 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForbes: Face Obfuscation Rendering via Backpropagation Refinement Scheme
Jul 19, 2024



A novel algorithm for face obfuscation, called Forbes, which aims to obfuscate facial appearance recognizable by humans but preserve the identity and attributes decipherable by machines, is proposed in this paper. Forbes first applies multiple obfuscating transformations with random parameters to an image to remove the identity information distinguishable by humans. Then, it optimizes the parameters to make the transformed image decipherable by machines based on the backpropagation refinement scheme. Finally, it renders an obfuscated image by applying the transformations with the optimized parameters. Experimental results on various datasets demonstrate that Forbes achieves both human indecipherability and machine decipherability excellently. The source codes are available at https://github.com/mcljtkim/Forbes.
Eigenlanes: Data-Driven Lane Descriptors for Structurally Diverse Lanes
Mar 29, 2022
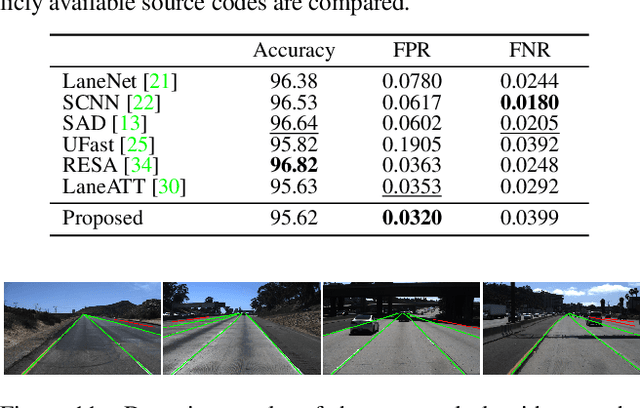
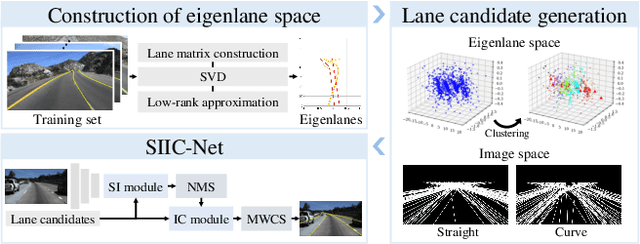
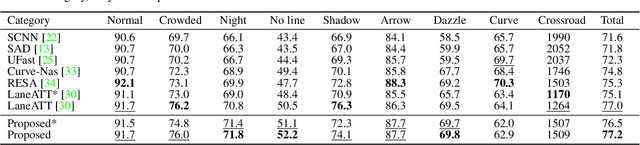
A novel algorithm to detect road lanes in the eigenlane space is proposed in this paper. First, we introduce the notion of eigenlanes, which are data-driven descriptors for structurally diverse lanes, including curved, as well as straight, lanes. To obtain eigenlanes, we perform the best rank-M approximation of a lane matrix containing all lanes in a training set. Second, we generate a set of lane candidates by clustering the training lanes in the eigenlane space. Third, using the lane candidates, we determine an optimal set of lanes by developing an anchor-based detection network, called SIIC-Net. Experimental results demonstrate that the proposed algorithm provides excellent detection performance for structurally diverse lanes. Our codes are available at https://github.com/dongkwonjin/Eigenlanes.
Harmonious Semantic Line Detection via Maximal Weight Clique Selection
Apr 14, 2021

