 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-time learning in a biologically-inspired Salience-affected Artificial Neural Network
Aug 23, 2019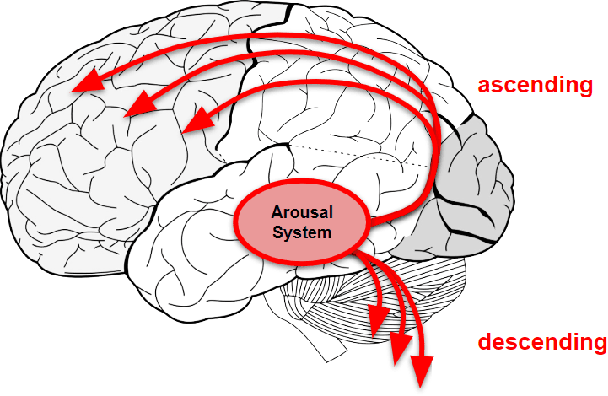
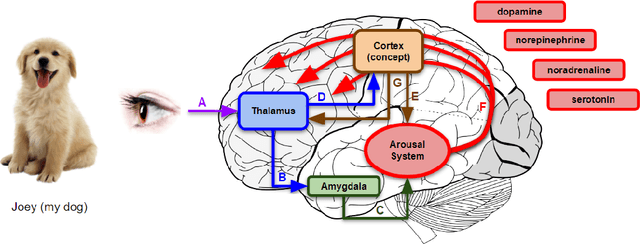
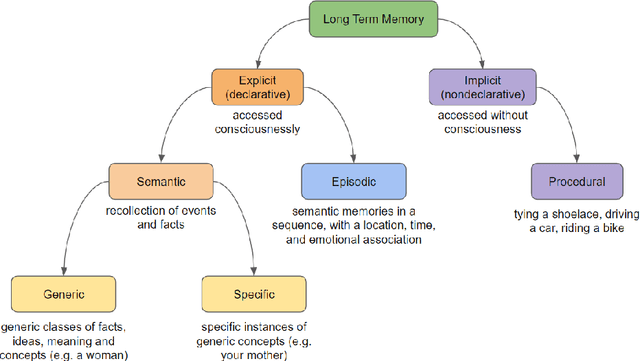
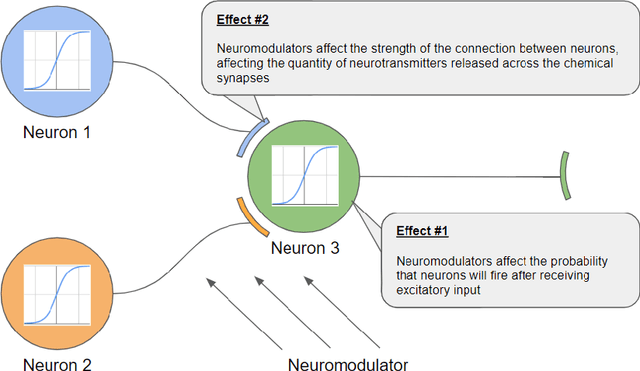
Standard artificial neural networks (ANNs), loosely based on the structure of columns in the cortex, model key cognitive aspects of brain function such as learning and classification, but do not model the affective (emotional) aspects of brain function. However these are a key feature of the brain (the associated `ascending systems' have been hard-wired into the brain by evolutionary processes). These emotions are associated with memories when neuromodulators such as dopamine and noradrenaline affect entire patterns of synaptically activated neurons. Here we present a bio-inspired ANN architecture which we call a Salience-Affected Neural Network (SANN), which, at the same time as local network processing of task-specific information, includes non-local salience (significance) effects responding to an input salience signal. During pattern recognition, inputs similar to the salience-affected inputs in the training data will produce reverse salience signals corresponding to those experienced when the memories were laid down. In addition, training with salience affects the weights of connections between nodes, and improves the overall accuracy of a classification of images similar to the salience-tagged input after just a single iteration of training. Note that we are not aiming to present an accurate model of the biological salience system; rather we present an artificial neural network inspired by those biological systems in the human brain, that has unique strengths.
