 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIQ: Benchmarking 3D Geometric Reasoning of Vision Foundation Models with Simulated and Real Polyhedra
Jun 11, 2025
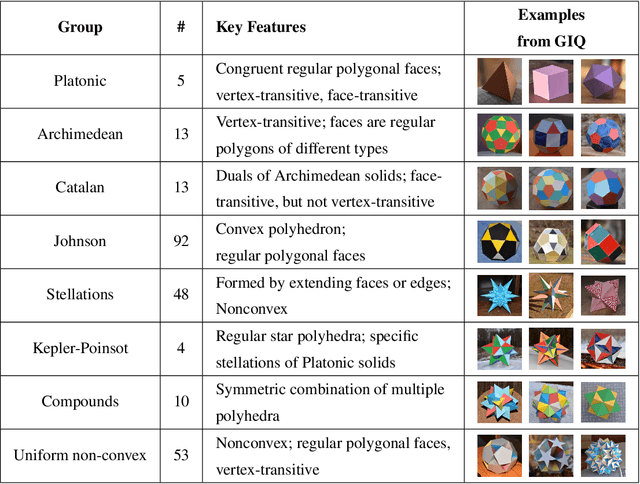
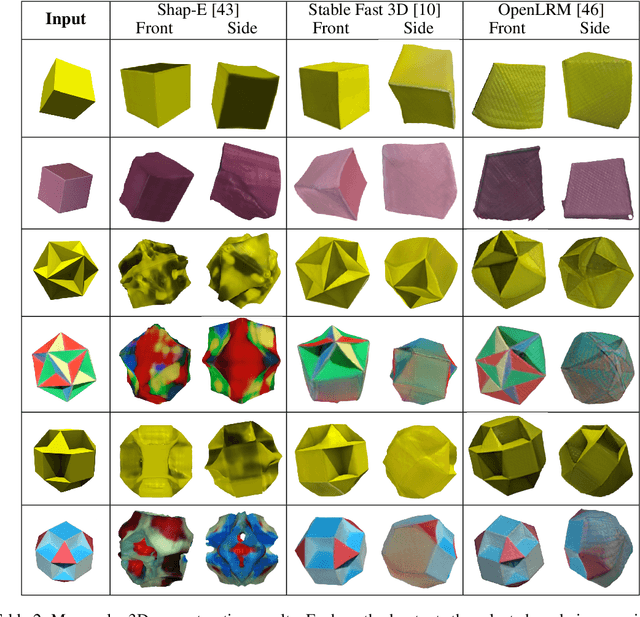
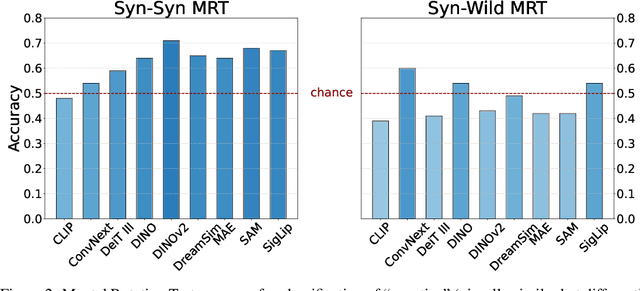
Monocular 3D reconstruction methods and vision-language models (VLMs) demonstrate impressive results on standard benchmarks, yet their true understanding of geometric properties remains unclear. We introduce GIQ , a comprehensive benchmark specifically designed to evaluate the geometric reasoning capabilities of vision and vision-language foundation models. GIQ comprises synthetic and real-world images of 224 diverse polyhedra - including Platonic, Archimedean, Johnson, and Catalan solids, as well as stellations and compound shapes - covering varying levels of complexity and symmetry. Through systematic experiments involving monocular 3D reconstruction, 3D symmetry detection, mental rotation tests, and zero-shot shape classification tasks, we reveal significant shortcomings in current models. State-of-the-art reconstruction algorithms trained on extensive 3D datasets struggle to reconstruct even basic geometric forms accurately. While foundation models effectively detect specific 3D symmetry elements via linear probing, they falter significantly in tasks requiring detailed geometric differentiation, such as mental rotation. Moreover, advanced vision-language assistants exhibit remarkably low accuracy on complex polyhedra, systematically misinterpreting basic properties like face geometry, convexity, and compound structures. GIQ is publicly available, providing a structured platform to highlight and address critical gaps in geometric intelligence, facilitating future progress in robust, geometry-aware representation learning.
