 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter decomposition to resolve class imbalance problem in Hangul OCR
Paper and Code

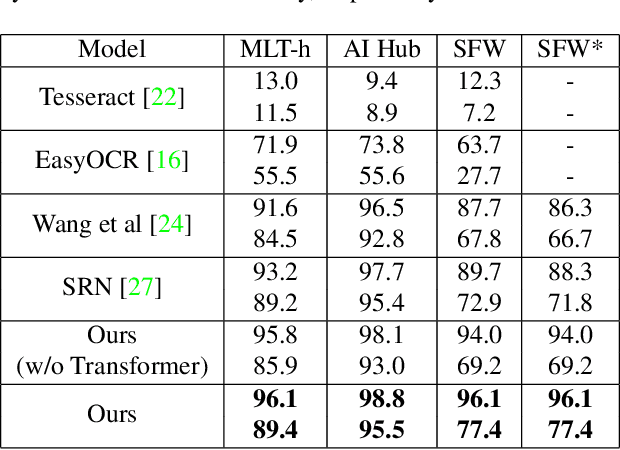
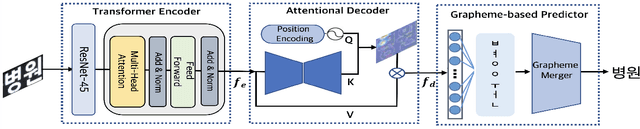

We present a novel approach to OCR(Optical Character Recognition) of Korean character, Hangul. As a phonogram, Hangul can represent 11,172 different characters with only 52 graphemes, by describing each character with a combination of the graphemes. As the total number of the characters could overwhelm the capacity of a neural network, the existing OCR encoding methods pre-define a smaller set of characters that are frequently used. This design choice naturally compromises the performance on long-tailed characters in the distribution. In this work, we demonstrate that grapheme encoding is not only efficient but also performant for Hangul OCR. Benchmark tests show that our approach resolves two main problems of Hangul OCR: class imbalance and target class selection.