Event-based Feature Extraction Using Adaptive Selection Thresholds
Jul 30, 2019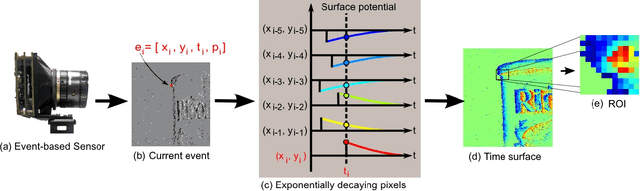
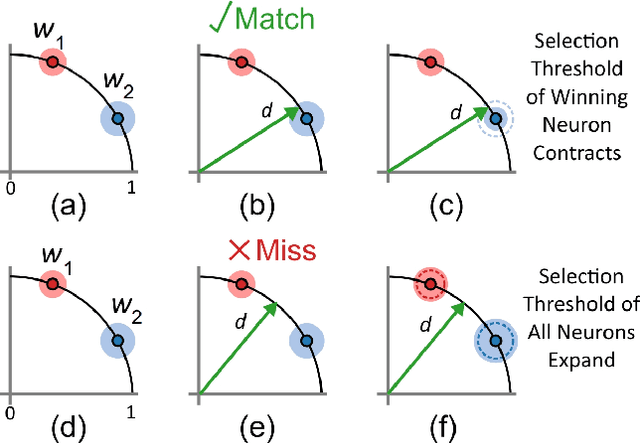
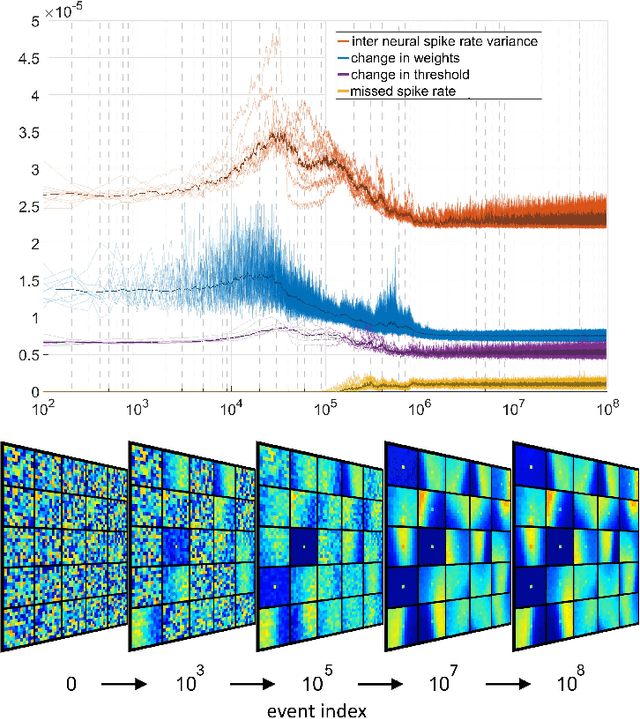
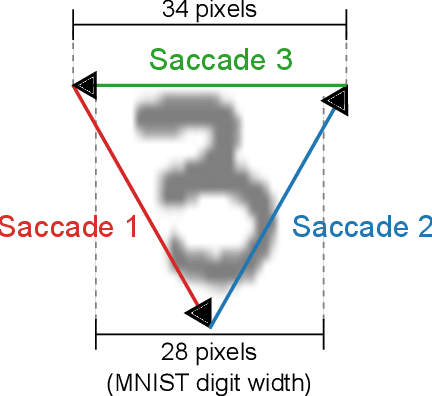
Unsupervised feature extraction algorithms form one of the most important building blocks in machine learning systems. These algorithms are often adapted to the event-based domain to perform online learning in neuromorphic hardware. However, not designed for the purpose, such algorithms typically require significant simplification during implementation to meet hardware constraints, creating trade offs with performance. Furthermore, conventional feature extraction algorithms are not designed to generate useful intermediary signals which are valuable only in the context of neuromorphic hardware limitations. In this work a novel event-based feature extraction method is proposed that focuses on these issues. The algorithm operates via simple adaptive selection thresholds which allow a simpler implementation of network homeostasis than previous works by trading off a small amount of information loss in the form of missed events that fall outside the selection thresholds. The behavior of the selection thresholds and the output of the network as a whole are shown to provide uniquely useful signals indicating network weight convergence without the need to access network weights. A novel heuristic method for network size selection is proposed which makes use of noise events and their feature representations. The use of selection thresholds is shown to produce network activation patterns that predict classification accuracy allowing rapid evaluation and optimization of system parameters without the need to run back-end classifiers. The feature extraction method is tested on both the N-MNIST benchmarking dataset and a dataset of airplanes passing through the field of view. Multiple configurations with different classifiers are tested with the results quantifying the resultant performance gains at each processing stage.
Investigation of event-based memory surfaces for high-speed tracking, unsupervised feature extraction and object recognition
Nov 08, 2017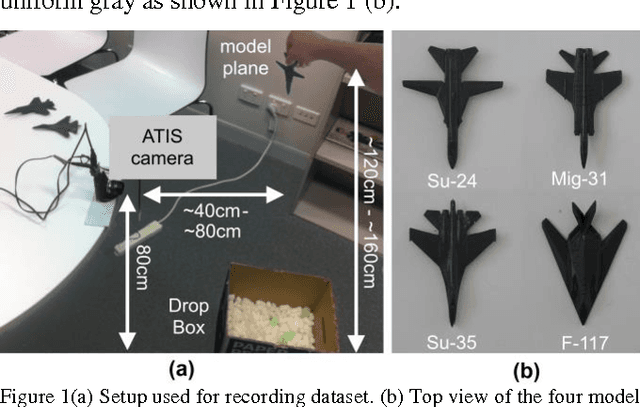
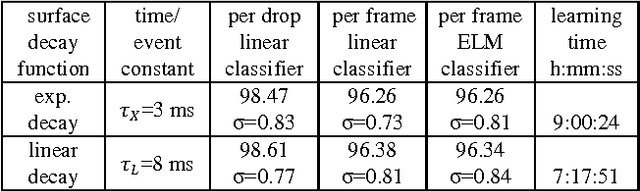

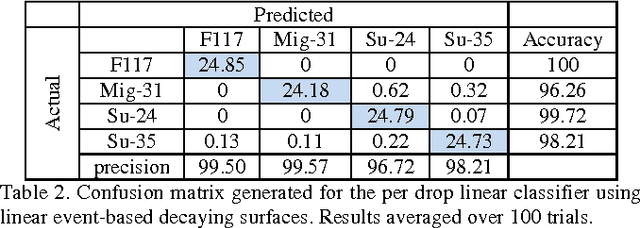
In this paper we compare event-based decaying and time based-decaying memory surfaces for high-speed eventbased tracking, feature extraction, and object classification using an event-based camera. The high-speed recognition task involves detecting and classifying model airplanes that are dropped free-hand close to the camera lens so as to generate a challenging dataset exhibiting significant variance in target velocity. This variance motivated the investigation of event-based decaying memory surfaces in comparison to time-based decaying memory surfaces to capture the temporal aspect of the event-based data. These surfaces are then used to perform unsupervised feature extraction, tracking and recognition. In order to generate the memory surfaces, event binning, linearly decaying kernels, and exponentially decaying kernels were investigated with exponentially decaying kernels found to perform best. Event-based decaying memory surfaces were found to outperform time-based decaying memory surfaces in recognition especially when invariance to target velocity was made a requirement. A range of network and receptive field sizes were investigated. The system achieves 98.75% recognition accuracy within 156 milliseconds of an airplane entering the field of view, using only twenty-five event-based feature extracting neurons in series with a linear classifier. By comparing the linear classifier results to an ELM classifier, we find that a small number of event-based feature extractors can effectively project the complex spatio-temporal event patterns of the dataset to an almost linearly separable representation in feature space.