Not all Views are Created Equal: Analyzing Viewpoint Instabilities in Vision Foundation Models
Dec 27, 2024



In this paper, we analyze the viewpoint stability of foundational models - specifically, their sensitivity to changes in viewpoint- and define instability as significant feature variations resulting from minor changes in viewing angle, leading to generalization gaps in 3D reasoning tasks. We investigate nine foundational models, focusing on their responses to viewpoint changes, including the often-overlooked accidental viewpoints where specific camera orientations obscure an object's true 3D structure. Our methodology enables recognizing and classifying out-of-distribution (OOD), accidental, and stable viewpoints using feature representations alone, without accessing the actual images. Our findings indicate that while foundation models consistently encode accidental viewpoints, they vary in their interpretation of OOD viewpoints due to inherent biases, at times leading to object misclassifications based on geometric resemblance. Through quantitative and qualitative evaluations on three downstream tasks - classification, VQA, and 3D reconstruction - we illustrate the impact of viewpoint instability and underscore the importance of feature robustness across diverse viewing conditions.
DRAGON: Drone and Ground Gaussian Splatting for 3D Building Reconstruction
Jul 01, 2024



3D building reconstruction from imaging data is an important task for many applications ranging from urban planning to reconnaissance. Modern Novel View synthesis (NVS) methods like NeRF and Gaussian Splatting offer powerful techniques for developing 3D models from natural 2D imagery in an unsupervised fashion. These algorithms generally require input training views surrounding the scene of interest, which, in the case of large buildings, is typically not available across all camera elevations. In particular, the most readily available camera viewpoints at scale across most buildings are at near-ground (e.g., with mobile phones) and aerial (drones) elevations. However, due to the significant difference in viewpoint between drone and ground image sets, camera registration - a