 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022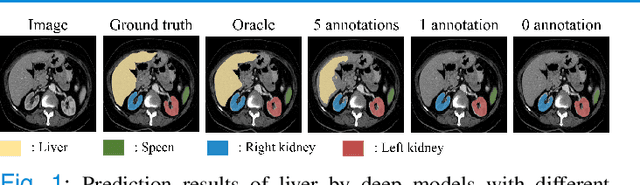
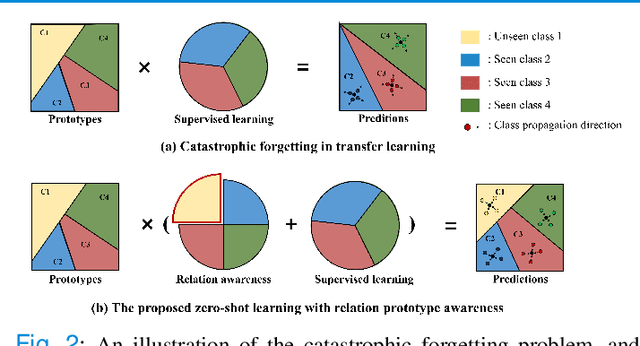
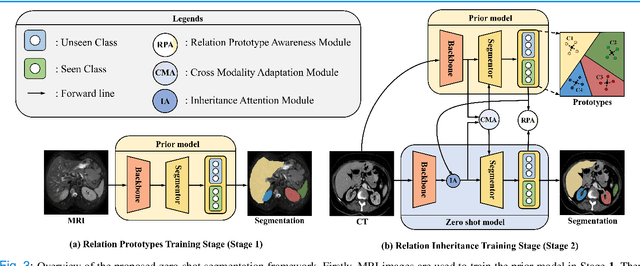
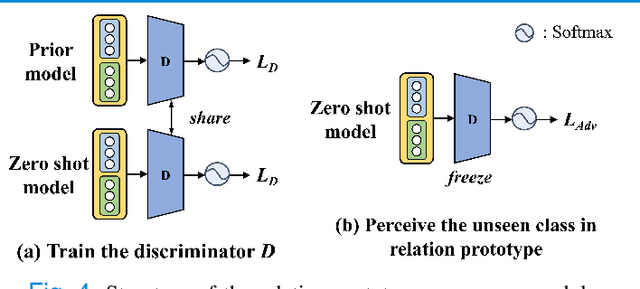
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022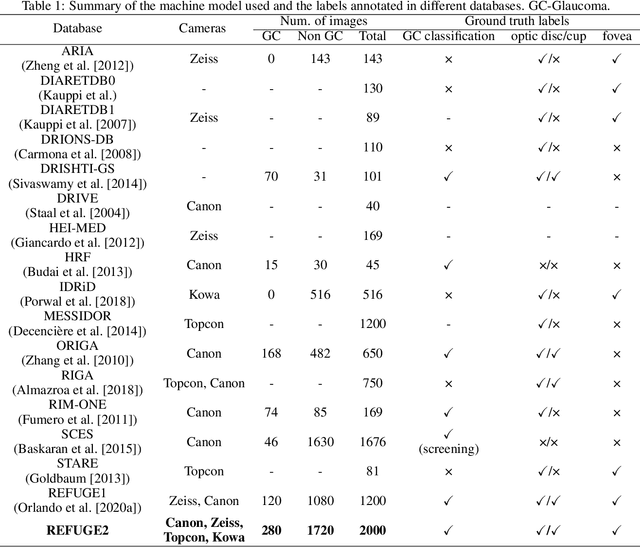
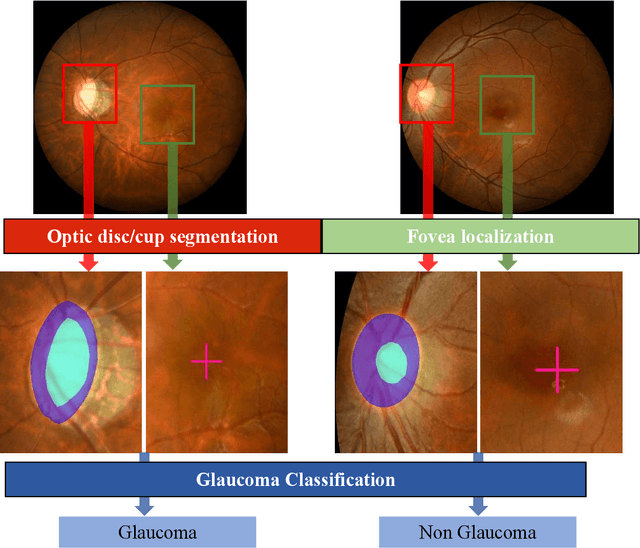
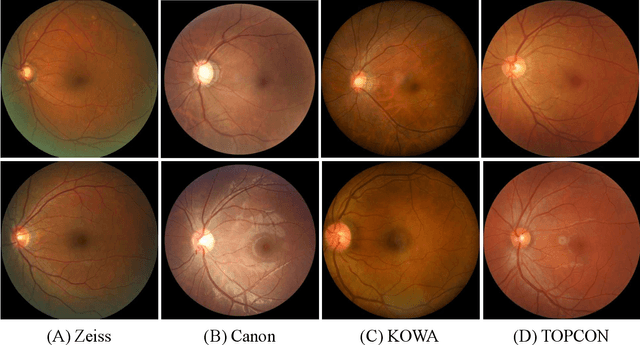
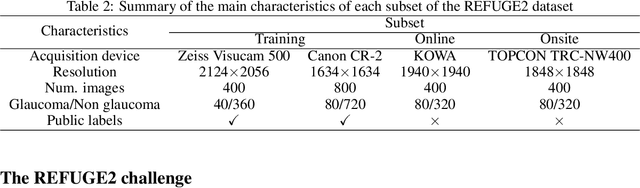
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
Multi-Anchor Active Domain Adaptation for Semantic Segmentation
Aug 18, 2021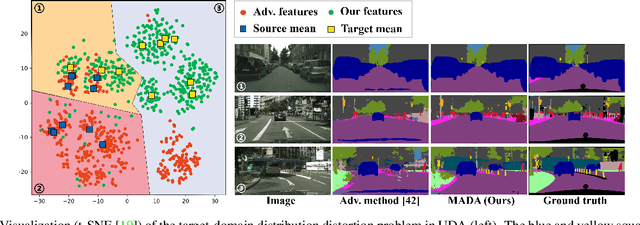
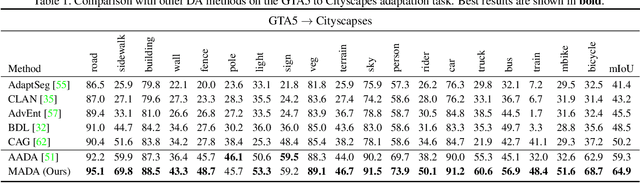
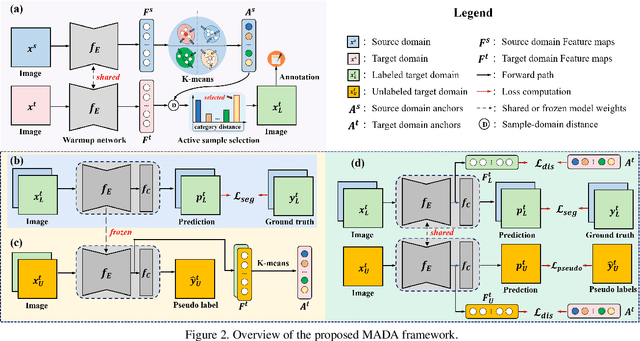
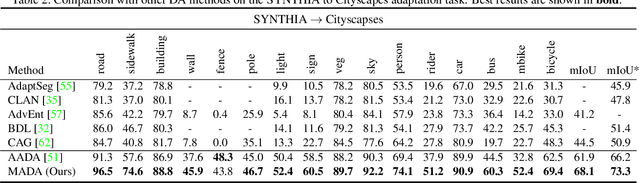
Unsupervised domain adaption has proven to be an effective approach for alleviating the intensive workload of manual annotation by aligning the synthetic source-domain data and the real-world target-domain samples. Unfortunately, mapping the target-domain distribution to the source-domain unconditionally may distort the essential structural information of the target-domain data. To this end, we firstly propose to introduce a novel multi-anchor based active learning strategy to assist domain adaptation regarding the semantic segmentation task. By innovatively adopting multiple anchors instead of a single centroid, the source domain can be better characterized as a multimodal distribution, thus more representative and complimentary samples are selected from the target domain. With little workload to manually annotate these active samples, the distortion of the target-domain distribution can be effectively alleviated, resulting in a large performance gain. The multi-anchor strategy is additionally employed to model the target-distribution. By regularizing the latent representation of the target samples compact around multiple anchors through a novel soft alignment loss, more precise segmentation can be achieved. Extensive experiments are conducted on public datasets to demonstrate that the proposed approach outperforms state-of-the-art methods significantly, along with thorough ablation study to verify the effectiveness of each component.
