 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter decomposition to resolve class imbalance problem in Hangul OCR
Aug 12, 2022
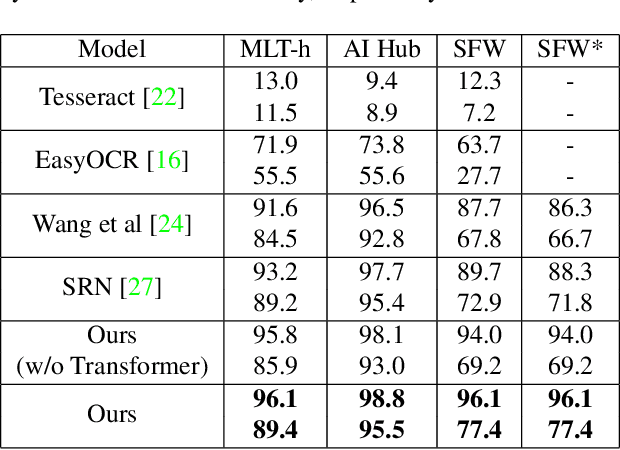
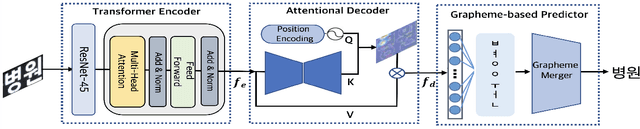

We present a novel approach to OCR(Optical Character Recognition) of Korean character, Hangul. As a phonogram, Hangul can represent 11,172 different characters with only 52 graphemes, by describing each character with a combination of the graphemes. As the total number of the characters could overwhelm the capacity of a neural network, the existing OCR encoding methods pre-define a smaller set of characters that are frequently used. This design choice naturally compromises the performance on long-tailed characters in the distribution. In