necessary step for NVS algorithms - fails. In this work we propose a method, DRAGON, that can take drone and ground building imagery as input and produce a 3D NVS model. The key insight of DRAGON is that intermediate elevation imagery may be extrapolated by an NVS algorithm itself in an iterative procedure with perceptual regularization, thereby bridging the visual feature gap between the two elevations and enabling registration. We compiled a semi-synthetic dataset of 9 large building scenes using Google Earth Studio, and quantitatively and qualitatively demonstrate that DRAGON can generate compelling renderings on this dataset compared to baseline strategies.
Domain Generalization Guided by Gradient Signal to Noise Ratio of Parameters
Oct 11, 2023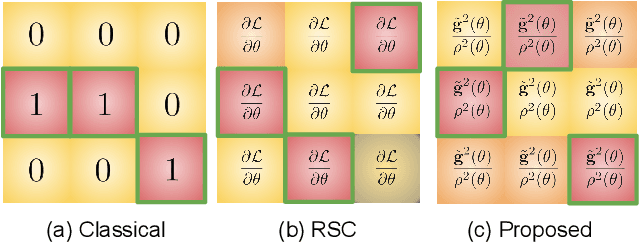
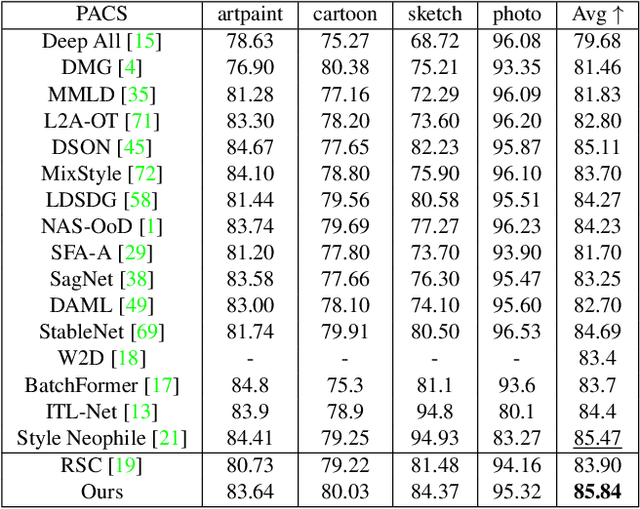
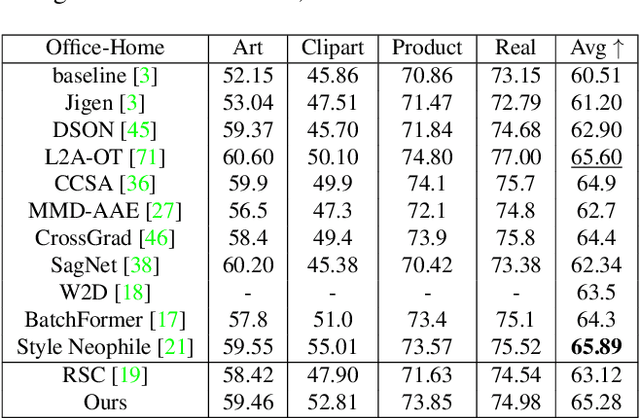
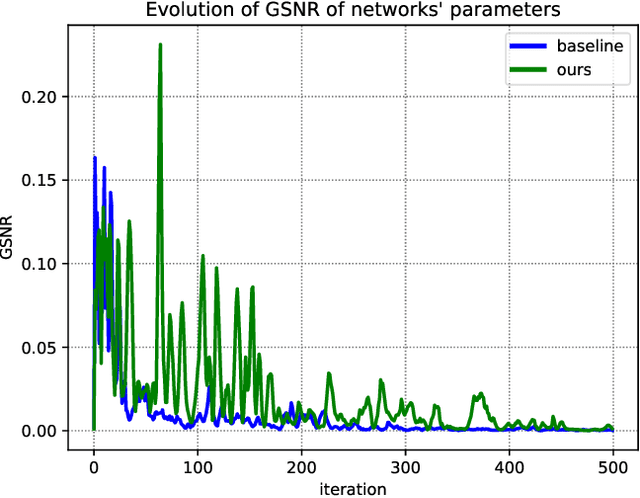
Overfitting to the source domain is a common issue in gradient-based training of deep neural networks. To compensate for the over-parameterized models, numerous regularization techniques have been introduced such as those based on dropout. While these methods achieve significant improvements on classical benchmarks such as ImageNet, their performance diminishes with the introduction of domain shift in the test set i.e. when the unseen data comes from a significantly different distribution. In this paper, we move away from the classical approach of Bernoulli sampled dropout mask construction and propose to base the selection on gradient-signal-to-noise ratio (GSNR) of network's parameters. Specifically, at each training step, parameters with high GSNR will be discarded. Furthermore, we alleviate the burden of manually searching for the optimal dropout ratio by leveraging a meta-learning approach. We evaluate our method on standard domain generalization benchmarks and achieve competitive results on classification and face anti-spoofing problems.
Learning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 16, 2021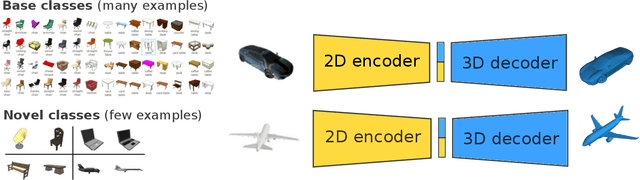
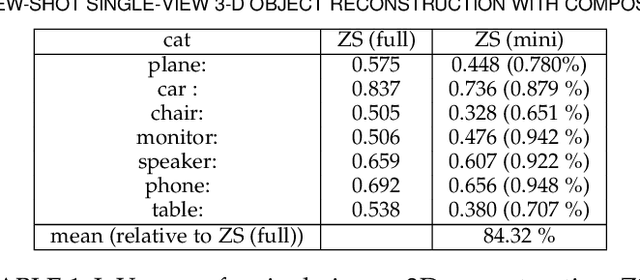
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.
