 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025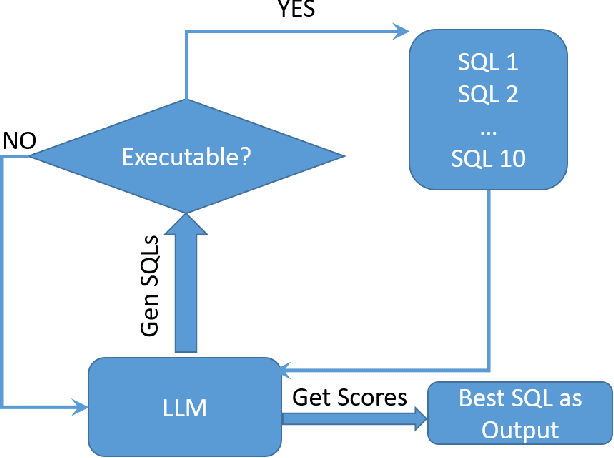
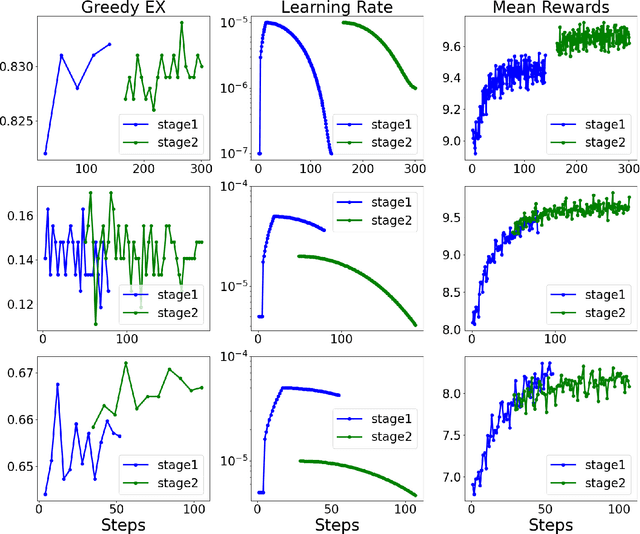
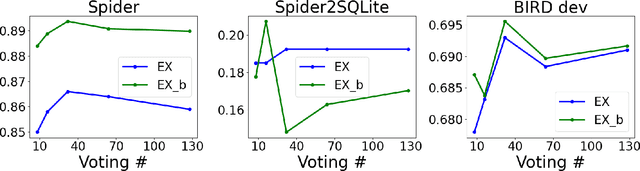
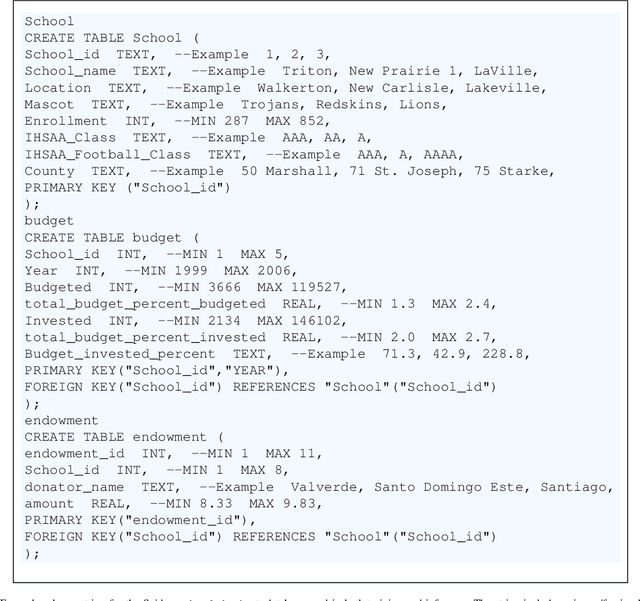
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
Domain Generalization Guided by Gradient Signal to Noise Ratio of Parameters
Oct 11, 2023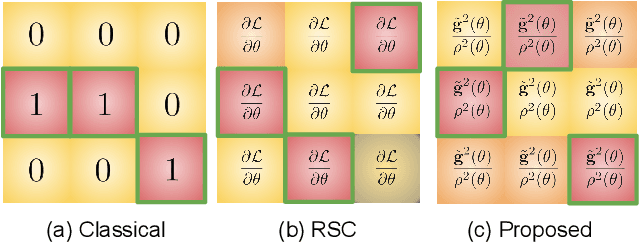
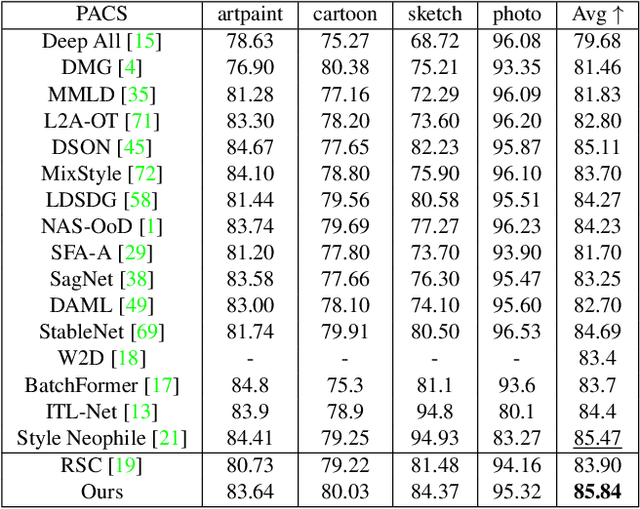
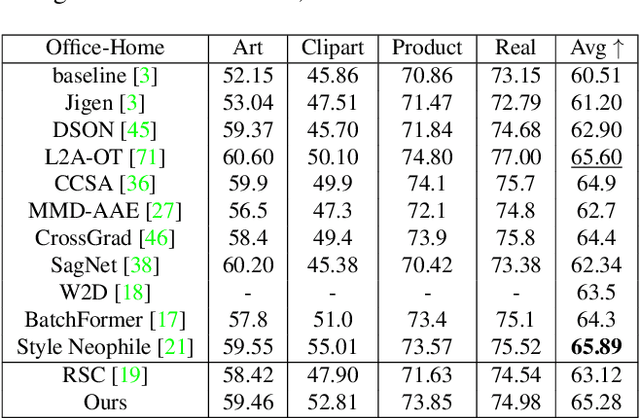
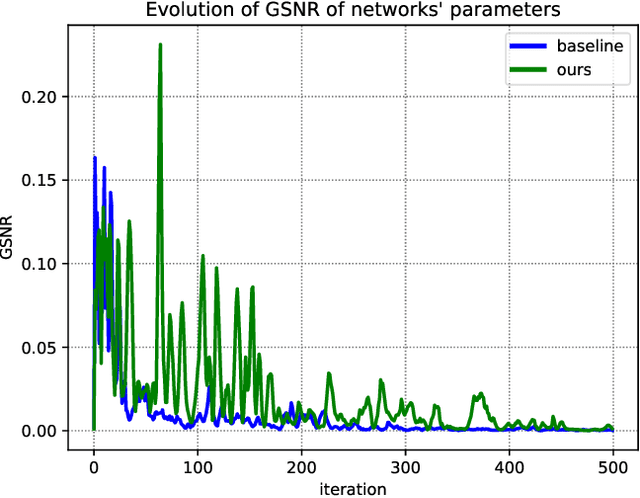
Overfitting to the source domain is a common issue in gradient-based training of deep neural networks. To compensate for the over-parameterized models, numerous regularization techniques have been introduced such as those based on dropout. While these methods achieve significant improvements on classical benchmarks such as ImageNet, their performance diminishes with the introduction of domain shift in the test set i.e. when the unseen data comes from a significantly different distribution. In this paper, we move away from the classical approach of Bernoulli sampled dropout mask construction and propose to base the selection on gradient-signal-to-noise ratio (GSNR) of network's parameters. Specifically, at each training step, parameters with high GSNR will be discarded. Furthermore, we alleviate the burden of manually searching for the optimal dropout ratio by leveraging a meta-learning approach. We evaluate our method on standard domain generalization benchmarks and achieve competitive results on classification and face anti-spoofing problems.
