 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 22, 2019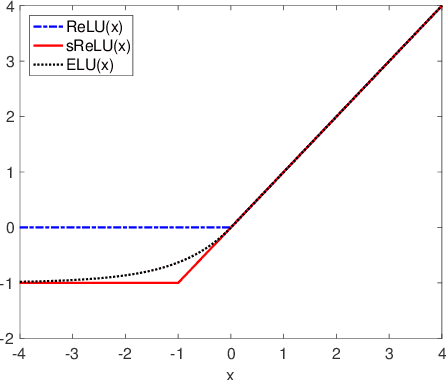
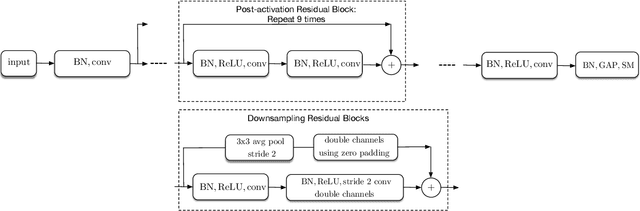
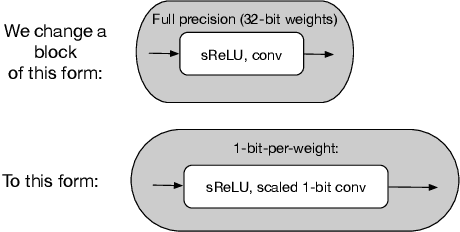
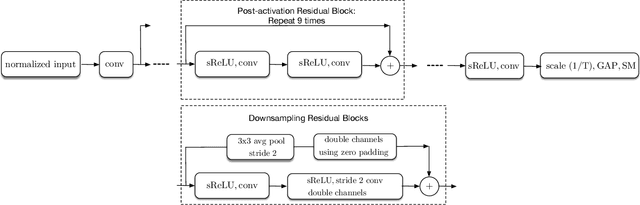
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
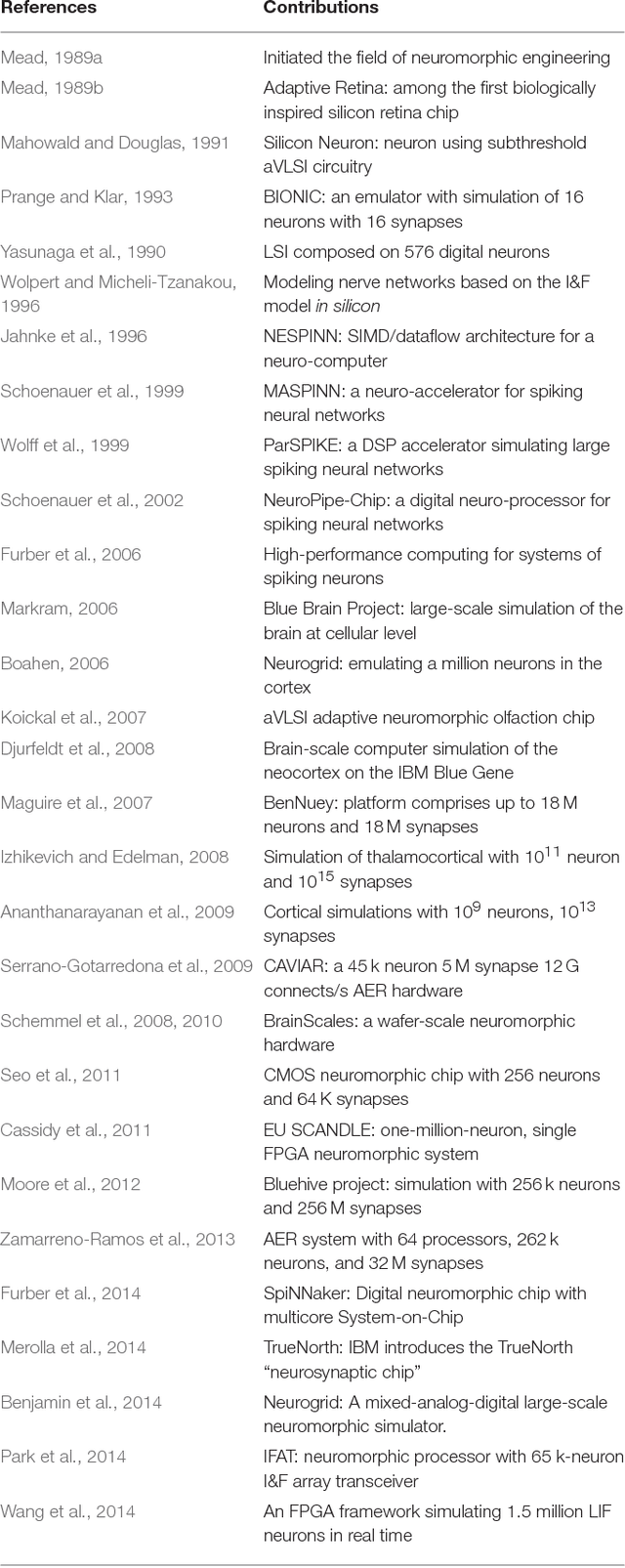
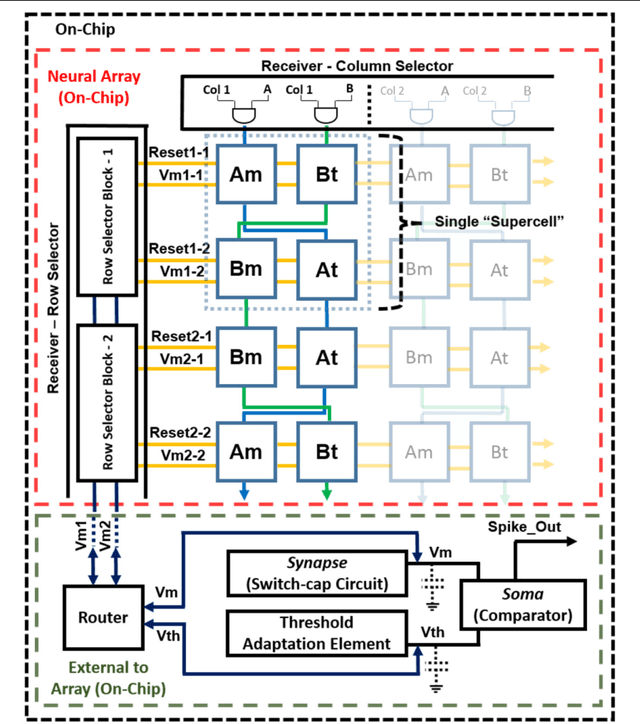
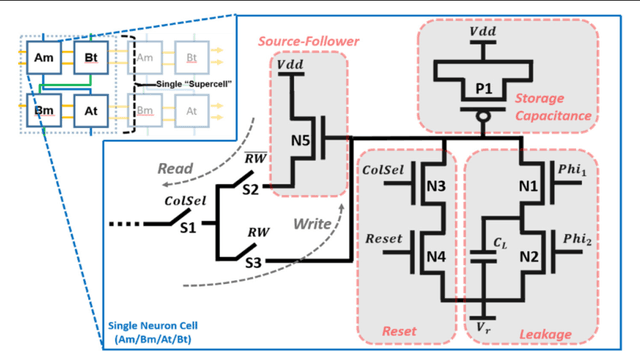
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
An FPGA-based Massively Parallel Neuromorphic Cortex Simulator
Mar 08, 2018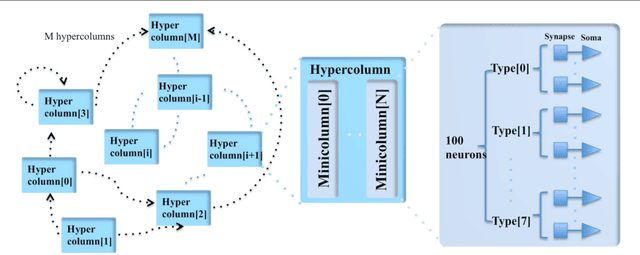

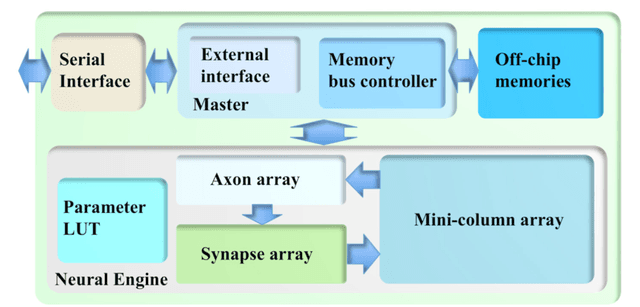

This paper presents a massively parallel and scalable neuromorphic cortex simulator designed for simulating large and structurally connected spiking neural networks, such as complex models of various areas of the cortex. The main novelty of this work is the abstraction of a neuromorphic architecture into clusters represented by minicolumns and hypercolumns, analogously to the fundamental structural units observed in neurobiology. Without this approach, simulating large-scale fully connected networks needs prohibitively large memory to store look-up tables for point-to-point connections. Instead, we use a novel architecture, based on the structural connectivity in the neocortex, such that all the required parameters and connections can be stored in on-chip memory. The cortex simulator can be easily reconfigured for simulating different neural networks without any change in hardware structure by programming the