A New Bidirectional Unsupervised Domain Adaptation Segmentation Framework
Aug 18, 2021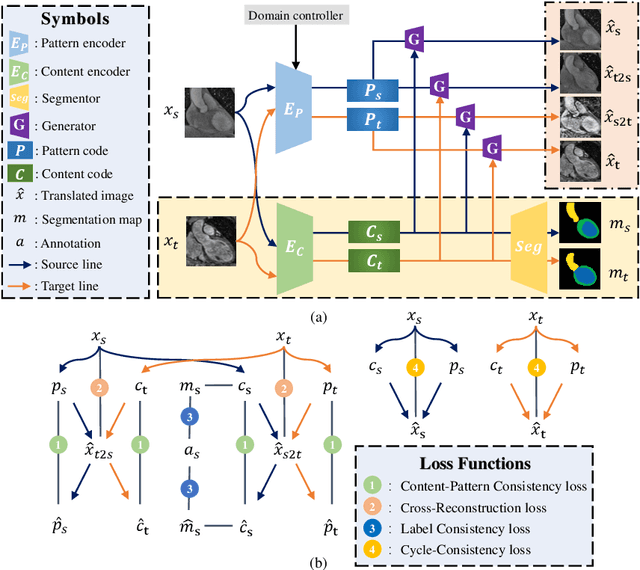
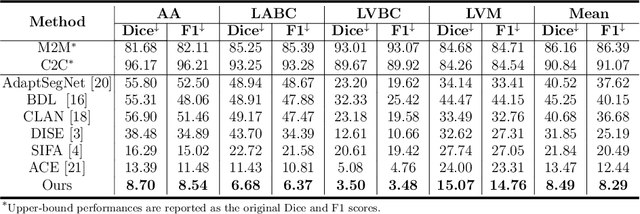
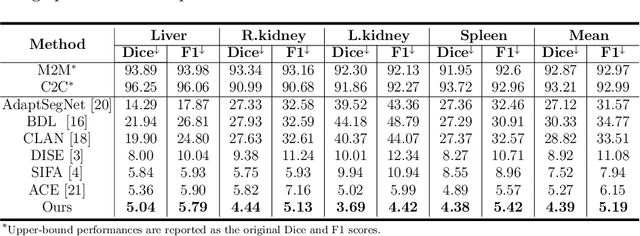
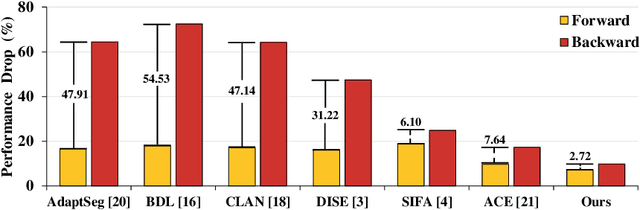
Domain shift happens in cross-domain scenarios commonly because of the wide gaps between different domains: when applying a deep learning model well-trained in one domain to another target domain, the model usually performs poorly. To tackle this problem, unsupervised domain adaptation (UDA) techniques are proposed to bridge the gap between different domains, for the purpose of improving model performance without annotation in the target domain. Particularly, UDA has a great value for multimodal medical image analysis, where annotation difficulty is a practical concern. However, most existing UDA methods can only achieve satisfactory improvements in one adaptation direction (e.g., MRI to CT), but often perform poorly in the other (CT to MRI), limiting their practical usage. In this paper, we propose a bidirectional UDA (BiUDA) framework based on disentangled representation learning for equally competent two-way UDA performances. This framework employs a unified domain-aware pattern encoder which not only can adaptively encode images in different domains through a domain controller, but also improve model efficiency by eliminating redundant parameters. Furthermore, to avoid distortion of contents and patterns of input images during the adaptation process, a content-pattern consistency loss is introduced. Additionally, for better UDA segmentation performance, a label consistency strategy is proposed to provide extra supervision by recomposing target-domain-styled images and corresponding source-domain annotations. Comparison experiments and ablation studies conducted on two public datasets demonstrate the superiority of our BiUDA framework to current state-of-the-art UDA methods and the effectiveness of its novel designs. By successfully addressing two-way adaptations, our BiUDA framework offers a flexible solution of UDA techniques to the real-world scenario.
