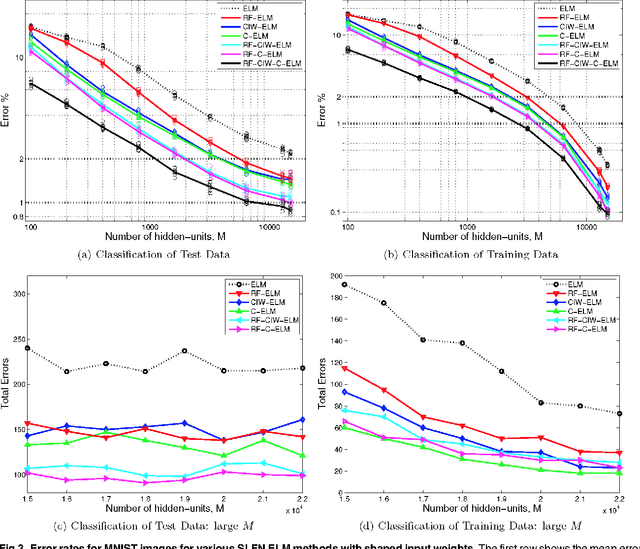
Recent advances in training deep (multi-layer) architectures have inspired a renaissance in neural network use. For example, deep convolutional networks are becoming the default option for difficult tasks on large datasets, such as image and speech recognition. However, here we show that error rates below 1% on the MNIST handwritten digit benchmark can be replicated with shallow non-convolutional neural networks. This is achieved by training such networks using the 'Extreme Learning Machine' (ELM) approach, which also enables a very rapid training time (~10 minutes). Adding distortions, as is common practise for MNIST, reduces error rates even further. Our methods are also shown to be capable of achieving less than 5.5% error rates on the NORB image database. To achieve these results, we introduce several enhancements to the standard ELM algorithm, which individually and in combination can significantly improve performance. The main innovation is to ensure each hidden-unit operates only on a randomly sized and positioned patch of each image. This form of random `receptive field' sampling of the input ensures the input weight matrix is sparse, with about 90% of weights equal to zero. Furthermore, combining our methods with a small number of iterations of a single-batch backpropagation method can significantly reduce the number of hidden-units required to achieve a particular performance. Our close to state-of-the-art results for MNIST and NORB suggest that the ease of use and accuracy of the ELM algorithm for designing a single-hidden-layer neural network classifier should cause it to be given greater consideration either as a standalone method for simpler problems, or as the final classification stage in deep neural networks applied to more difficult problems.