this work, we demonstrate that grapheme encoding is not only efficient but also performant for Hangul OCR. Benchmark tests show that our approach resolves two main problems of Hangul OCR: class imbalance and target class selection.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022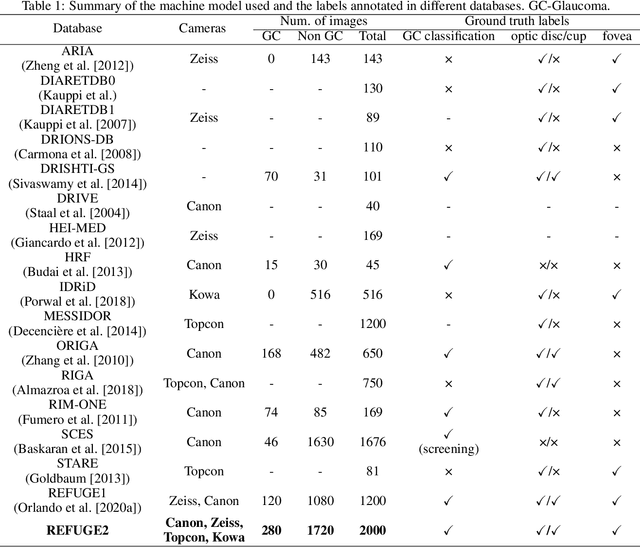
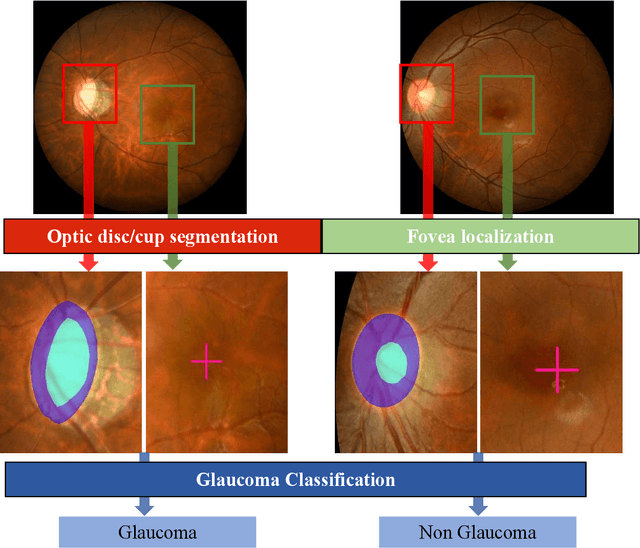
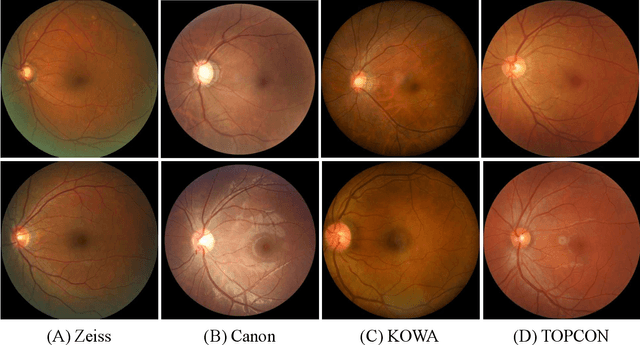
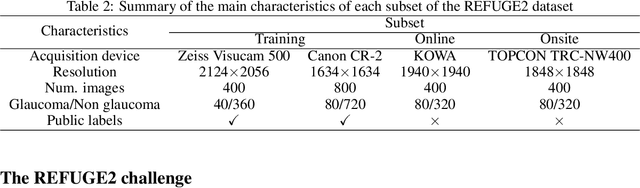
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022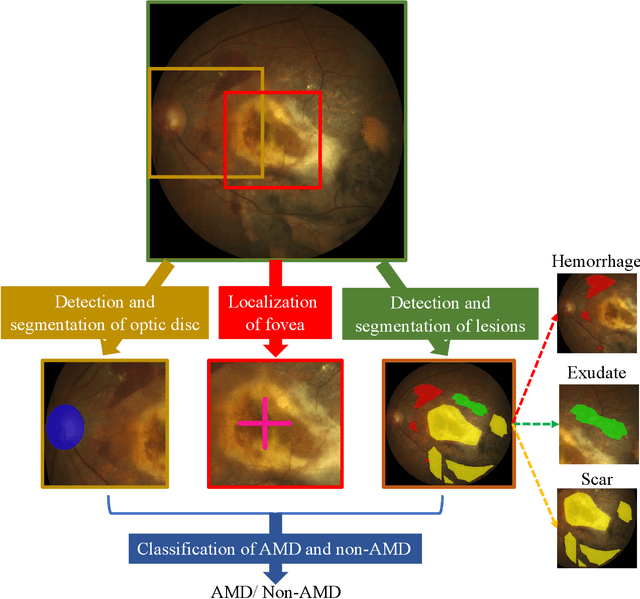

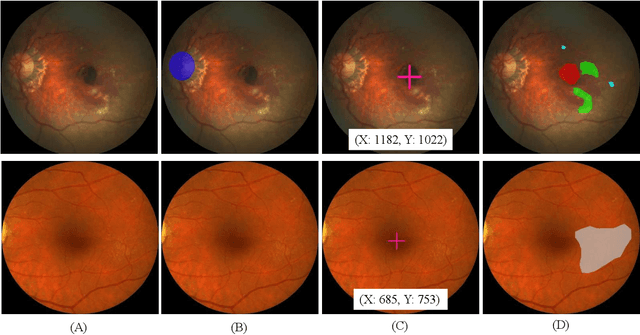
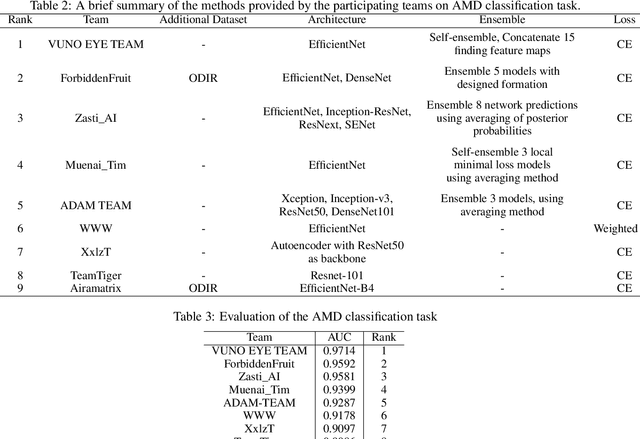
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
The Medical Segmentation Decathlon
Jun 10, 2021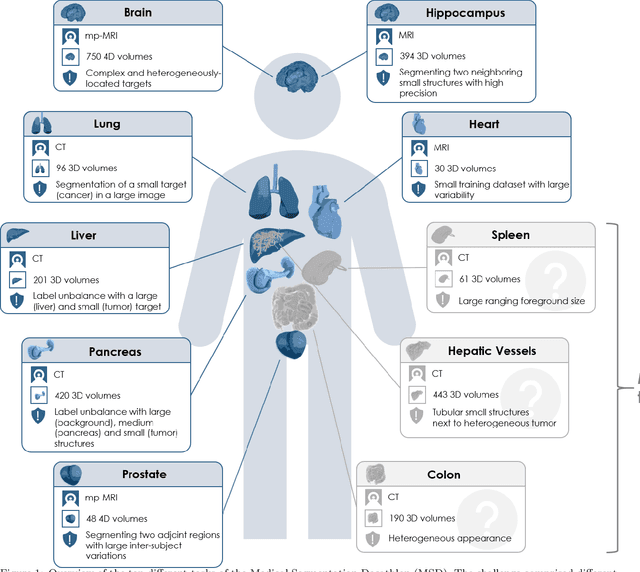