Controllable Dynamic Multi-Task Architectures
Mar 28, 2022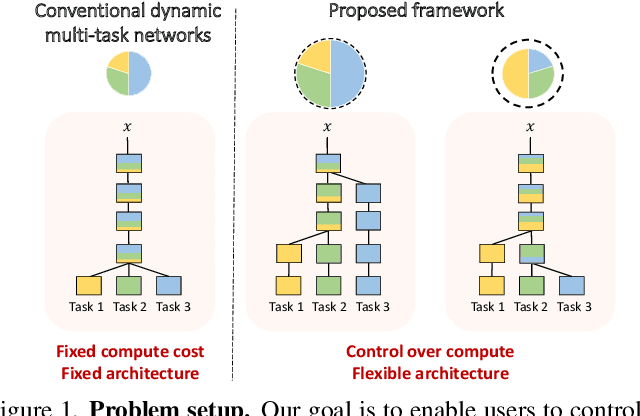
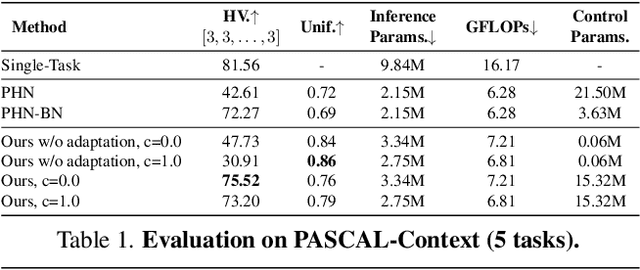
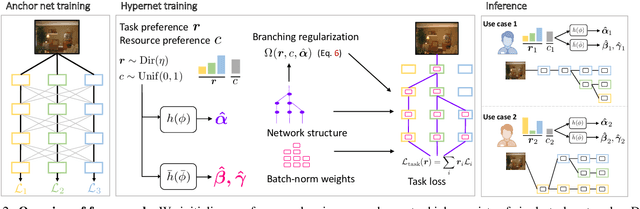

Multi-task learning commonly encounters competition for resources among tasks, specifically when model capacity is limited. This challenge motivates models which allow control over the relative importance of tasks and total compute cost during inference time. In this work, we propose such a controllable multi-task network that dynamically adjusts its architecture and weights to match the desired task preference as well as the resource constraints. In contrast to the existing dynamic multi-task approaches that adjust only the weights within a fixed architecture, our approach affords the flexibility to dynamically control the total computational cost and match the user-preferred task importance better. We propose a disentangled training of two hypernetworks, by exploiting task affinity and a novel branching regularized loss, to take input preferences and accordingly predict tree-structured models with adapted weights. Experiments on three multi-task benchmarks, namely PASCAL-Context, NYU-v2, and CIFAR-100, show the efficacy of our approach. Project page is available at https://www.nec-labs.com/~mas/DYMU.
On Generalizing Beyond Domains in Cross-Domain Continual Learning
Mar 08, 2022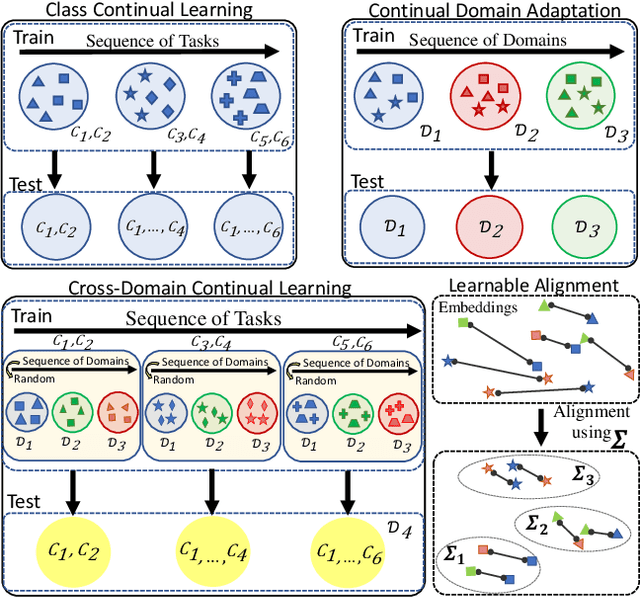

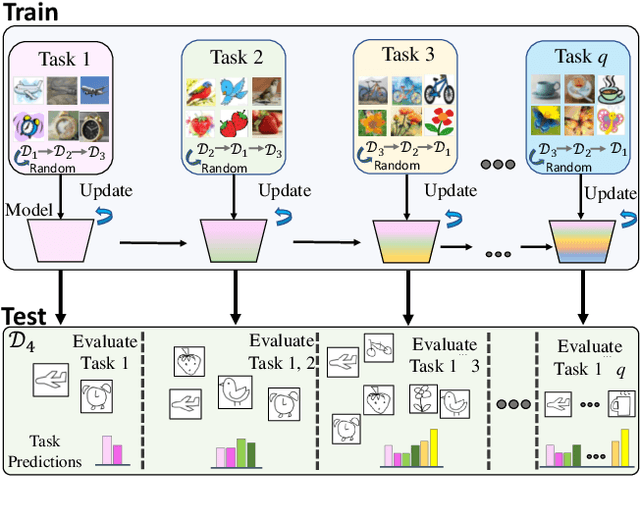

Humans have the ability to accumulate knowledge of new tasks in varying conditions, but deep neural networks often suffer from catastrophic forgetting of previously learned knowledge after learning a new task. Many recent methods focus on preventing catastrophic forgetting under the assumption of train and test data following similar distributions. In this work, we consider a more realistic scenario of continual learning under domain shifts where the model must generalize its inference to an unseen domain. To this end, we encourage learning semantically