A Simple and Scalable Shape Representation for 3D Reconstruction
May 10, 2020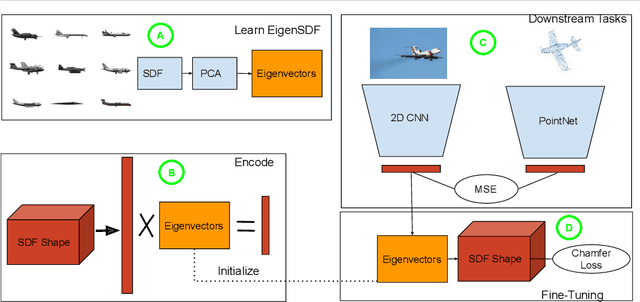
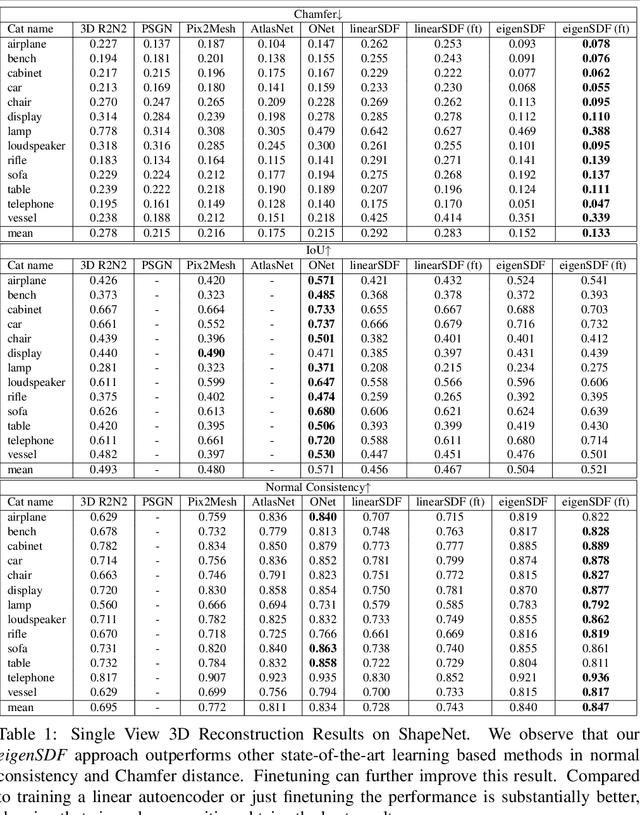
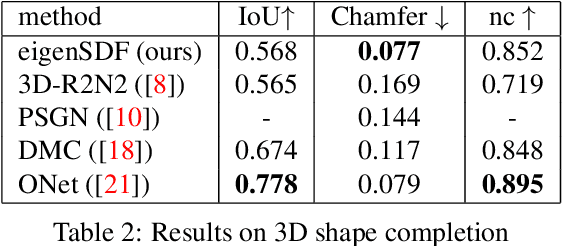
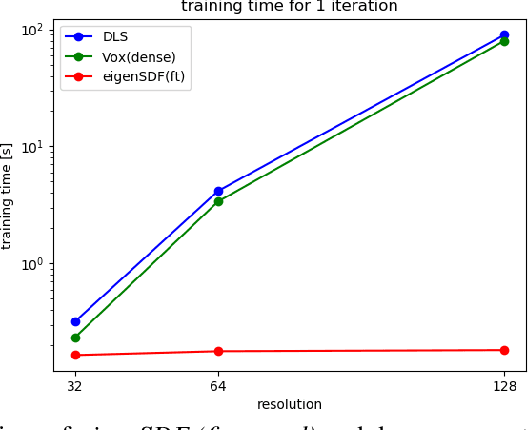
Deep learning applied to the reconstruction of 3D shapes has seen growing interest. A popular approach to 3D reconstruction and generation in recent years has been the CNN encoder-decoder model usually applied in voxel space. However, this often scales very poorly with the resolution limiting the effectiveness of these models. Several sophisticated alternatives for decoding to 3D shapes have been proposed typically relying on complex deep learning architectures for the decoder model. In this work, we show that this additional complexity is not necessary, and that we can actually obtain high quality 3D reconstruction using a linear decoder, obtained from principal component analysis on the signed distance function (SDF) of the surface. This approach allows easily scaling to larger resolutions. We show in multiple experiments that our approach is competitive with state-of-the-art methods. It also allows the decoder to be fine-tuned on the target task using a loss designed specifically for SDF transforms, obtaining further gains.
