 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Visual Information Processing in Multimodal LLMs
Nov 13, 2025
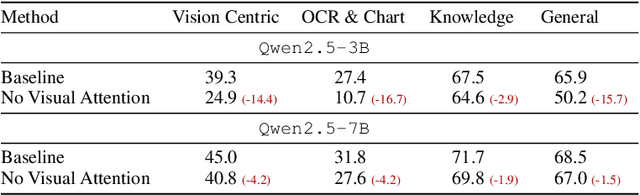
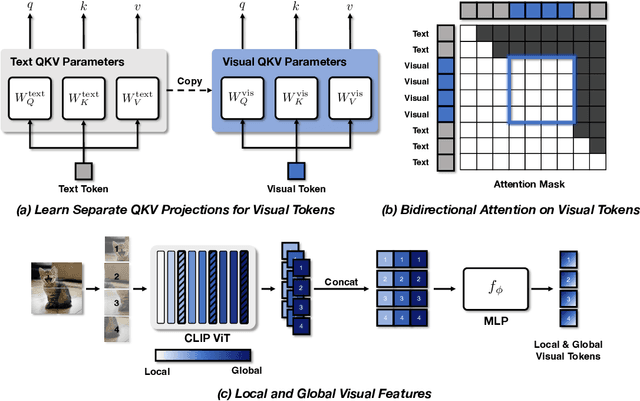
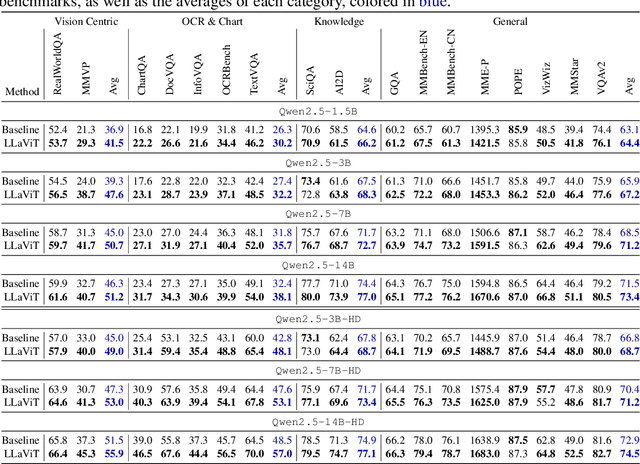
Despite the remarkable success of the LLaVA architecture for vision-language tasks, its design inherently struggles to effectively integrate visual features due to the inherent mismatch between text and vision modalities. We tackle this issue from a novel perspective in which the LLM not only serves as a language model but also a powerful vision encoder. To this end, we present LLaViT - Large Language Models as extended Vision Transformers - which enables the LLM to simultaneously function as a vision encoder through three key modifications: (1) learning separate QKV projections for vision modality, (2) enabling bidirectional attention on visual tokens, and (3) incorporating both global and local visual representations. Through extensive controlled experiments on a wide range of LLMs, we demonstrate that LLaViT significantly outperforms the baseline LLaVA method on a multitude of benchmarks, even surpassing models with double its parameter count, establishing a more effective approach to vision-language modeling.
Revisiting Machine Unlearning with Dimensional Alignment
Jul 25, 2024



Machine unlearning, an emerging research topic focusing on compliance with data privacy regulations, enables trained models to remove the information learned from specific data. While many existing methods indirectly address this issue by intentionally injecting incorrect supervisions, they can drastically and unpredictably alter the decision boundaries and feature spaces, leading to training instability and undesired side effects. To fundamentally approach this task, we first analyze the changes in latent feature spaces between original and retrained models, and observe that the feature representations of samples not involved in training are closely aligned with the feature manifolds of previously seen samples in training. Based on these findings, we introduce a novel evaluation metric for machine unlearning, coined dimensional alignment, which measures the alignment between the eigenspaces of the forget and retain set samples. We employ this metric as a regularizer loss to build a robust and stable unlearning framework, which is further enhanced by integrating a self-distillation loss and an alternating training scheme. Our framework effectively eliminates information from the forget set and preserves knowledge from the retain set. Lastly, we identify critical flaws in established evaluation metrics for machine unlearning, and introduce new evaluation tools that more accurately reflect the fundamental goals of machine unlearning.