meaningful features by equipping the classifier with class similarity metrics as learning parameters which are obtained through Mahalanobis similarity computations. Learning of the backbone representation along with these extra parameters is done seamlessly in an end-to-end manner. In addition, we propose an approach based on the exponential moving average of the parameters for better knowledge distillation. We demonstrate that, to a great extent, existing continual learning algorithms fail to handle the forgetting issue under multiple distributions, while our proposed approach learns new tasks under domain shift with accuracy boosts up to 10% on challenging datasets such as DomainNet and OfficeHome.
Learning Semantic Segmentation from Multiple Datasets with Label Shifts
Feb 28, 2022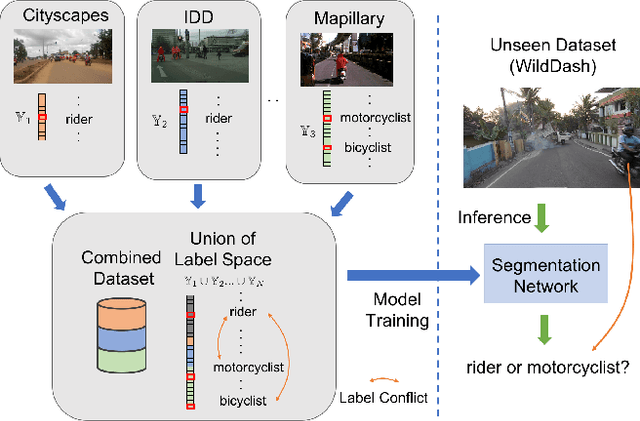
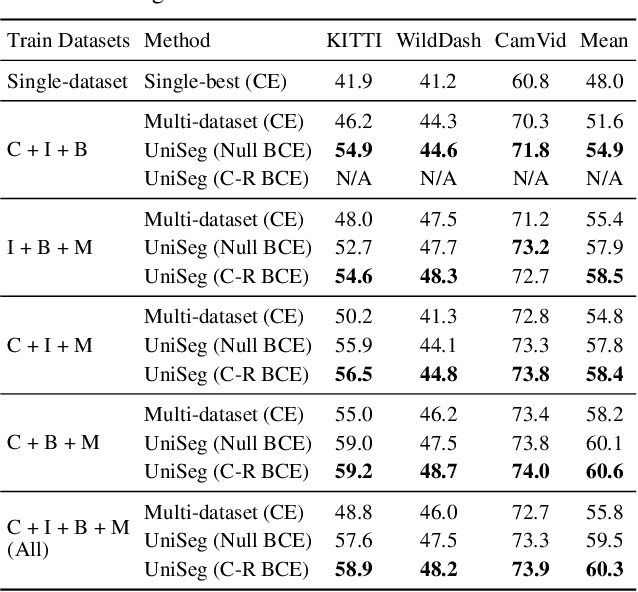
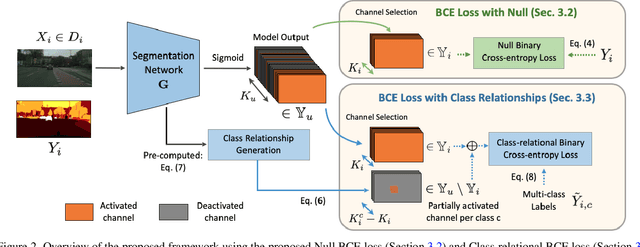
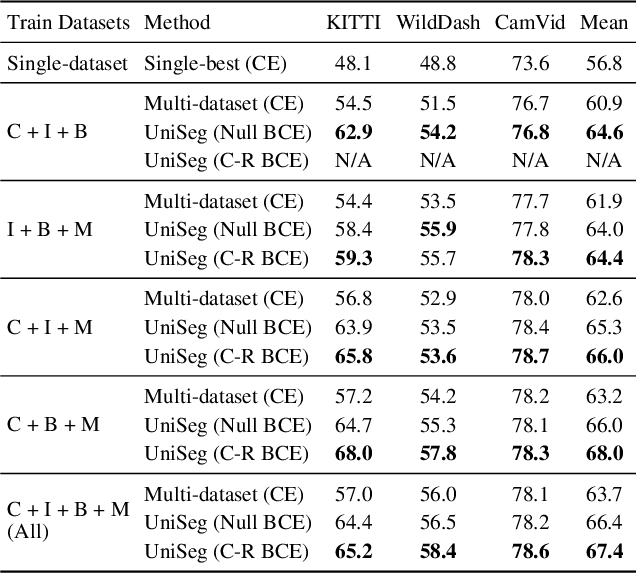
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.
Cross-Domain Similarity Learning for Face Recognition in Unseen Domains
Mar 12, 2021



Face recognition models trained under the assumption of identical training and test distributions often suffer from poor generalization when faced with unknown variations, such as a novel ethnicity or unpredictable individual make-ups during test time. In this paper, we introduce a novel cross-domain metric learning loss, which we dub Cross-Domain Triplet (CDT) loss, to improve face recognition in unseen domains. The CDT loss encourages learning semantically meaningful features by enforcing compact feature clusters of identities from one domain, where the compactness is measured by underlying similarity metrics that belong to another training domain with different statistics. Intuitively, it discriminatively correlates explicit metrics derived from one domain, with triplet samples from another domain in a unified loss function to be minimized within a network, which leads to better alignment of the training