An Online Learning Algorithm for Neuromorphic Hardware Implementation
Jul 30, 2017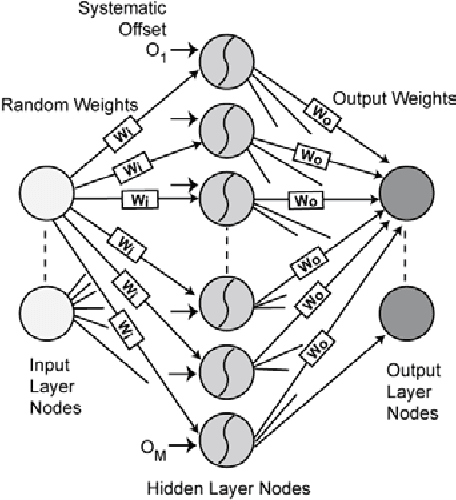

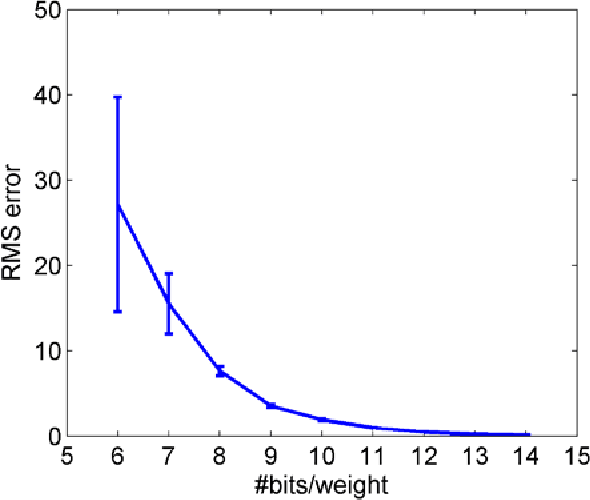

We propose a sign-based online learning (SOL) algorithm for a neuromorphic hardware framework called Trainable Analogue Block (TAB). The TAB framework utilises the principles of neural population coding, implying that it encodes the input stimulus using a large pool of nonlinear neurons. The SOL algorithm is a simple weight update rule that employs the sign of the hidden layer activation and the sign of the output error, which is the difference between the target output and the predicted output. The SOL algorithm is easily implementable in hardware, and can be used in any artificial neural network framework that learns weights by minimising a convex cost function. We show that the TAB framework can be trained for various regression tasks using the SOL algorithm.