Ensembled ResUnet for Anatomical Brain Barriers Segmentation
Jan 04, 2021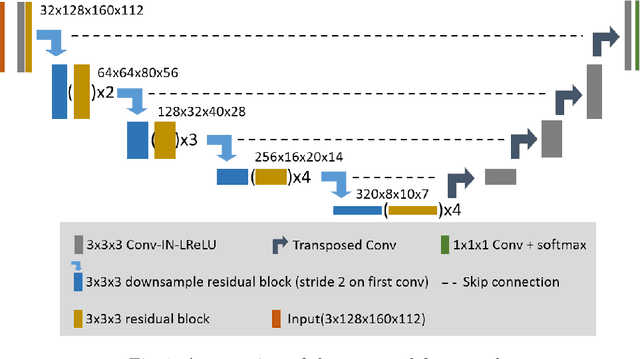
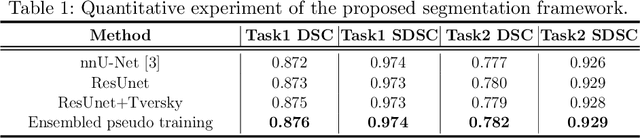
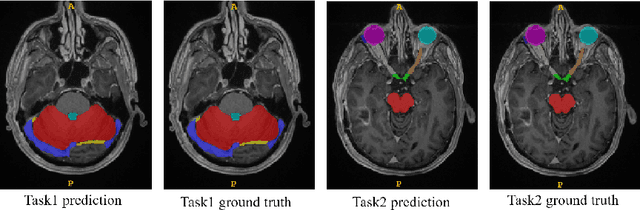
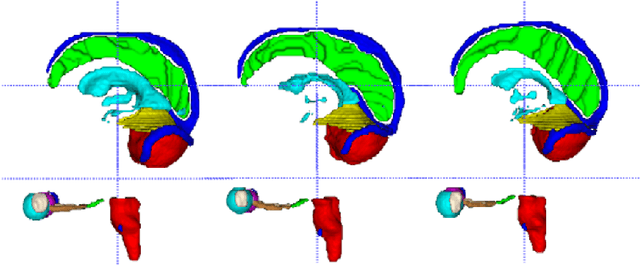
Accuracy segmentation of brain structures could be helpful for glioma and radiotherapy planning. However, due to the visual and anatomical differences between different modalities, the accurate segmentation of brain structures becomes challenging. To address this problem, we first construct a residual block based U-shape network with a deep encoder and shallow decoder, which can trade off the framework performance and efficiency. Then, we introduce the Tversky loss to address the issue of the class imbalance between different foreground and the background classes. Finally, a model ensemble strategy is utilized to remove outliers and further boost performance.