memory. A hierarchical communication scheme allows one neuron to have a fan-out of up to 200k neurons. As a proof-of-concept, an implementation on one Altera Stratix V FPGA was able to simulate 20 million to 2.6 billion leaky-integrate-and-fire (LIF) neurons in real time. We verified the system by emulating a simplified auditory cortex (with 100 million neurons). This cortex simulator achieved a low power dissipation of 1.62 {\mu}W per neuron. With the advent of commercially available FPGA boards, our system offers an accessible and scalable tool for the design, real-time simulation, and analysis of large-scale spiking neural networks.
An Online Learning Algorithm for Neuromorphic Hardware Implementation
Jul 30, 2017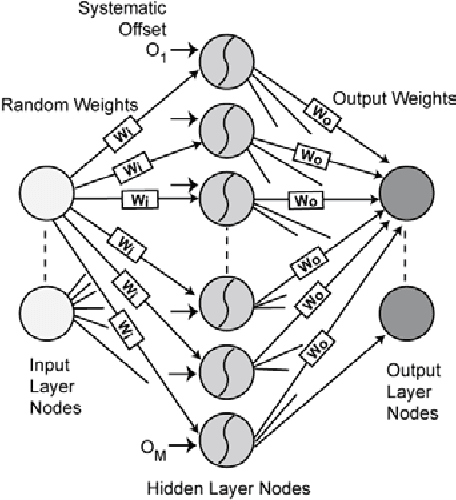


We propose a sign-based online learning (SOL) algorithm for a neuromorphic hardware framework called Trainable Analogue Block (TAB). The TAB framework utilises the principles of neural population coding, implying that it encodes the input stimulus using a large pool of nonlinear neurons. The SOL algorithm is a simple weight update rule that employs the sign of the hidden layer activation and the sign of the output error, which is the difference between the target output and the predicted output. The SOL algorithm is easily implementable in hardware, and can be used in any artificial neural network framework that learns weights by minimising a convex cost function. We show that the TAB framework can be trained for various regression tasks using the SOL algorithm.