domains. The network parameters are further enforced to learn generalized features under domain shift, in a model-agnostic learning pipeline. Unlike the recent work of Meta Face Recognition, our method does not require careful hard-pair sample mining and filtering strategy during training. Extensive experiments on various face recognition benchmarks show the superiority of our method in handling variations, compared to baseline and the state-of-the-art methods.
Voting-based Approaches For Differentially Private Federated Learning
Oct 09, 2020


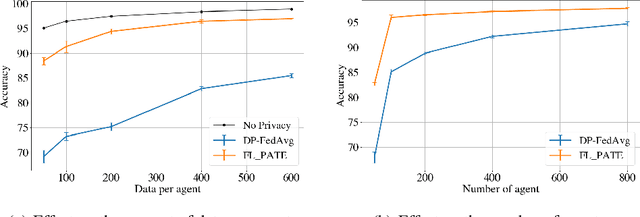
While federated learning (FL) enables distributed agents to collaboratively train a centralized model without sharing data with each other, it fails to protect users against inference attacks that mine private information from the centralized model. Thus, facilitating federated learning methods with differential privacy (DPFL) becomes attractive. Existing algorithms based on privately aggregating clipped gradients require many rounds of communication, which may not converge, and cannot scale up to large-capacity models due to explicit dimension-dependence in its added noise. In this paper, we adopt the knowledge transfer model of private learning pioneered by Papernot et al. (2017; 2018) and extend their algorithm PATE, as well as the recent alternative PrivateKNN (Zhu et al., 2020) to the federated learning setting. The key difference is that our method privately aggregates the labels from the agents in a voting scheme, instead of aggregating the gradients, hence avoiding the dimension dependence and achieving significant savings in communication cost. Theoretically, we show that when the margins of the voting scores are large, the agents enjoy exponentially higher accuracy and stronger (data-dependent) differential privacy guarantees on both agent-level and instance-level. Extensive experiments show that our approach significantly improves the privacy-utility trade-off over the current state-of-the-art in DPFL.
