 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter decomposition to resolve class imbalance problem in Hangul OCR
Aug 12, 2022
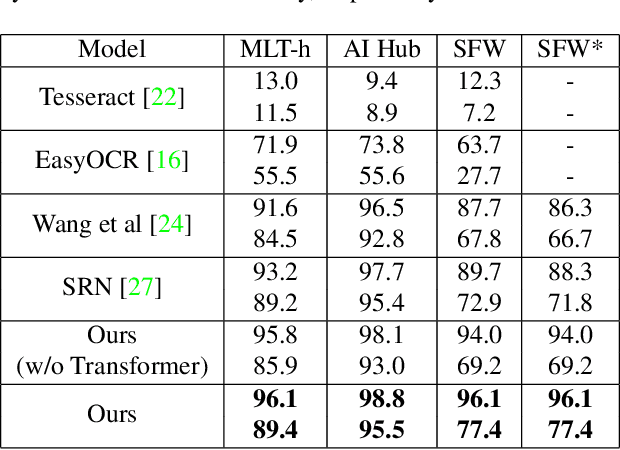
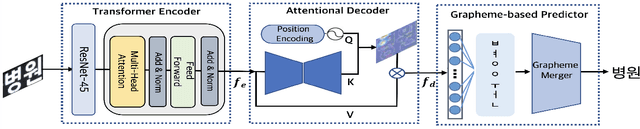

We present a novel approach to OCR(Optical Character Recognition) of Korean character, Hangul. As a phonogram, Hangul can represent 11,172 different characters with only 52 graphemes, by describing each character with a combination of the graphemes. As the total number of the characters could overwhelm the capacity of a neural network, the existing OCR encoding methods pre-define a smaller set of characters that are frequently used. This design choice naturally compromises the performance on long-tailed characters in the distribution. In this work, we demonstrate that grapheme encoding is not only efficient but also performant for Hangul OCR. Benchmark tests show that our approach resolves two main problems of Hangul OCR: class imbalance and target class selection.
Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning
Oct 17, 2021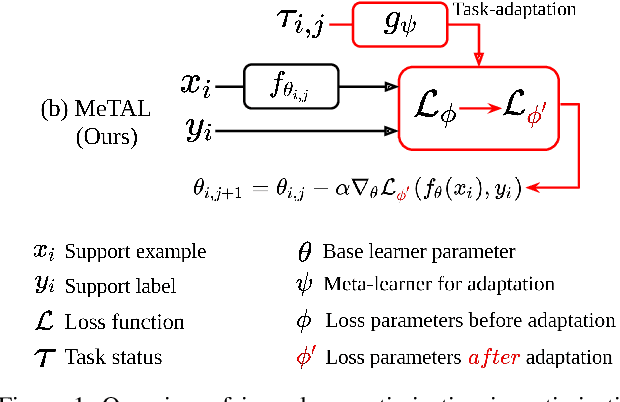
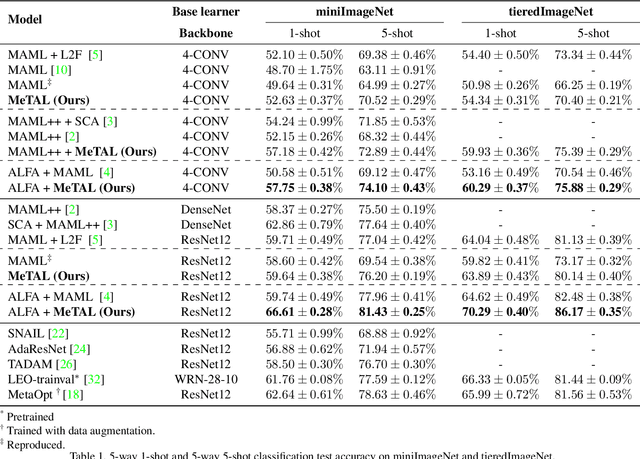
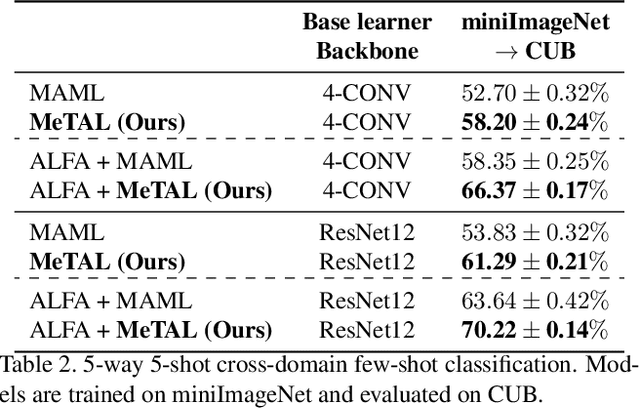
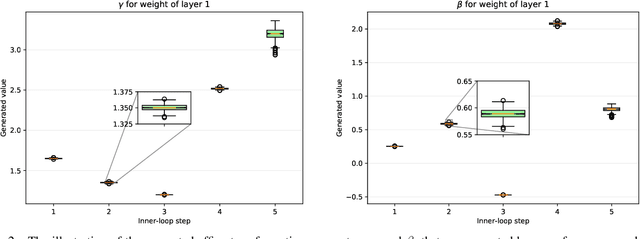
In few-shot learning scenarios, the challenge is to generalize and perform well on new unseen examples when only very few labeled examples are available for each task. Model-agnostic meta-learning (MAML) has gained the popularity as one of the representative few-shot learning methods for its flexibility and applicability to diverse problems. However, MAML and its variants often resort to a simple loss function without any auxiliary