A Stochastic Approach to STDP
Mar 13, 2016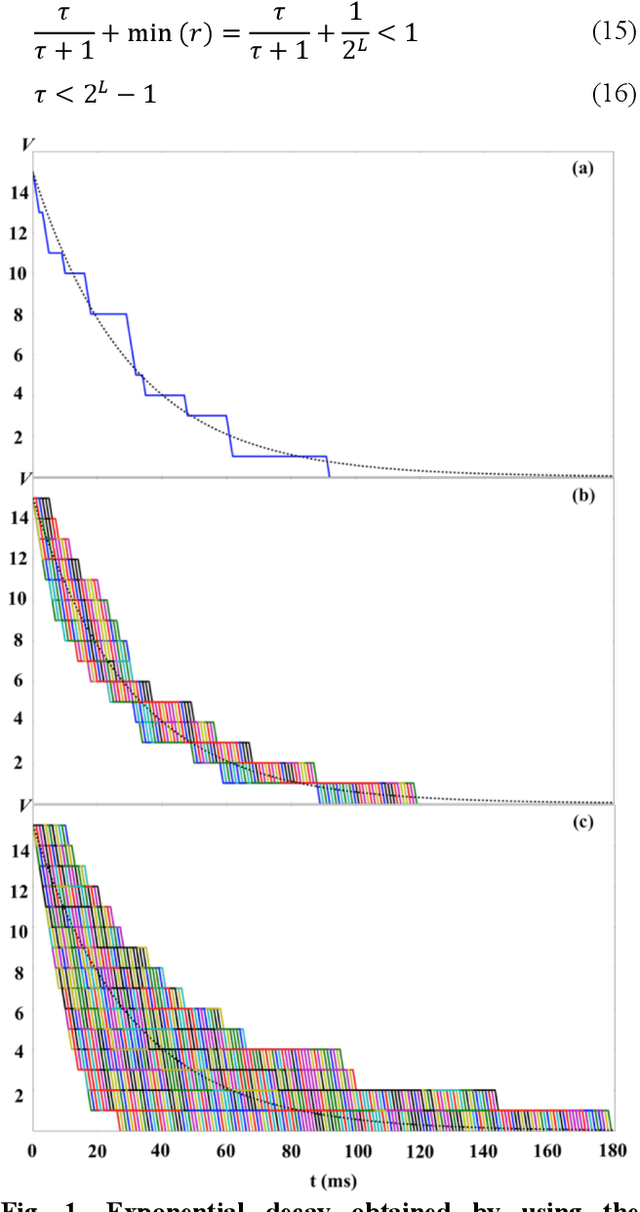
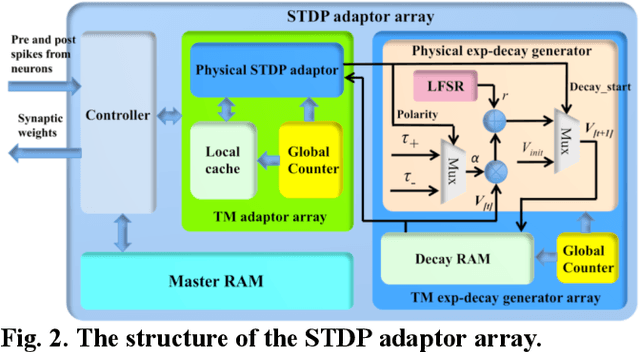
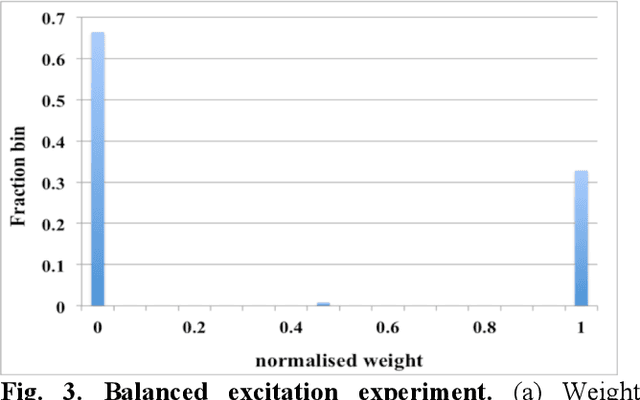
We present a digital implementation of the Spike Timing Dependent Plasticity (STDP) learning rule. The proposed digital implementation consists of an exponential decay generator array and a STDP adaptor array. On the arrival of a pre- and post-synaptic spike, the STDP adaptor will send a digital spike to the decay generator. The decay generator will then generate an exponential decay, which will be used by the STDP adaptor to perform the weight adaption. The exponential decay, which is computational expensive, is efficiently implemented by using a novel stochastic approach, which we analyse and characterise here. We use a time multiplexing approach to achieve 8192 (8k) virtual STDP adaptors and decay generators with only one physical implementation of each. We have validated our stochastic STDP approach with measurement results of a balanced excitation/inhibition experiment. Our stochastic approach is ideal for implementing the STDP learning rule in large-scale spiking neural networks running in real time.