Learning Factorized Representations for Open-set Domain Adaptation
May 31, 2018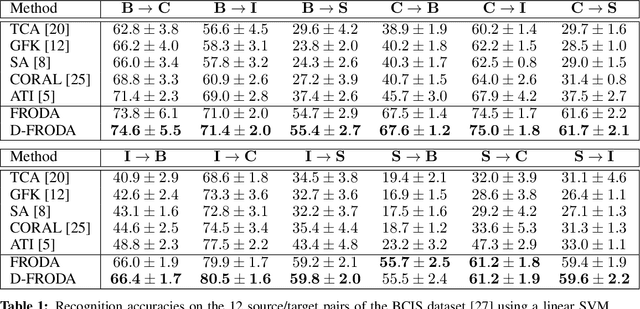
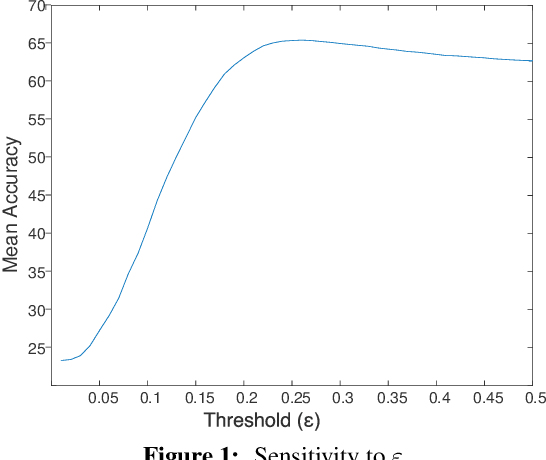


Domain adaptation for visual recognition has undergone great progress in the past few years. Nevertheless, most existing methods work in the so-called closed-set scenario, assuming that the classes depicted by the target images are exactly the same as those of the source domain. In this paper, we tackle the more challenging, yet more realistic case of open-set domain adaptation, where new, unknown classes can be present in the target data. While, in the unsupervised scenario, one cannot expect to be able to identify each specific new class, we aim to automatically detect which samples belong to these new classes and discard them from the recognition process. To this end, we rely on the intuition that the source and target samples depicting the known classes can be generated by a shared subspace, whereas the target samples from unknown classes come from a different, private subspace. We therefore introduce a framework that factorizes the data into shared and private parts, while encouraging the shared representation to be discriminative. Our experiments on standard benchmarks evidence that our approach significantly outperforms the state-of-the-art in open-set domain adaptation.
Log-Euclidean Bag of Words for Human Action Recognition
Jul 07, 2016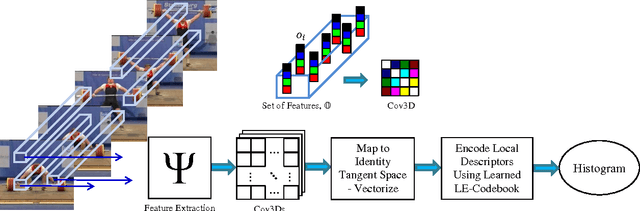

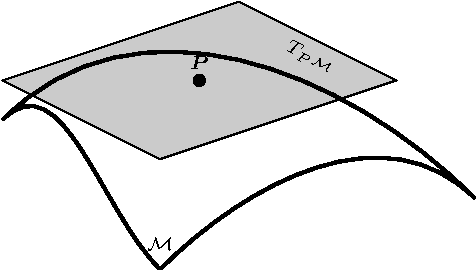

Representing videos by densely extracted local space-time features has recently become a popular approach for analysing actions. In this paper, we tackle the problem of categorising human actions by devising Bag of Words (BoW) models based on covariance matrices of spatio-temporal features, with the features formed from histograms of optical flow. Since covariance matrices form a special type of Riemannian manifold, the space of Symmetric Positive Definite (SPD) matrices, non-Euclidean geometry should be taken into account while discriminating between covariance matrices. To this end, we propose to embed SPD manifolds to Euclidean spaces via a diffeomorphism and extend the BoW approach to its Riemannian version. The proposed BoW approach takes into account the manifold geometry of SPD matrices during the generation of the codebook and histograms. Experiments on challenging human action datasets show that the proposed method obtains notable improvements in discrimination accuracy, in comparison to several state-of-the-art methods.