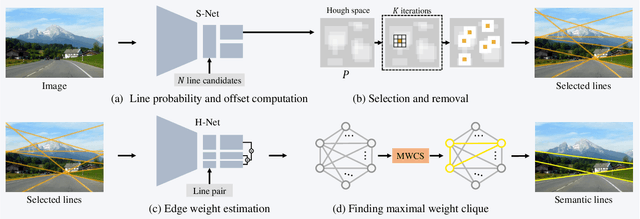

A novel algorithm to detect an optimal set of semantic lines is proposed in this work. We develop two networks: selection network (S-Net) and harmonization network (H-Net). First, S-Net computes the probabilities and offsets of line candidates. Second, we filter out irrelevant lines through a selection-and-removal process. Third, we construct a complete graph, whose edge weights are computed by H-Net. Finally, we determine a maximal weight clique representing an optimal set of semantic lines. Moreover, to assess the overall harmony of detected lines, we propose a novel metric, called HIoU. Experimental results demonstrate that the proposed algorithm can detect harmonious semantic lines effectively and efficiently. Our codes are available at https://github.com/dongkwonjin/Semantic-Line-MWCS.
Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation
Oct 12, 2019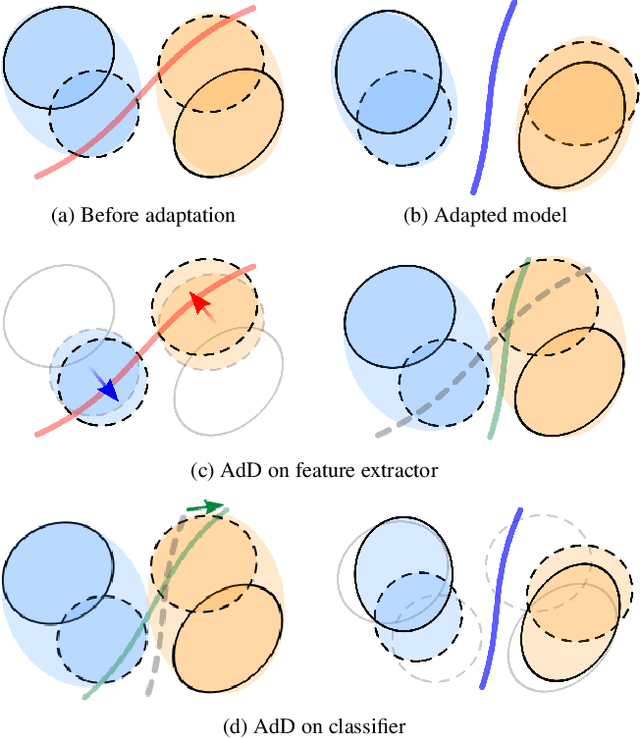
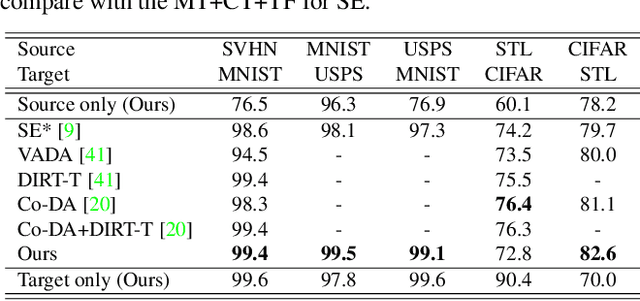
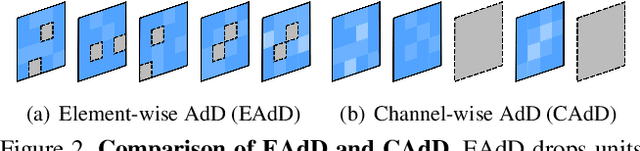
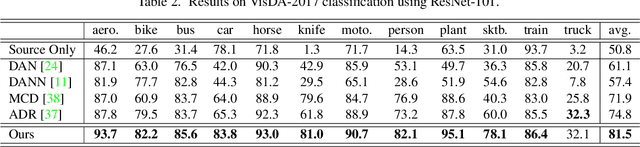
Recent works on domain adaptation exploit adversarial training to obtain domain-invariant feature representations from the joint learning of feature extractor and domain discriminator networks. However, domain adversarial methods render suboptimal performances since they attempt to match the distributions among the domains without considering the task at hand. We propose Drop to Adapt (DTA), which leverages adversarial dropout to learn strongly discriminative features by enforcing the cluster assumption. Accordingly, we design objective functions to support robust domain adaptation. We demonstrate efficacy of the proposed method on various experiments and achieve consistent improvements in both image classification and semantic segmentation tasks. Our source code is available at https://github.com/postBG/DTA.pytorch.
Anchor Loss: Modulating Loss Scale based on Prediction Difficulty
Sep 24, 2019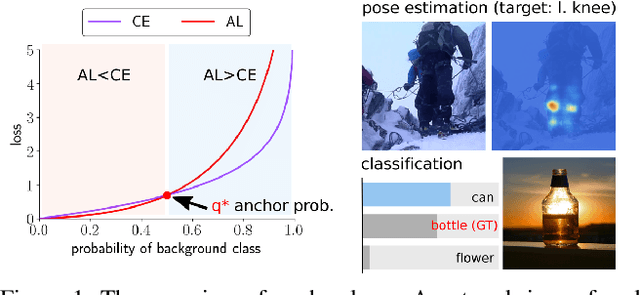
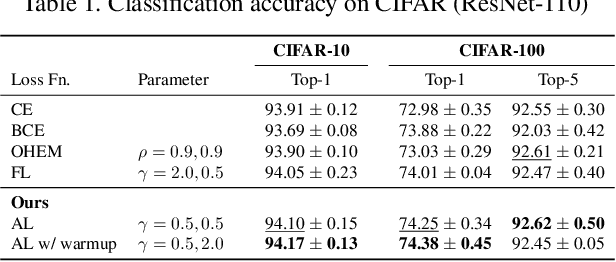