A Reconfigurable Mixed-signal Implementation of a Neuromorphic ADC
Sep 03, 2015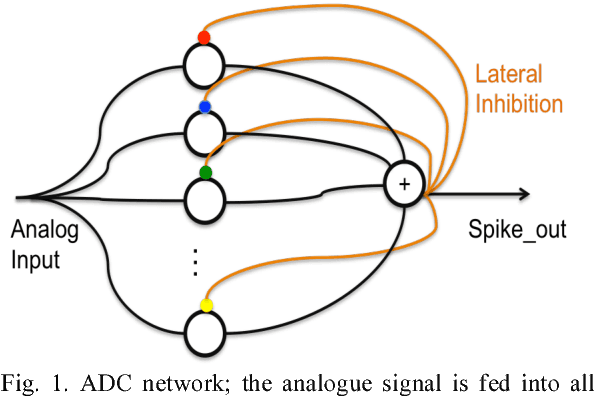
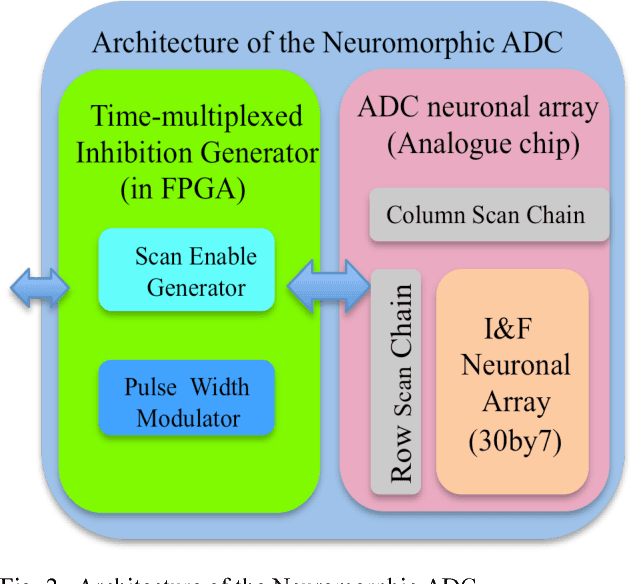
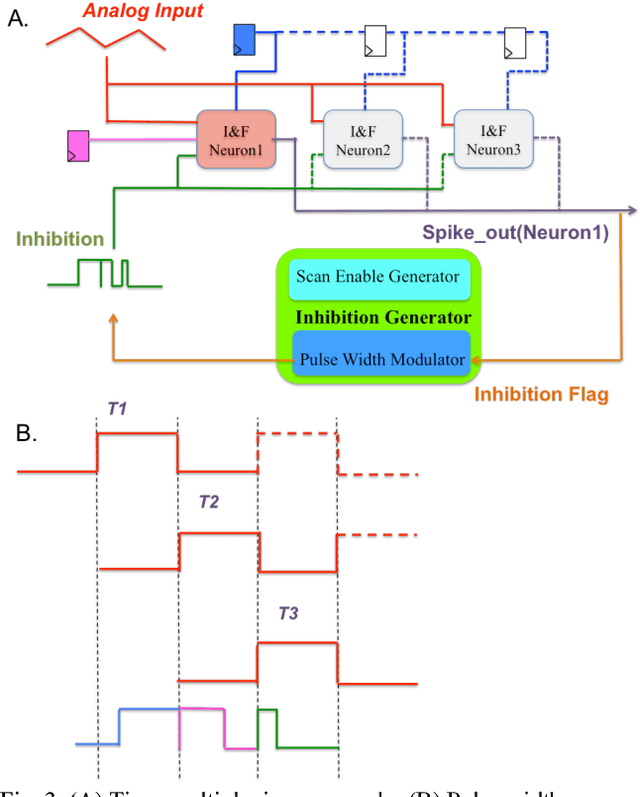
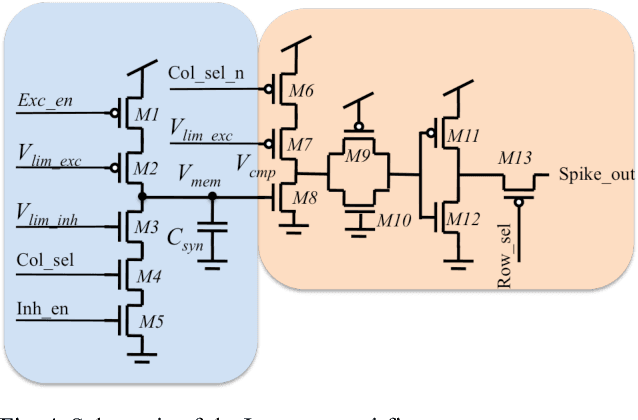
We present a neuromorphic Analogue-to-Digital Converter (ADC), which uses integrate-and-fire (I&F) neurons as the encoders of the analogue signal, with modulated inhibitions to decohere the neuronal spikes trains. The architecture consists of an analogue chip and a control module. The analogue chip comprises two scan chains and a twodimensional integrate-and-fire neuronal array. Individual neurons are accessed via the chains one by one without any encoder decoder or arbiter. The control module is implemented on an FPGA (Field Programmable Gate Array), which sends scan enable signals to the scan chains and controls the inhibition for individual neurons. Since the control module is implemented on an FPGA, it can be easily reconfigured. Additionally, we propose a pulse width modulation methodology for the lateral inhibition, which makes use of different pulse widths indicating different strengths of inhibition for each individual neuron to decohere neuronal spikes. Software simulations in this paper tested the robustness of the proposed ADC architecture to fixed random noise. A circuit simulation using ten neurons shows the performance and the feasibility of the architecture.