On the Stability-Plasticity Dilemma of Class-Incremental Learning
Apr 04, 2023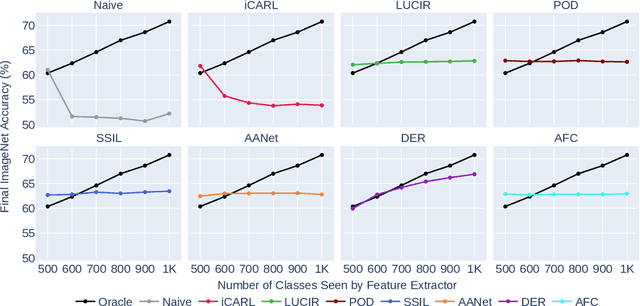

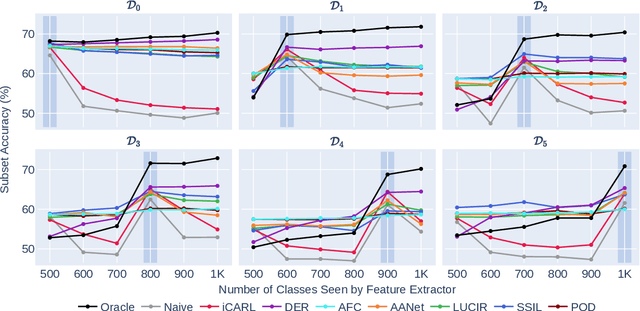

A primary goal of class-incremental learning is to strike a balance between stability and plasticity, where models should be both stable enough to retain knowledge learned from previously seen classes, and plastic enough to learn concepts from new classes. While previous works demonstrate strong performance on class-incremental benchmarks, it is not clear whether their success comes from the models being stable, plastic, or a mixture of both. This paper aims to shed light on how effectively recent class-incremental learning algorithms address the stability-plasticity trade-off. We establish analytical tools that measure the stability and plasticity of feature representations, and employ such tools to investigate models trained