EMNIST: an extension of MNIST to handwritten letters
Mar 01, 2017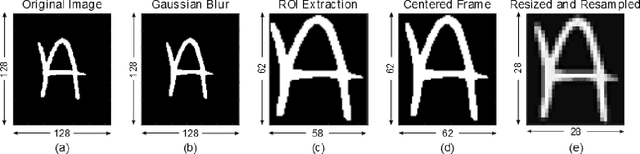

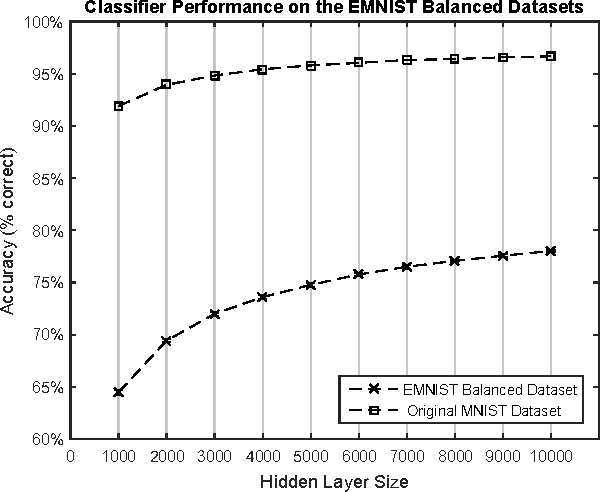
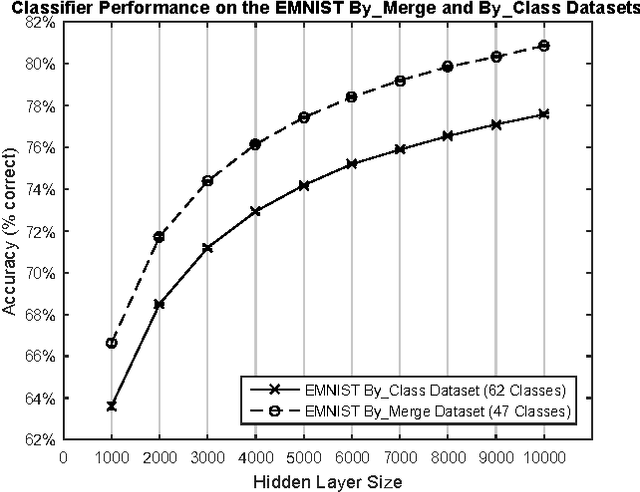
The MNIST dataset has become a standard benchmark for learning, classification and computer vision systems. Contributing to its widespread adoption are the understandable and intuitive nature of the task, its relatively small size and storage requirements and the accessibility and ease-of-use of the database itself. The MNIST database was derived from a larger dataset known as the NIST Special Database 19 which contains digits, uppercase and lowercase handwritten letters. This paper introduces a variant of the full NIST dataset, which we have called Extended MNIST (EMNIST), which follows the same conversion paradigm used to create the MNIST dataset. The result is a set of datasets that constitute a more challenging classification tasks involving letters and digits, and that shares the same image structure and parameters as the original MNIST task, allowing for direct compatibility with all existing classifiers and systems. Benchmark results are presented along with a validation of the conversion process through the comparison of the classification results on converted NIST digits and the MNIST digits.
A Stochastic Approach to STDP
Mar 13, 2016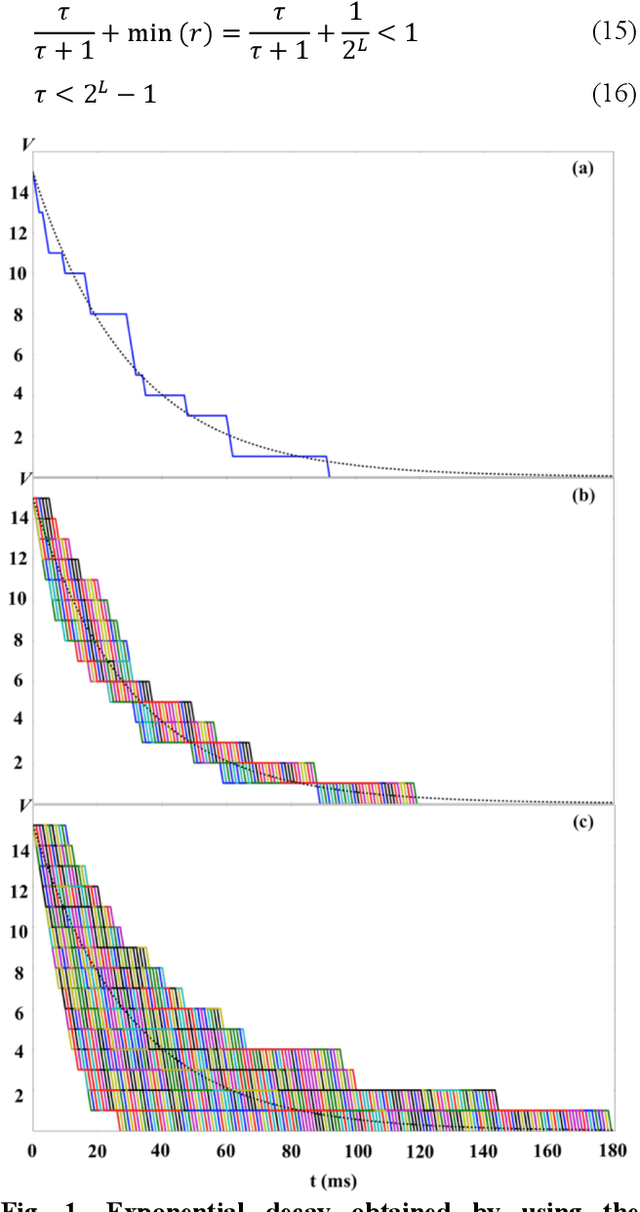
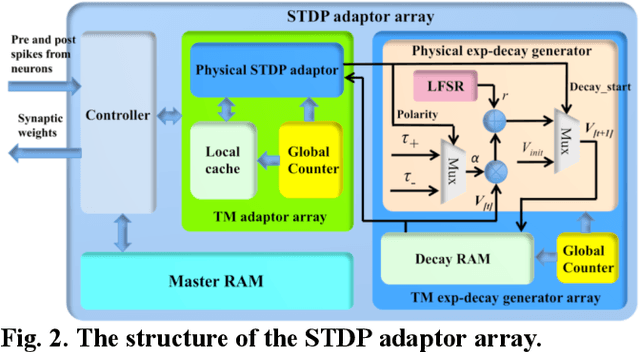
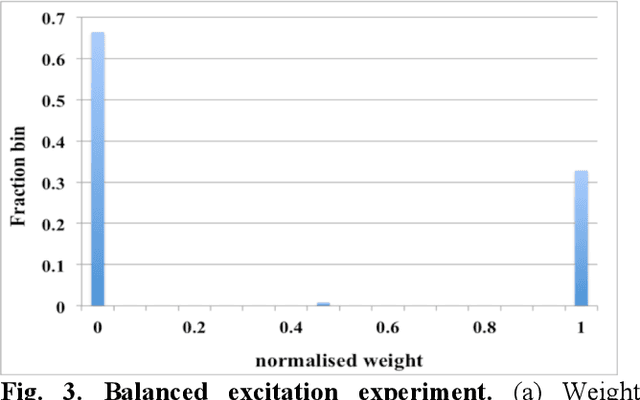