A compact aVLSI conductance-based silicon neuron
Sep 03, 2015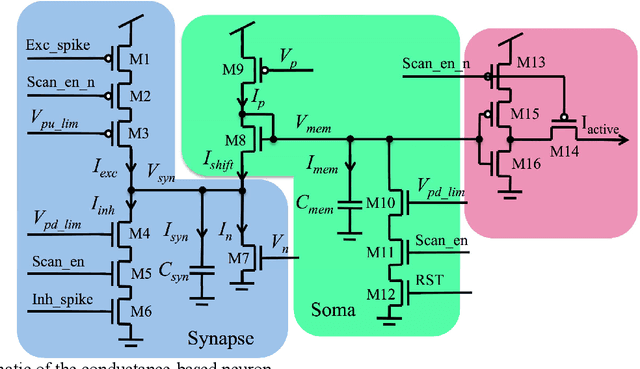

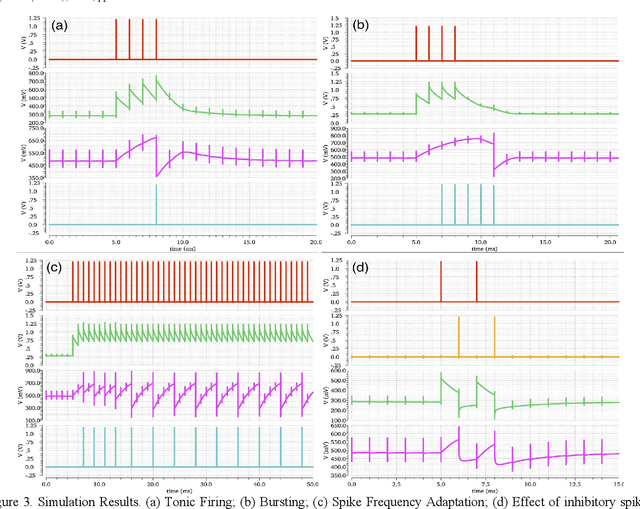
We present an analogue Very Large Scale Integration (aVLSI) implementation that uses first-order lowpass filters to implement a conductance-based silicon neuron for high-speed neuromorphic systems. The aVLSI neuron consists of a soma (cell body) and a single synapse, which is capable of linearly summing both the excitatory and inhibitory postsynaptic potentials (EPSP and IPSP) generated by the spikes arriving from different sources. Rather than biasing the silicon neuron with different parameters for different spiking patterns, as is typically done, we provide digital control signals, generated by an FPGA, to the silicon neuron to obtain different spiking behaviours. The proposed neuron is only ~26.5 um2 in the IBM 130nm process and thus can be integrated at very high density. Circuit simulations show that this neuron can emulate different spiking behaviours observed in biological neurons.
A neuromorphic hardware architecture using the Neural Engineering Framework for pattern recognition
Jul 21, 2015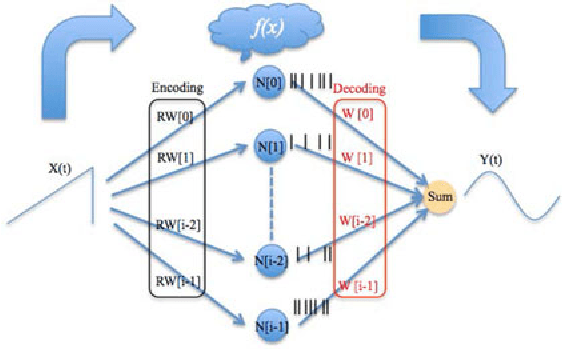
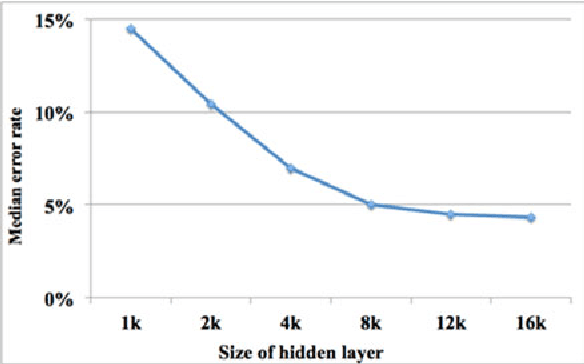
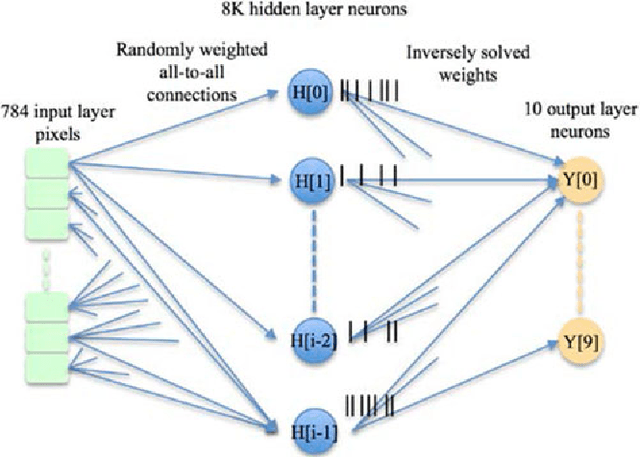
We present a hardware architecture that uses the Neural Engineering Framework (NEF) to implement large-scale neural networks on Field Programmable Gate Arrays (FPGAs) for performing pattern recognition in real time. NEF is a framework that is capable of synthesising large-scale cognitive systems from subnetworks. We will first present the architecture of the proposed neural network implemented using fixed-point numbers and demonstrate a routine that computes the decoding weights by using the online pseudoinverse update method (OPIUM) in a parallel and distributed manner. The proposed system is efficiently implemented on a compact digital neural core. This neural core consists of 64 neurons that are instantiated by a single physical neuron using a time-multiplexing approach. As a proof of concept, we combined 128 identical neural cores together to build a handwritten digit recognition system using the MNIST database and achieved a recognition rate of 96.55%. The system is implemented on a state-of-the-art FPGA and can process 5.12 million digits per second. The architecture is not limited to handwriting recognition, but is generally applicable as an extremely fast pattern recognition processor for various kinds of patterns such as speech and images.