with various algorithms on large-scale class-incremental benchmarks. Surprisingly, we find that the majority of class-incremental learning algorithms heavily favor stability over plasticity, to the extent that the feature extractor of a model trained on the initial set of classes is no less effective than that of the final incremental model. Our observations not only inspire two simple algorithms that highlight the importance of feature representation analysis, but also suggest that class-incremental learning approaches, in general, should strive for better feature representation learning.
Learning Semantic Segmentation from Multiple Datasets with Label Shifts
Feb 28, 2022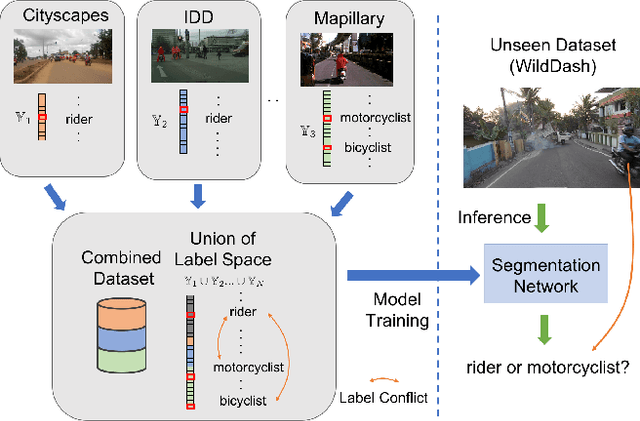
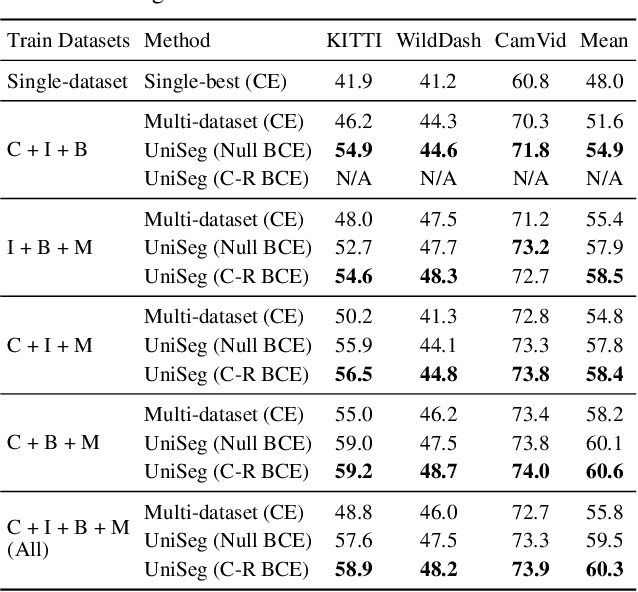
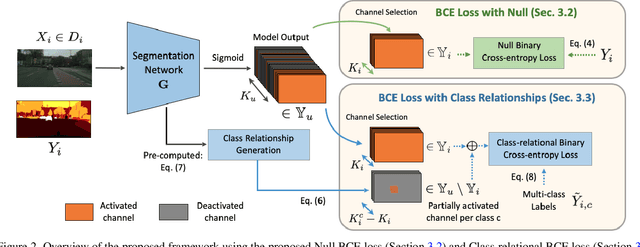
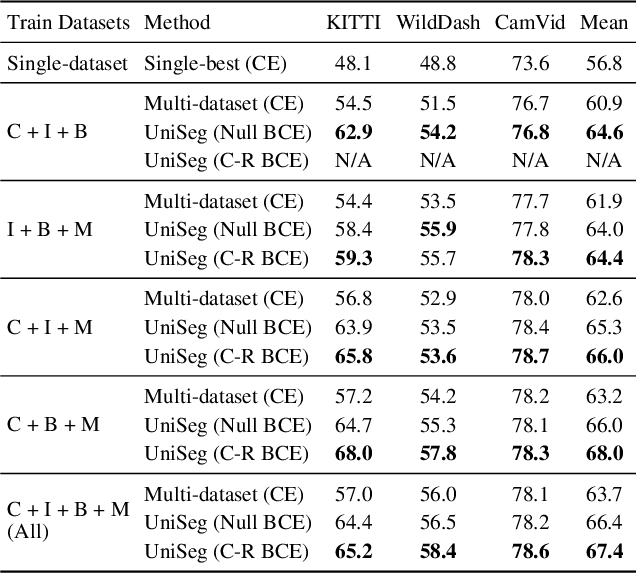
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.