We present a digital implementation of the Spike Timing Dependent Plasticity (STDP) learning rule. The proposed digital implementation consists of an exponential decay generator array and a STDP adaptor array. On the arrival of a pre- and post-synaptic spike, the STDP adaptor will send a digital spike to the decay generator. The decay generator will then generate an exponential decay, which will be used by the STDP adaptor to perform the weight adaption. The exponential decay, which is computational expensive, is efficiently implemented by using a novel stochastic approach, which we analyse and characterise here. We use a time multiplexing approach to achieve 8192 (8k) virtual STDP adaptors and decay generators with only one physical implementation of each. We have validated our stochastic STDP approach with measurement results of a balanced excitation/inhibition experiment. Our stochastic approach is ideal for implementing the STDP learning rule in large-scale spiking neural networks running in real time.
A Reconfigurable Mixed-signal Implementation of a Neuromorphic ADC
Sep 03, 2015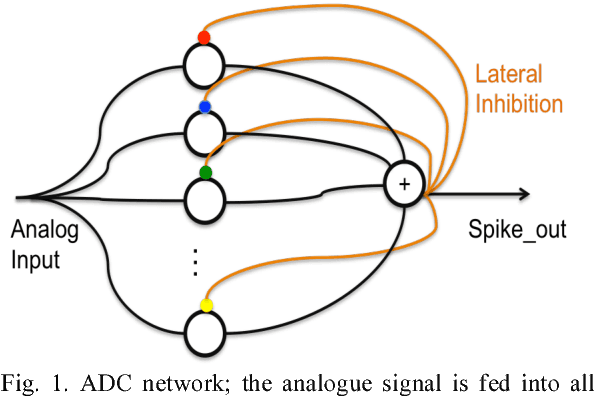
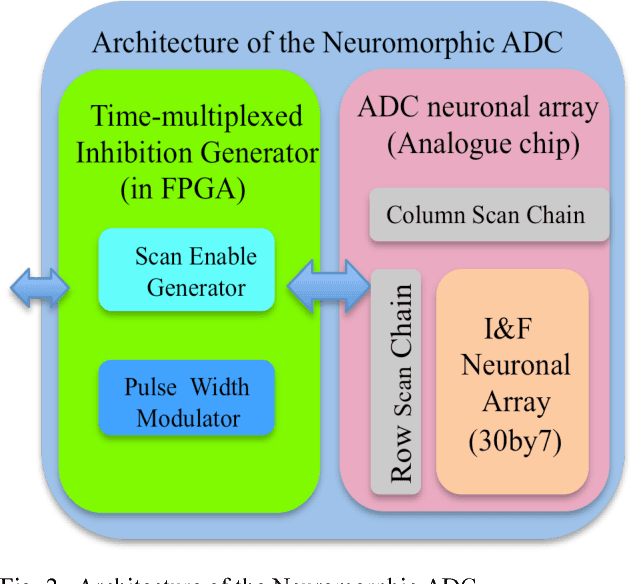
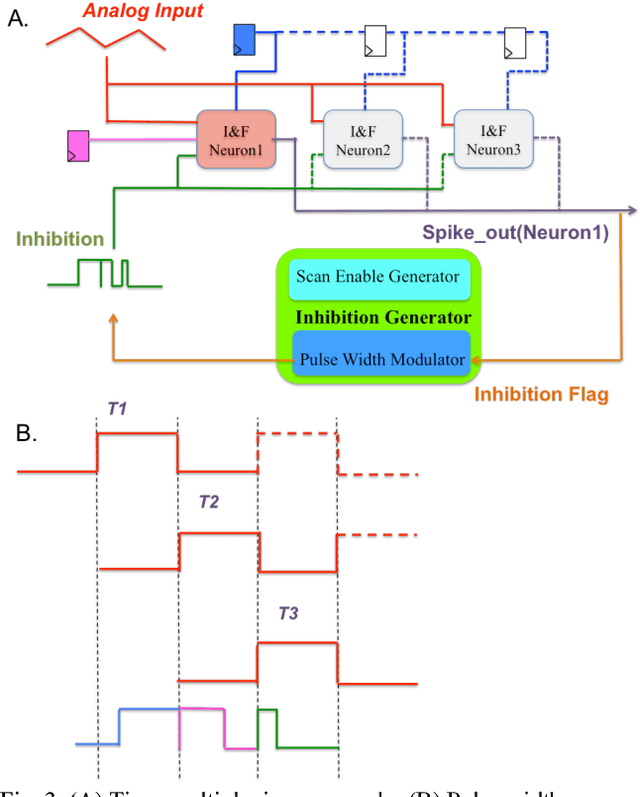
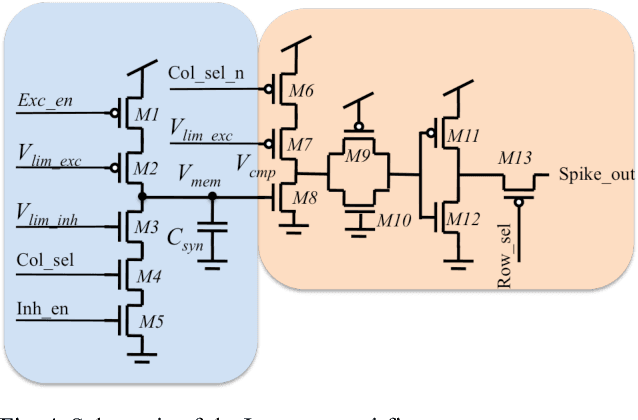
We present a neuromorphic Analogue-to-Digital Converter (ADC), which uses integrate-and-fire (I&F) neurons as the encoders of the analogue signal, with modulated inhibitions to decohere the neuronal spikes trains. The architecture consists of an analogue chip and a control module. The analogue chip comprises two scan chains and a twodimensional integrate-and-fire neuronal array. Individual neurons are accessed via the chains one by one without any encoder decoder or arbiter. The control module is implemented on an FPGA (Field Programmable Gate Array), which sends scan enable