A Trainable Neuromorphic Integrated Circuit that Exploits Device Mismatch
Jul 10, 2015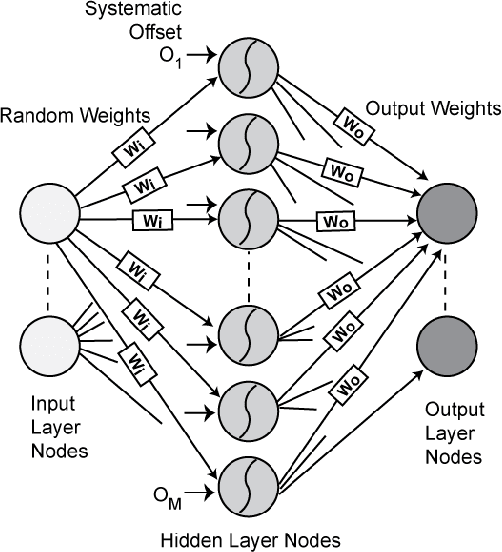
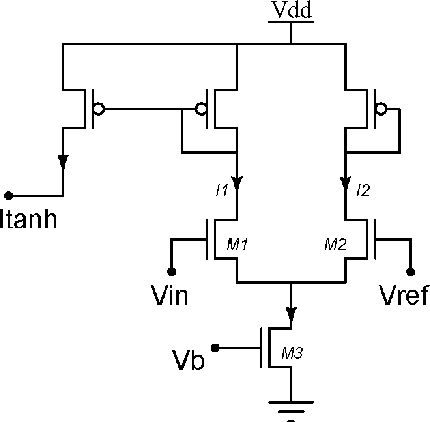
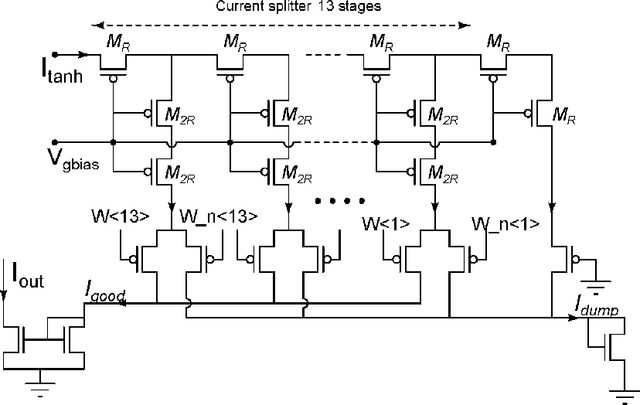
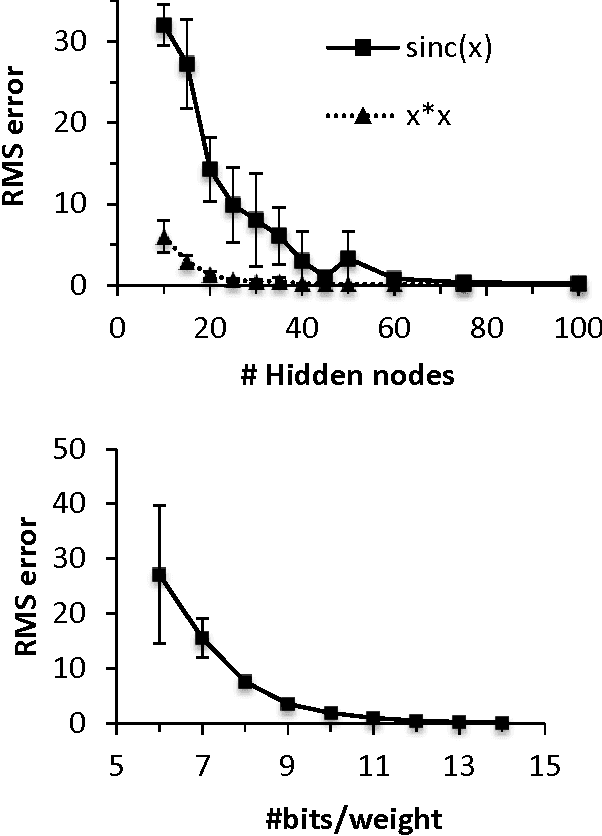
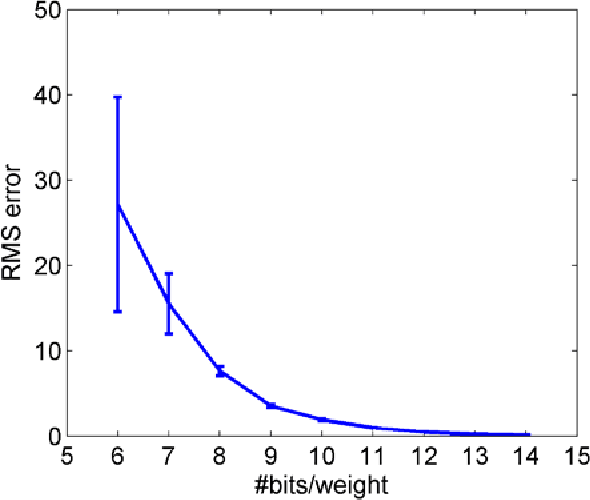
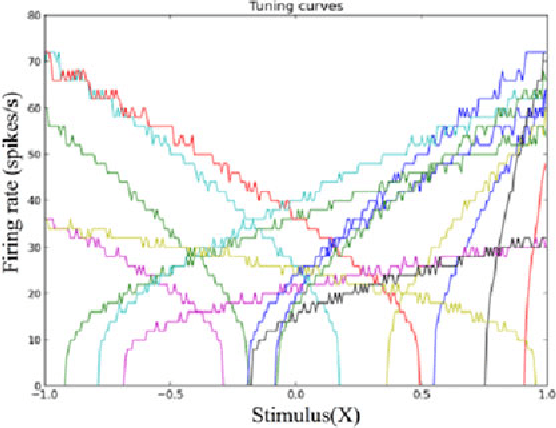
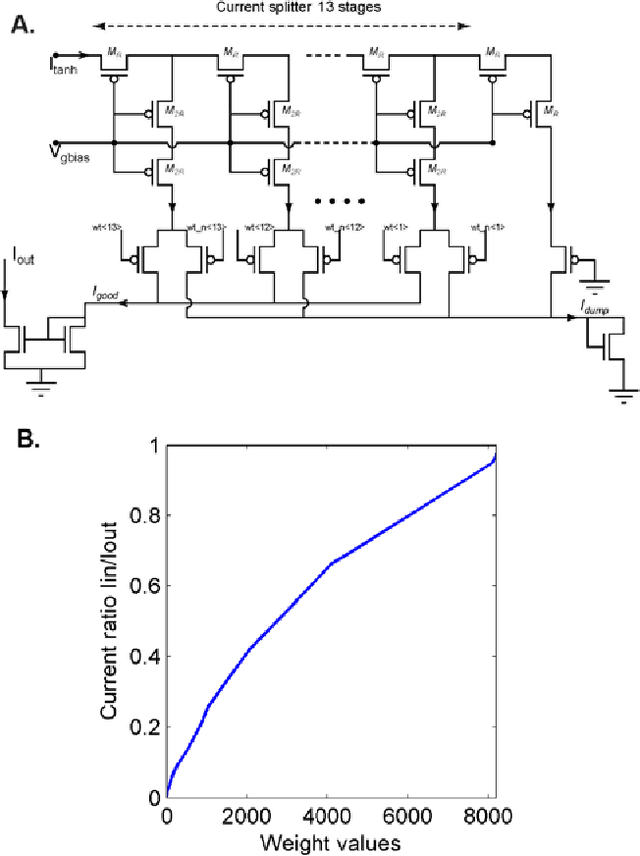
Random device mismatch that arises as a result of scaling of the CMOS (complementary metal-oxide semi-conductor) technology into the deep submicron regime degrades the accuracy of analogue circuits. Methods to combat this increase the complexity of design. We have developed a novel neuromorphic system called a Trainable Analogue Block (TAB), which exploits device mismatch as a means for random projections of the input to a higher dimensional space. The TAB framework is inspired by the principles of neural population coding operating in the biological nervous system. Three neuronal layers, namely input, hidden, and output, constitute the TAB framework, with the number of hidden layer neurons far exceeding the input layer neurons. Here, we present measurement results of the first prototype TAB chip built using a 65nm process technology and show its learning capability for various regression tasks. Our TAB chip exploits inherent randomness and variability arising due to the fabrication process to perform various learning tasks. Additionally, we characterise each neuron and discuss the statistical variability of its tuning curve that arises due to random device mismatch, a desirable property for the learning capability of the TAB. We also discuss the effect of the number of hidden neurons and the resolution of output weights on the accuracy of the learning capability of the TAB.