Learning Debiased and Disentangled Representations for Semantic Segmentation
Oct 31, 2021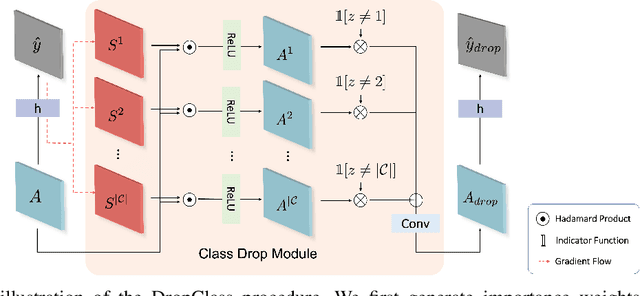
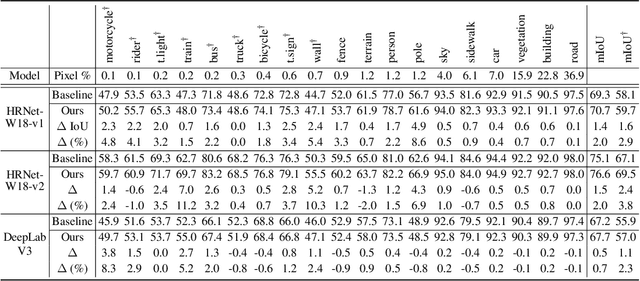
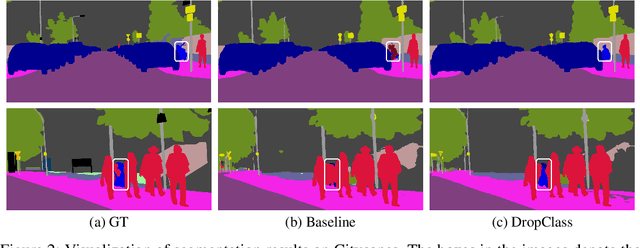

Deep neural networks are susceptible to learn biased models with entangled feature representations, which may lead to subpar performances on various downstream tasks. This is particularly true for under-represented classes, where a lack of diversity in the data exacerbates the tendency. This limitation has been addressed mostly in classification tasks, but there is little study on additional challenges that may appear in more complex dense prediction problems including semantic segmentation. To this end, we propose a model-agnostic and stochastic training scheme for semantic segmentation, which facilitates the learning of debiased and disentangled representations. For each class, we first extract class-specific information from the highly entangled feature map. Then, information related to a randomly sampled class is suppressed by a feature selection process in the feature space. By randomly eliminating certain class information in each training iteration, we effectively reduce feature dependencies among classes, and the model is able to learn more debiased and disentangled feature representations. Models trained with our approach demonstrate strong results on multiple semantic segmentation benchmarks, with especially notable performance gains on under-represented classes.
Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation
Oct 12, 2019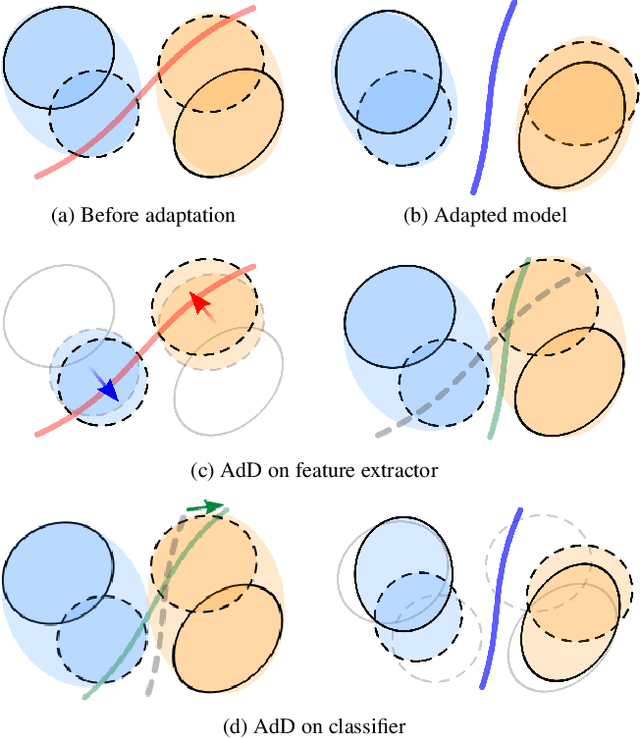
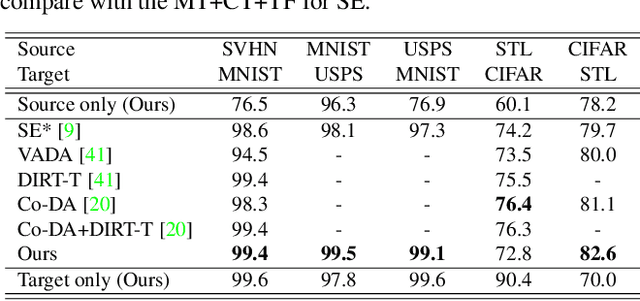
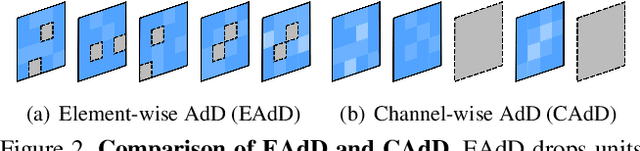
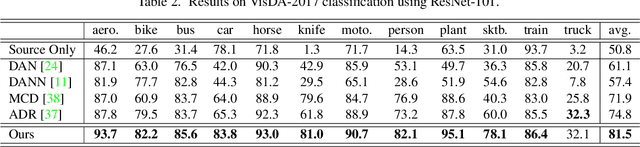