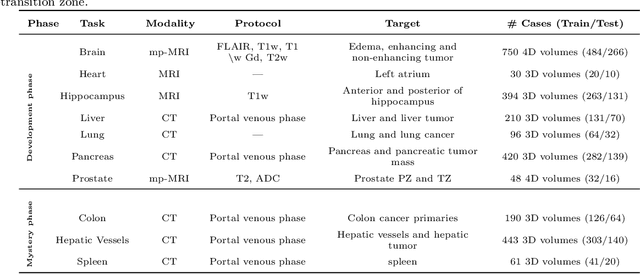
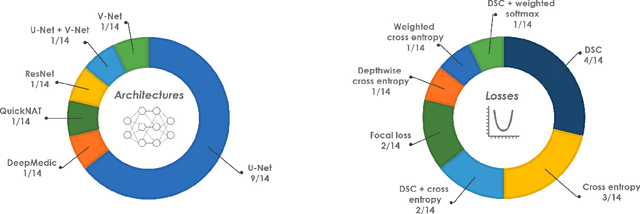
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
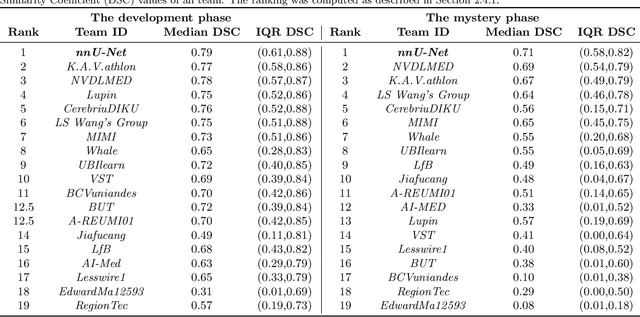
Oct 08, 2019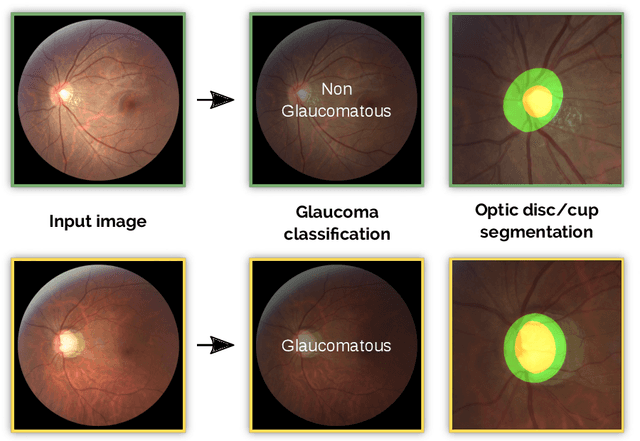
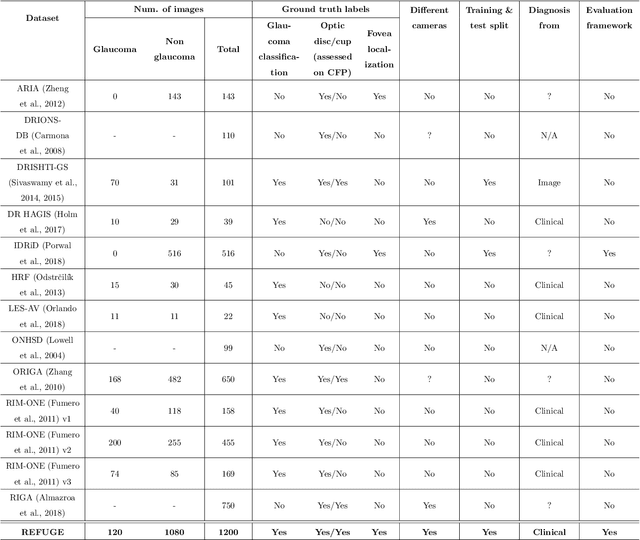

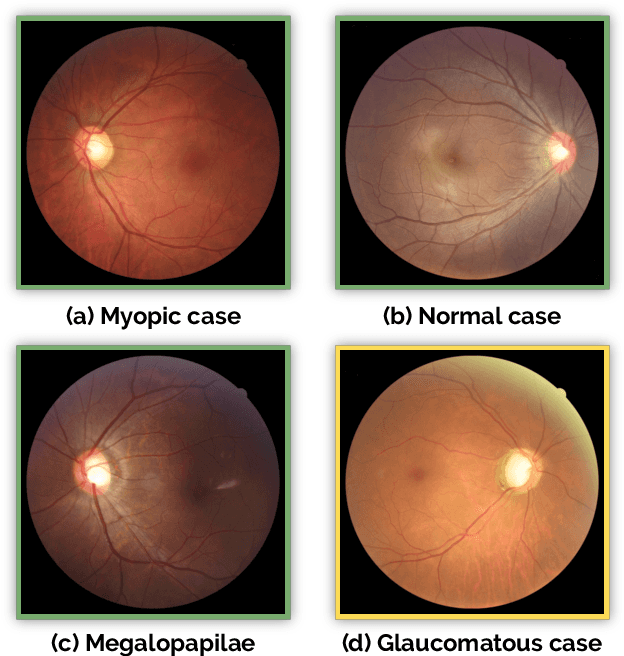
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.
Classification of Findings with Localized Lesions in Fundoscopic Images using a Regionally Guided CNN
Nov 02, 2018
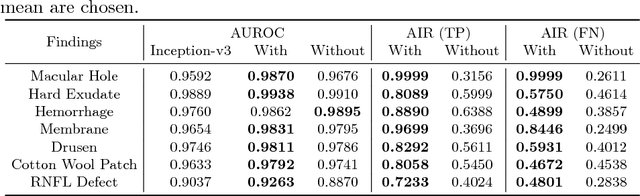
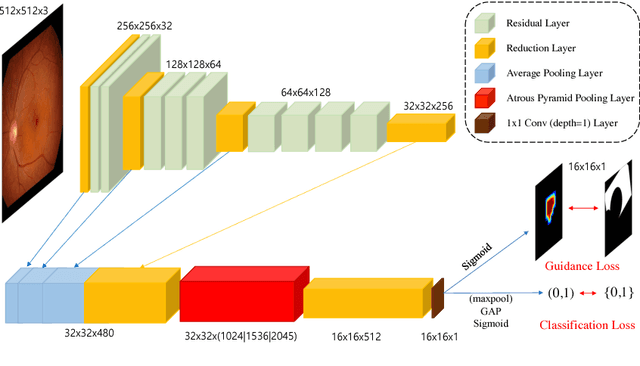
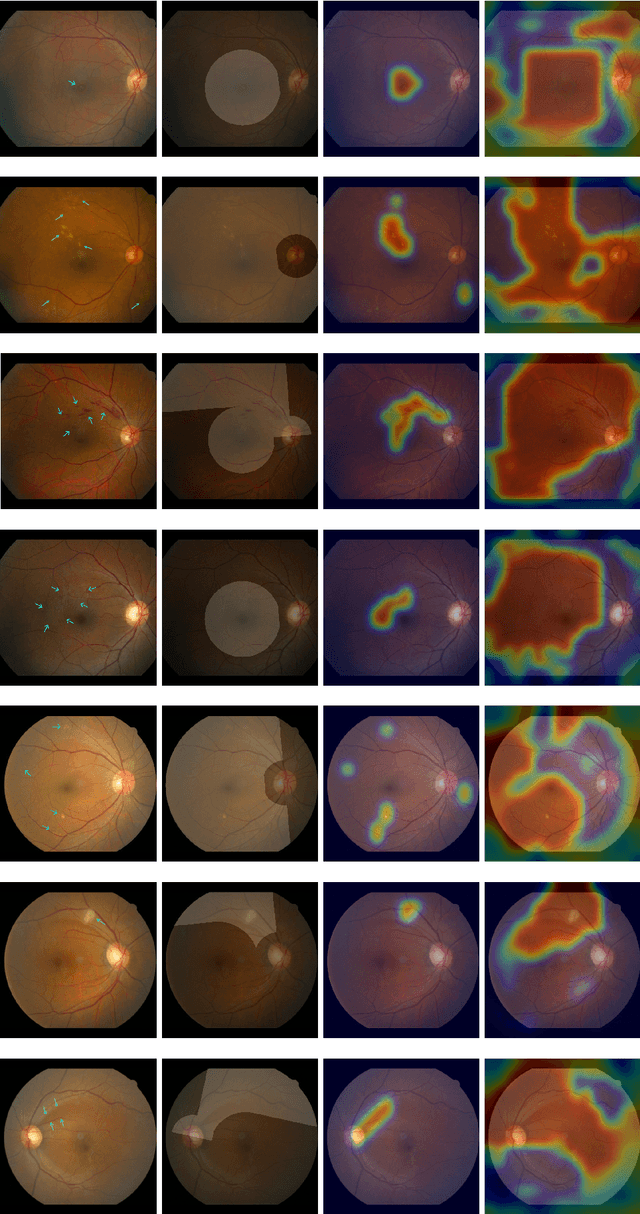
Fundoscopic images are often investigated by ophthalmologists to spot abnormal lesions to make diagnoses. Recent successes of convolutional