We propose a novel loss function that dynamically rescales the cross entropy based on prediction difficulty regarding a sample. Deep neural network architectures in image classification tasks struggle to disambiguate visually similar objects. Likewise, in human pose estimation symmetric body parts often confuse the network with assigning indiscriminative scores to them. This is due to the output prediction, in which only the highest confidence label is selected without taking into consideration a measure of uncertainty. In this work, we define the prediction difficulty as a relative property coming from the confidence score gap between positive and negative labels. More precisely, the proposed loss function penalizes the network to avoid the score of a false prediction being significant. To demonstrate the efficacy of our loss function, we evaluate it on two different domains: image classification and human pose estimation. We find improvements in both applications by achieving higher accuracy compared to the baseline methods.
End-to-end Learning of Image based Lane-Change Decision
Jun 26, 2017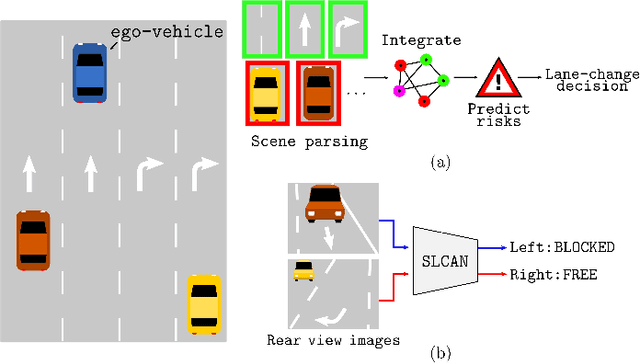

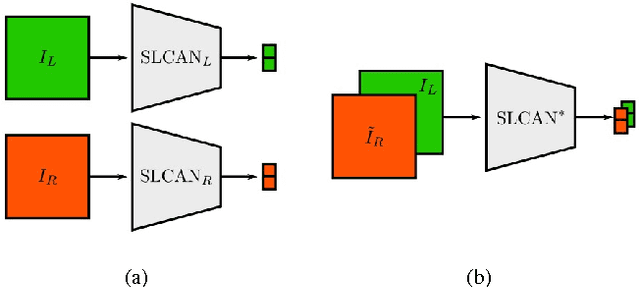
We propose an image based end-to-end learning framework that helps lane-change decisions for human drivers and autonomous vehicles. The proposed system, Safe Lane-Change Aid Network (SLCAN), trains a deep convolutional neural network to classify the status of adjacent lanes from rear view images acquired by cameras mounted on both sides of the vehicle. Rather than depending on any explicit object detection or tracking scheme, SLCAN reads the whole input image and directly decides whether initiation of the lane-change at the moment is safe or not. We collected and annotated 77,273 rear side view images to train and test SLCAN. Experimental results show that the proposed framework achieves 96.98% classification accuracy although the test images are from unseen roadways. We also visualize the saliency map to understand which part of image SLCAN looks at for correct decisions.
Progressive Tree-like Curvilinear Structure Reconstruction with Structured Ranking Learning and Graph Algorithm
Dec 08, 2016
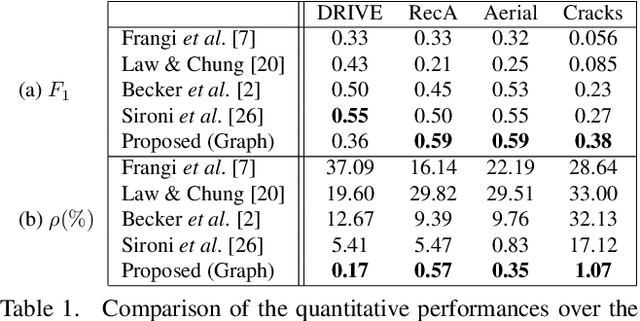

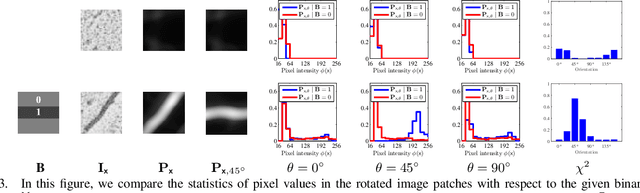
We propose a novel tree-like curvilinear structure reconstruction algorithm based on supervised learning and graph theory. In this work we analyze image patches to obtain the local major orientations and the rankings that correspond to the curvilinear structure. To extract local curvilinear features, we compute oriented gradient information using steerable filters. We then employ Structured Support Vector Machine for ordinal regression of the input image patches, where the ordering is determined by shape similarity to latent curvilinear structure. Finally, we progressively reconstruct the curvilinear structure by looking for geodesic paths connecting remote vertices in the graph built on the structured output rankings. Experimental results show that the proposed algorithm faithfully provides topological features of the curvilinear structures using minimal pixels for various datasets.