signals to the scan chains and controls the inhibition for individual neurons. Since the control module is implemented on an FPGA, it can be easily reconfigured. Additionally, we propose a pulse width modulation methodology for the lateral inhibition, which makes use of different pulse widths indicating different strengths of inhibition for each individual neuron to decohere neuronal spikes. Software simulations in this paper tested the robustness of the proposed ADC architecture to fixed random noise. A circuit simulation using ten neurons shows the performance and the feasibility of the architecture.
A compact aVLSI conductance-based silicon neuron
Sep 03, 2015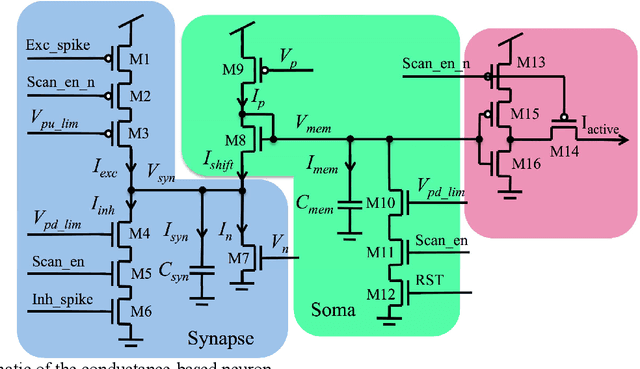

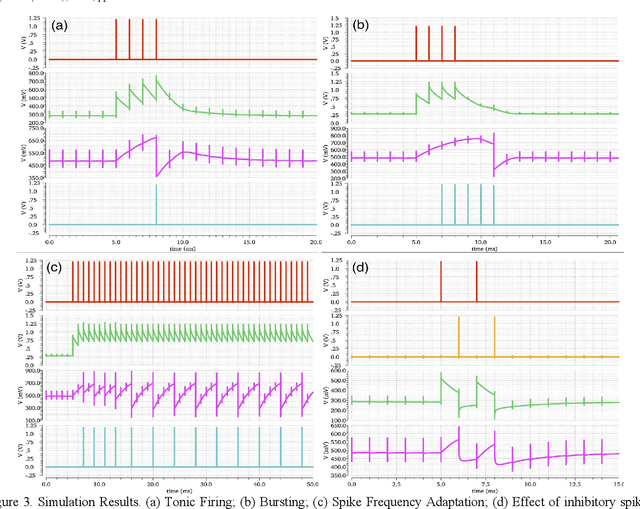
We present an analogue Very Large Scale Integration (aVLSI) implementation that uses first-order lowpass filters to implement a conductance-based silicon neuron for high-speed neuromorphic systems. The aVLSI neuron consists of a soma (cell body) and a single synapse, which is capable of linearly summing both the excitatory and inhibitory postsynaptic potentials (EPSP and IPSP) generated by the spikes arriving from different sources. Rather than biasing the silicon neuron with different parameters for different spiking patterns, as is typically done, we provide digital control signals, generated by an FPGA, to the silicon neuron to obtain different spiking behaviours. The proposed neuron is only ~26.5 um2 in the IBM 130nm process and thus can be integrated at very high density. Circuit simulations show that this neuron can emulate different spiking behaviours observed in biological neurons.