loss function or regularization terms that can help achieve better generalization. The problem lies in that each application and task may require different auxiliary loss function, especially when tasks are diverse and distinct. Instead of attempting to hand-design an auxiliary loss function for each application and task, we introduce a new meta-learning framework with a loss function that adapts to each task. Our proposed framework, named Meta-Learning with Task-Adaptive Loss Function (MeTAL), demonstrates the effectiveness and the flexibility across various domains, such as few-shot classification and few-shot regression.
End-to-end Learning of Image based Lane-Change Decision
Jun 26, 2017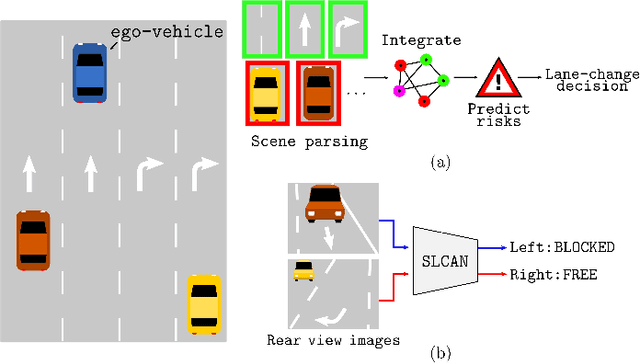

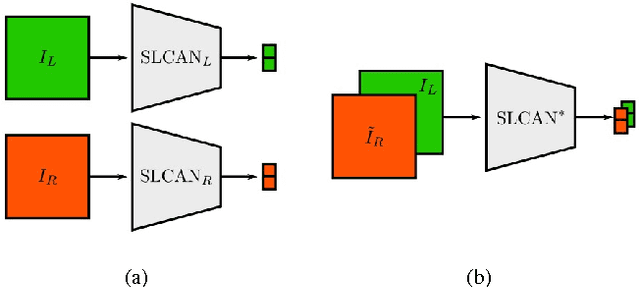
We propose an image based end-to-end learning framework that helps lane-change decisions for human drivers and autonomous vehicles. The proposed system, Safe Lane-Change Aid Network (SLCAN), trains a deep convolutional neural network to classify the status of adjacent lanes from rear view images acquired by cameras mounted on both sides of the vehicle. Rather than depending on any explicit object detection or tracking scheme, SLCAN reads the whole input image and directly decides whether initiation of the lane-change at the moment is safe or not. We collected and annotated 77,273 rear side view images to train and test SLCAN. Experimental results show that the proposed framework achieves 96.98% classification accuracy although the test images are from unseen roadways. We also visualize the saliency map to understand which part of image SLCAN looks at for correct decisions.