Recent works on domain adaptation exploit adversarial training to obtain domain-invariant feature representations from the joint learning of feature extractor and domain discriminator networks. However, domain adversarial methods render suboptimal performances since they attempt to match the distributions among the domains without considering the task at hand. We propose Drop to Adapt (DTA), which leverages adversarial dropout to learn strongly discriminative features by enforcing the cluster assumption. Accordingly, we design objective functions to support robust domain adaptation. We demonstrate efficacy of the proposed method on various experiments and achieve consistent improvements in both image classification and semantic segmentation tasks. Our source code is available at https://github.com/postBG/DTA.pytorch.
Learning to Optimize Domain Specific Normalization for Domain Generalization
Jul 09, 2019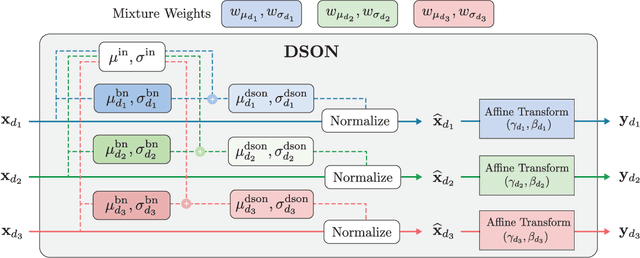
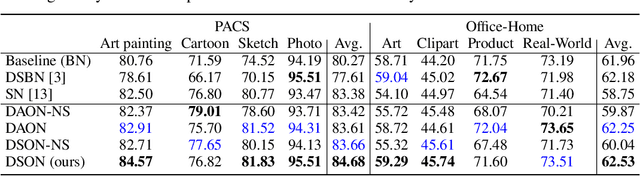
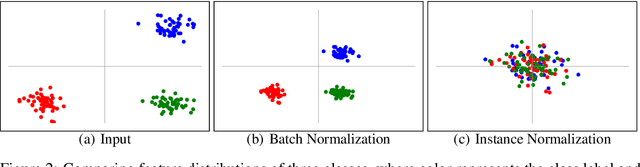
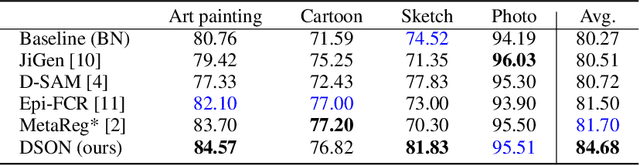
We propose a simple but effective multi-source domain generalization technique based on deep neural networks by incorporating optimized normalization layers specific to individual domains. Our key idea is to decompose discriminative representations in each domain into domain-agnostic and domain-specific components by learning a mixture of multiple normalization types. Because each domain has different characteristics, we optimize the mixture weights specialized to each domain and maximize the generalizability of the learned representations per domain. To this end, we incorporate instance normalization into the network with batch normalization since instance normalization is effective to discard the discriminative domain-specific representations. Since the joint optimization of the parameters in convolutional and normalization layers is not straightforward especially in the lower layers, the mixture weight of the normalization types is shared across all layers for the robustness of trained models. We analyze the effectiveness of the optimized normalization layers and demonstrate the state-of-the-art accuracy of our algorithm in the standard benchmark datasets in various settings.