neural networks are confined to diagnoses of few diseases without proper localization of lesion. In this paper, we propose an efficient annotation method for localizing lesions and a CNN architecture that can classify an individual finding and localize the lesions at the same time. Also, we introduce a new loss function to guide the network to learn meaningful patterns with the guidance of the regional annotations. In experiments, we demonstrate that our network performed better than the widely used network and the guidance loss helps achieve higher AUROC up to 4.1% and superior localization capability.
Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks
Jun 28, 2017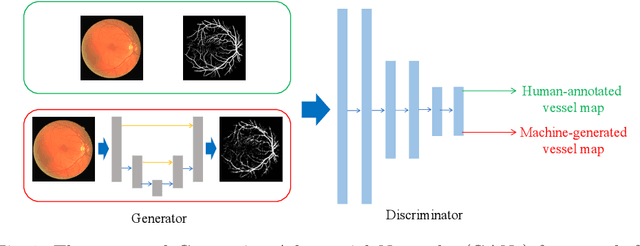
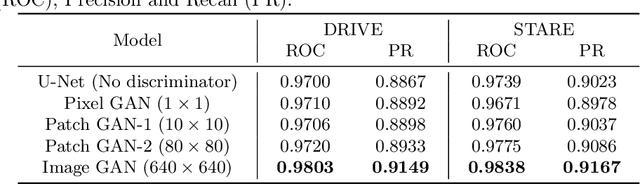