Fast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the 'extreme learning machine' algorithm
Jul 22, 2015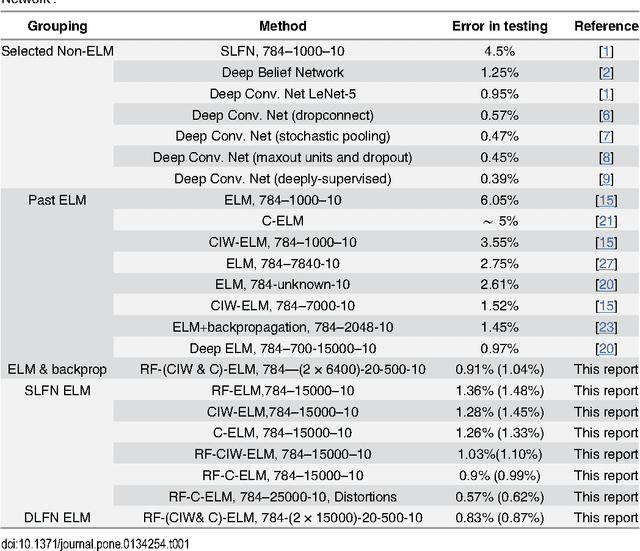
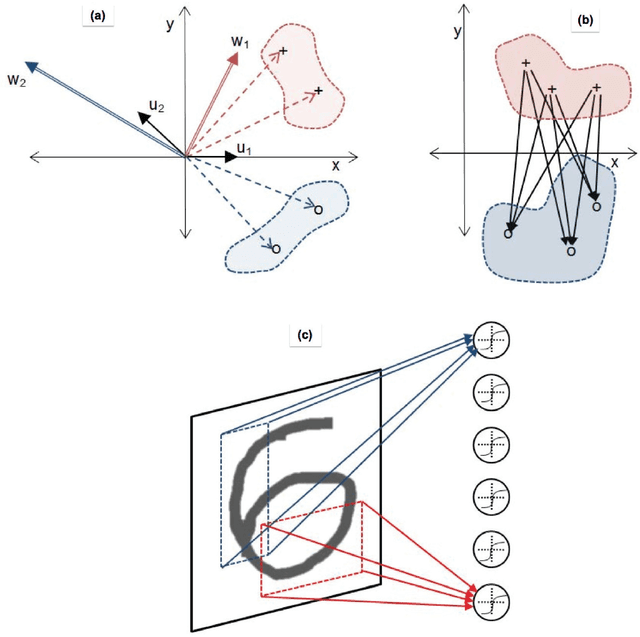
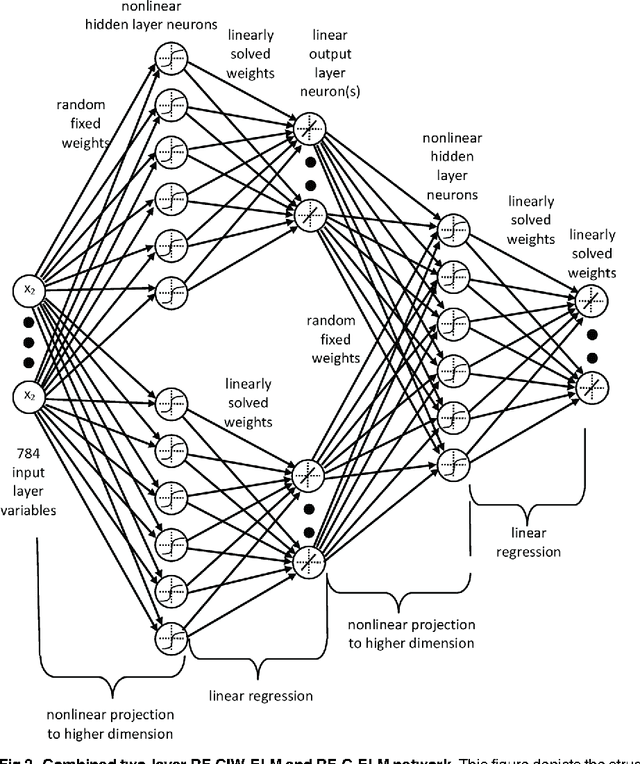
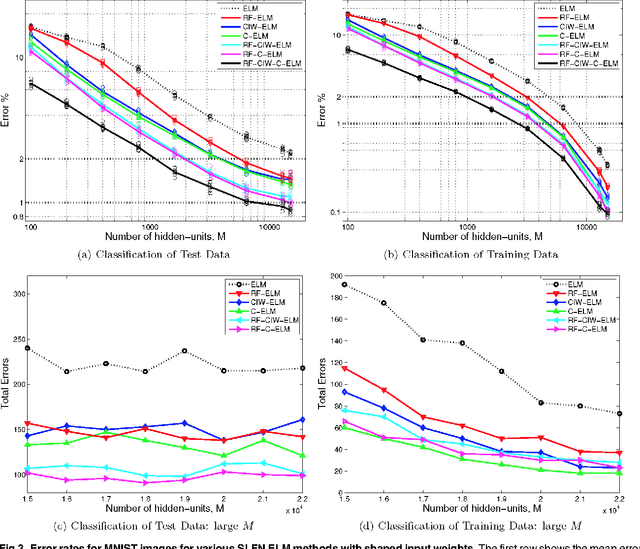
Recent advances in training deep (multi-layer) architectures have inspired a renaissance in neural network use. For example, deep convolutional networks are becoming the default option for difficult tasks on large datasets, such as image and speech recognition. However, here we show that error rates below 1% on the MNIST handwritten digit benchmark can be replicated with shallow non-convolutional neural networks. This is achieved by training such networks using the 'Extreme Learning Machine' (ELM) approach, which also enables a very rapid training time (~10 minutes). Adding distortions, as is common practise for MNIST, reduces error rates even further. Our methods are also shown to be capable of achieving less than 5.5% error rates on the NORB image database. To achieve these results, we introduce several enhancements to the standard ELM algorithm, which individually and in combination can significantly improve performance. The main innovation is to ensure each hidden-unit operates only on a randomly sized and positioned patch of each image. This form of random `receptive field' sampling of the input ensures the input weight matrix is sparse, with about 90% of weights equal to zero. Furthermore, combining our methods with a small number of iterations of a single-batch backpropagation method can significantly reduce the number of hidden-units required to achieve a particular performance. Our close to state-of-the-art results for MNIST and NORB suggest that the ease of use and accuracy of the ELM algorithm for designing a single-hidden-layer neural network classifier should cause it to be given greater consideration either as a standalone method for simpler problems, or as the final classification stage in deep neural networks applied to more difficult problems.