A neuromorphic hardware framework based on population coding
Mar 02, 2015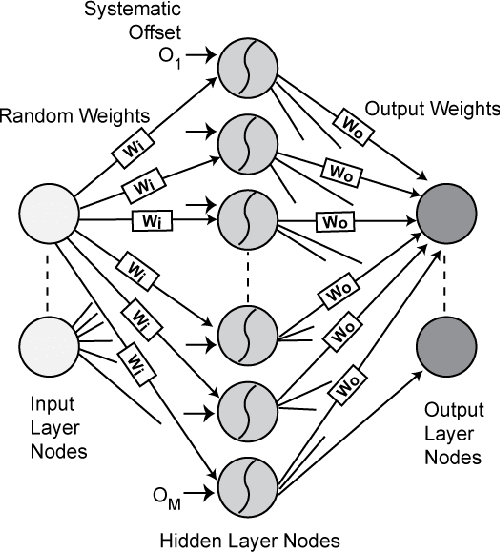
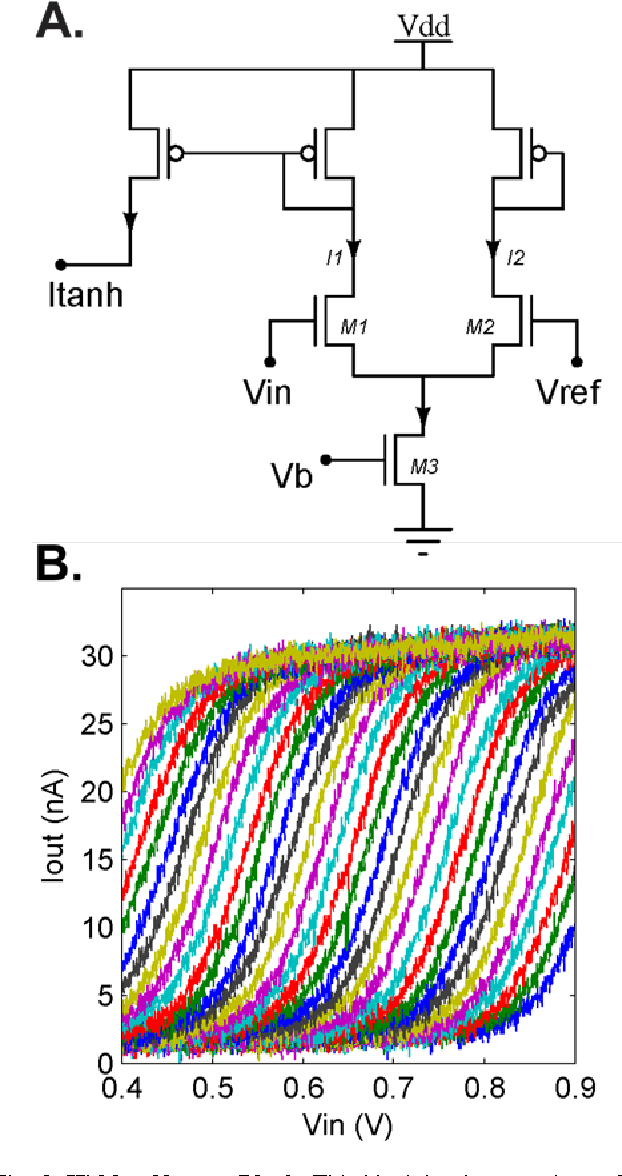
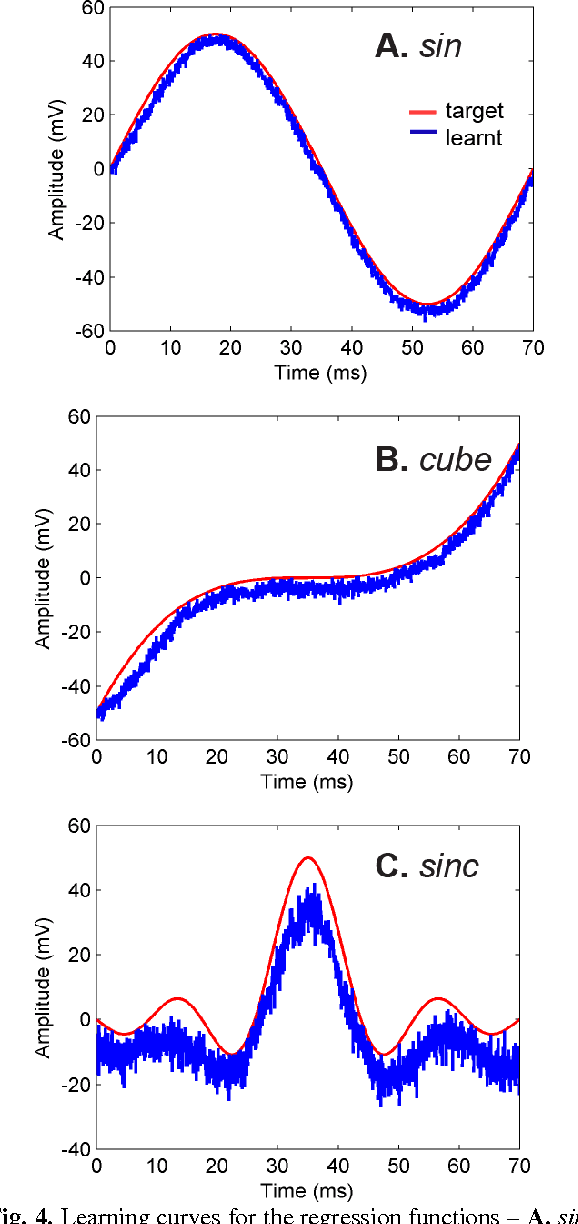
In the biological nervous system, large neuronal populations work collaboratively to encode sensory stimuli. These neuronal populations are characterised by a diverse distribution of tuning curves, ensuring that the entire range of input stimuli is encoded. Based on these principles, we have designed a neuromorphic system called a Trainable Analogue Block (TAB), which encodes given input stimuli using a large population of neurons with a heterogeneous tuning curve profile. Heterogeneity of tuning curves is achieved using random device mismatches in VLSI (Very Large Scale Integration) process and by adding a systematic offset to each hidden neuron. Here, we present measurement results of a single test cell fabricated in a 65nm technology to verify the TAB framework. We have mimicked a large population of neurons by re-using measurement results from the test cell by varying offset. We thus demonstrate the learning capability of the system for various regression tasks. The TAB system may pave the way to improve the design of analogue circuits for commercial applications, by rendering circuits insensitive to random mismatch that arises due to the manufacturing process.