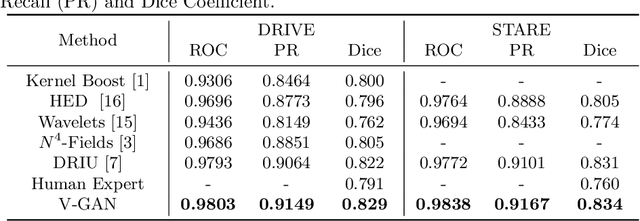
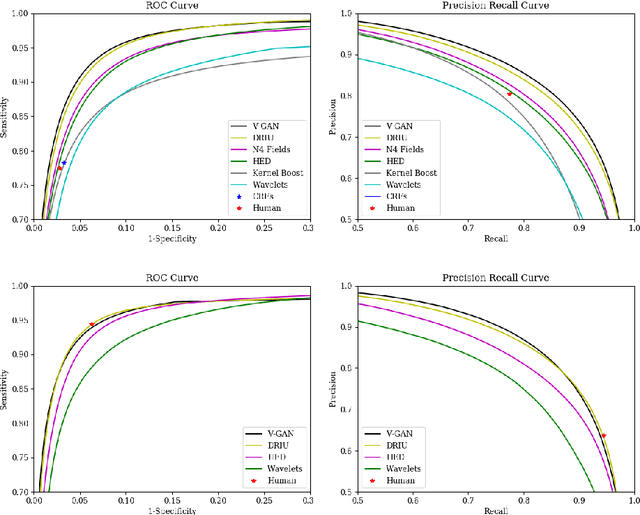
Retinal vessel segmentation is an indispensable step for automatic detection of retinal diseases with fundoscopic images. Though many approaches have been proposed, existing methods tend to miss fine vessels or allow false positives at terminal branches. Let alone under-segmentation, over-segmentation is also problematic when quantitative studies need to measure the precise width of vessels. In this paper, we present a method that generates the precise map of retinal vessels using generative adversarial training. Our methods achieve dice coefficient of 0.829 on DRIVE dataset and 0.834 on STARE dataset which is the state-of-the-art performance on both datasets.