 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Segmentation from Multiple Datasets with Label Shifts
Paper and Code
Feb 28, 2022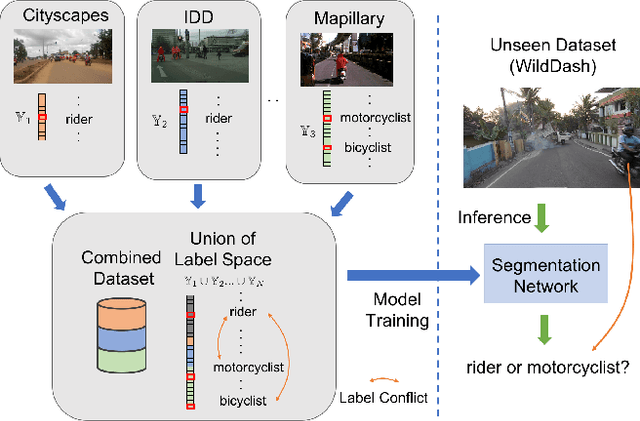
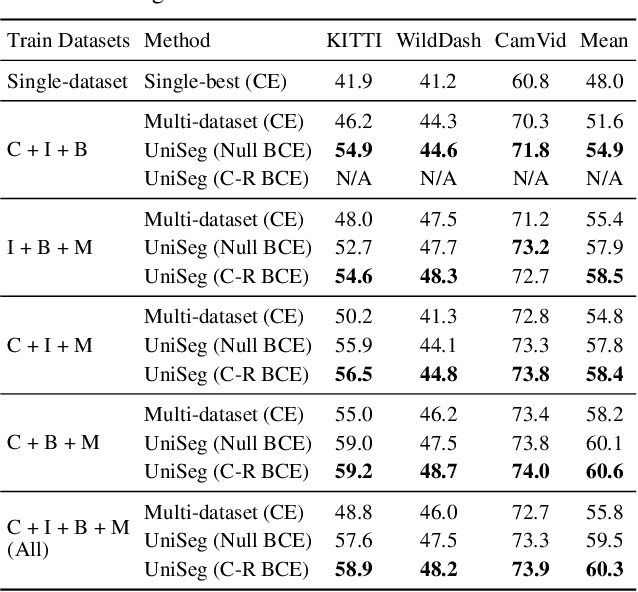
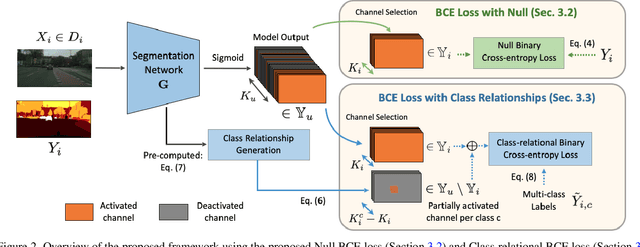
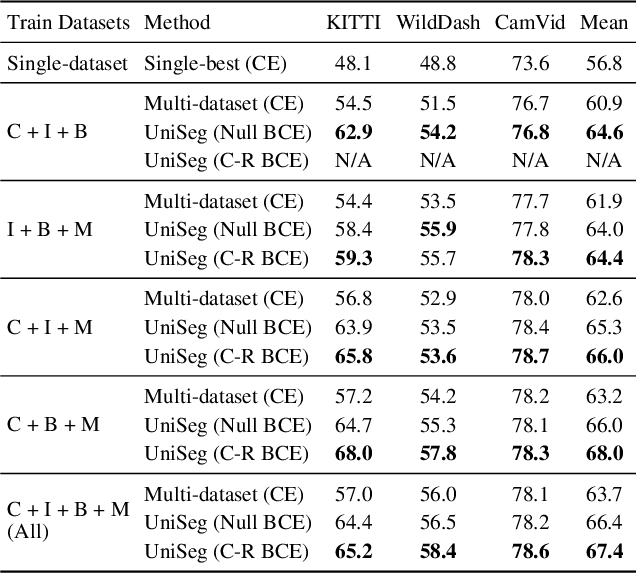
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.