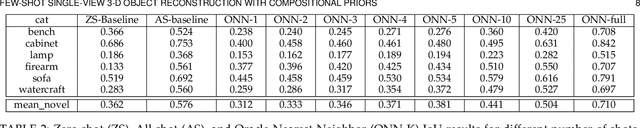
Few-Shot Single-View 3-D Object Reconstruction with Compositional Priors
May 03, 2020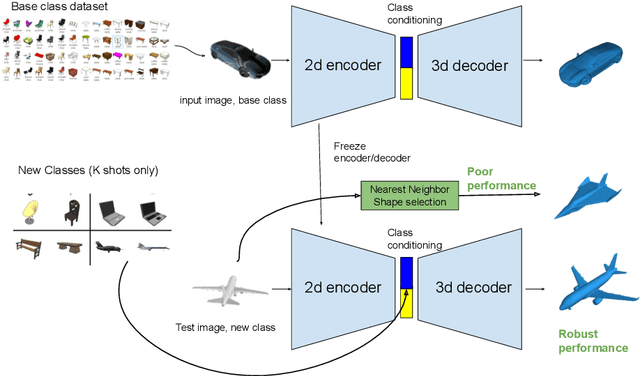
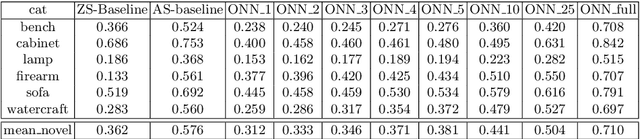
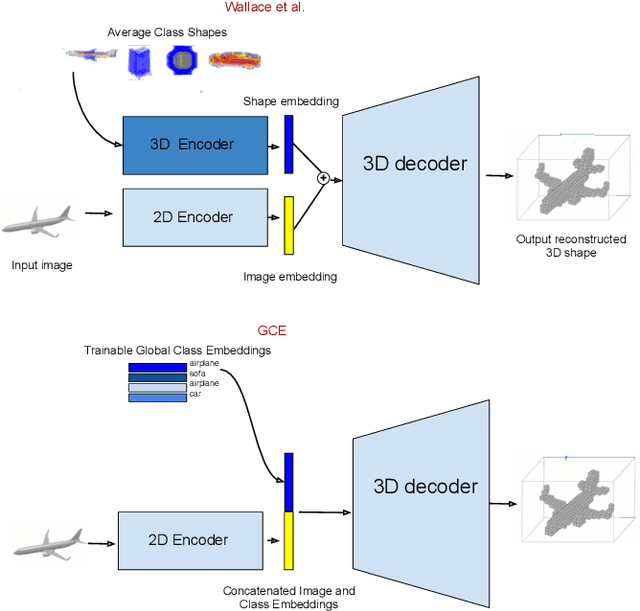
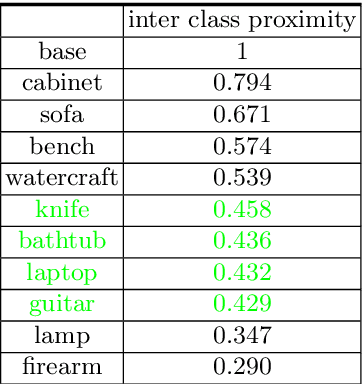
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. However, recent work has challenged this belief, showing that complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per category data in standard benchmarks. On the other hand settings where 3D shape must be inferred for new categories with few examples are more natural and require models that generalize about shapes. In this work we demonstrate experimentally that naive baselines do not apply when the goal is to learn to reconstruct novel objects using very few examples, and that in a \emph{few-shot} learning setting, the network must learn concepts that can be applied to new categories, avoiding rote memorization. To address deficiencies in existing approaches to this problem, we propose three approaches that efficiently integrate a class prior into a 3D reconstruction model, allowing to account for intra-class variability and imposing an implicit compositional structure that the model should learn. Experiments on the popular ShapeNet database demonstrate that our method significantly outperform existing baselines on this task in the few-shot setting.
Deep Level Sets: Implicit Surface Representations for 3D Shape Inference
Jan 21, 2019
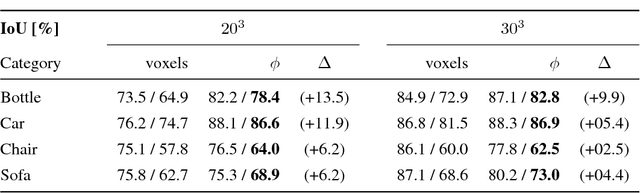


Existing 3D surface representation approaches are unable to accurately classify pixels and their orientation lying on the boundary of an object. Thus resulting in coarse representations which usually require post-processing steps to extract 3D surface meshes. To overcome this limitation, we propose an end-to-end trainable model that directly predicts implicit surface representations of arbitrary topology by optimising a novel geometric loss function. Specifically, we propose to represent the output as an oriented level set of a continuous embedding function, and incorporate this in a deep end-to-end learning framework by introducing a variational shape inference formulation. We investigate the benefits of our approach on the task of 3D surface prediction and demonstrate its ability to produce a more accurate reconstruction compared to voxel-based representations. We further show that our model is flexible and can be applied to a variety of shape inference problems.