A neuromorphic hardware architecture using the Neural Engineering Framework for pattern recognition
Jul 21, 2015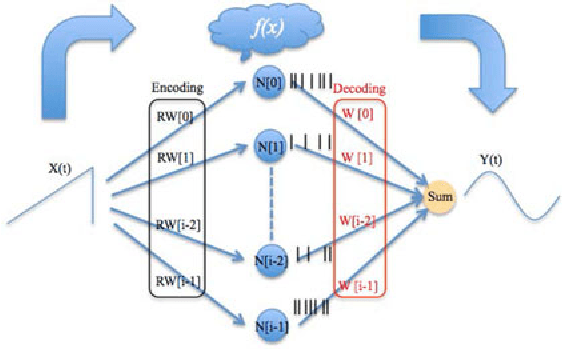
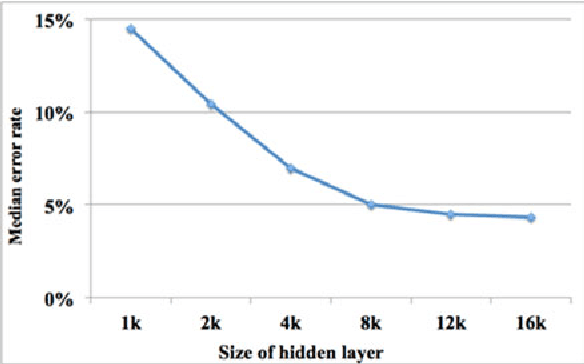
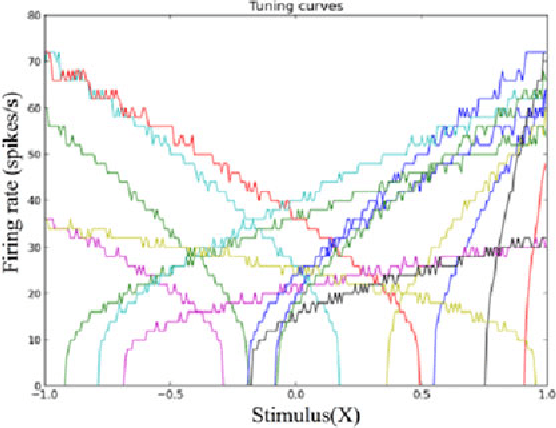
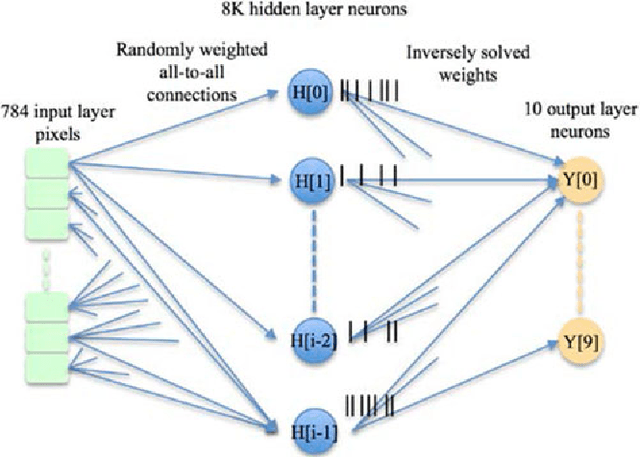
We present a hardware architecture that uses the Neural Engineering Framework (NEF) to implement large-scale neural networks on Field Programmable Gate Arrays (FPGAs) for performing pattern recognition in real time. NEF is a framework that is capable of synthesising large-scale cognitive systems from subnetworks. We will first present the architecture of the proposed neural network implemented using fixed-point numbers and demonstrate a routine that computes the decoding weights by using the online pseudoinverse update method (OPIUM) in a parallel and distributed manner. The proposed system is efficiently implemented on a compact digital neural core. This neural core consists of 64 neurons that are instantiated by a single physical neuron using a time-multiplexing approach. As a proof of concept, we combined 128 identical neural cores together to build a handwritten digit recognition system using the MNIST database and achieved a recognition rate of 96.55%. The system is implemented on a state-of-the-art FPGA and can process 5.12 million digits per second. The architecture is not limited to handwriting recognition, but is generally applicable as an extremely fast pattern recognition processor for various kinds of patterns such as speech and images.