A Macro-Micro Weakly-supervised Framework for AS-OCT Tissue Segmentation
Jul 20, 2020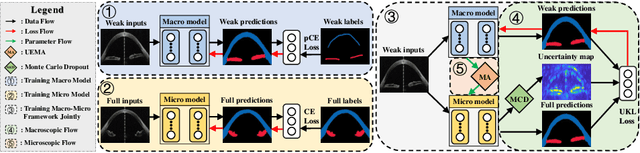
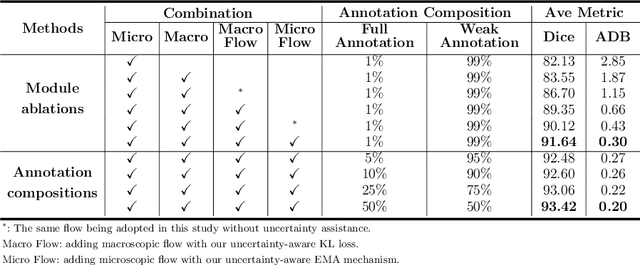
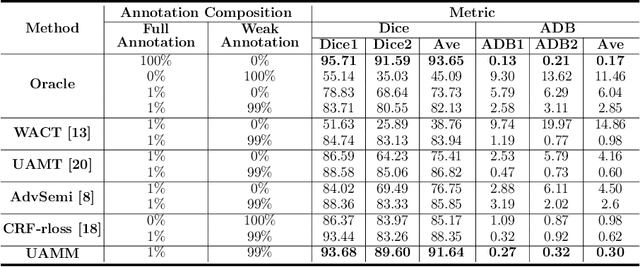
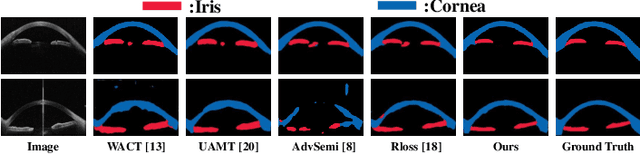
Primary angle closure glaucoma (PACG) is the leading cause of irreversible blindness among Asian people. Early detection of PACG is essential, so as to provide timely treatment and minimize the vision loss. In the clinical practice, PACG is diagnosed by analyzing the angle between the cornea and iris with anterior segment optical coherence tomography (AS-OCT). The rapid development of deep learning technologies provides the feasibility of building a computer-aided system for the fast and accurate segmentation of cornea and iris tissues. However, the application of deep learning methods in the medical imaging field is still restricted by the lack of enough fully-annotated samples. In this paper, we propose a novel framework to segment the target tissues accurately for the AS-OCT images, by using the combination of weakly-annotated images (majority) and fully-annotated images (minority). The proposed framework consists of two models which provide reliable guidance for each other. In addition, uncertainty guided strategies are adopted to increase the accuracy and stability of the guidance. Detailed experiments on the publicly available AGE dataset demonstrate that the proposed framework outperforms the state-of-the-art semi-/weakly-supervised methods and has a comparable performance as the fully-supervised method. Therefore, the proposed method is demonstrated to be effective in exploiting information contained in the weakly-annotated images and has the capability to substantively relieve the annotation workload.
AGE Challenge: Angle Closure Glaucoma Evaluation in Anterior Segment Optical Coherence Tomography
May 05, 2020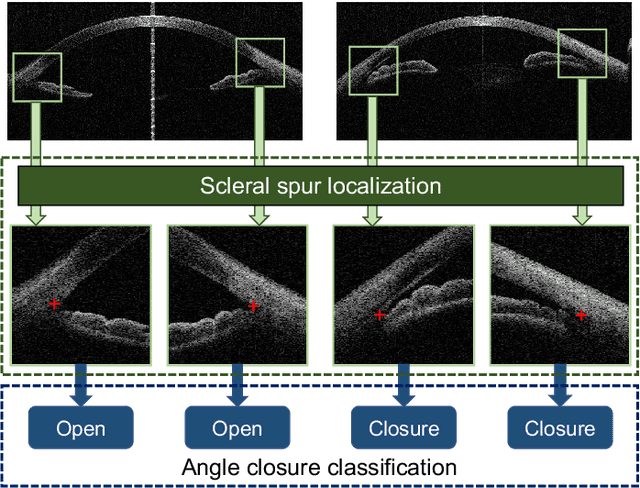
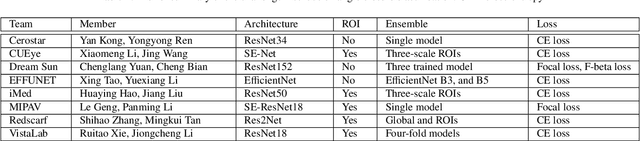
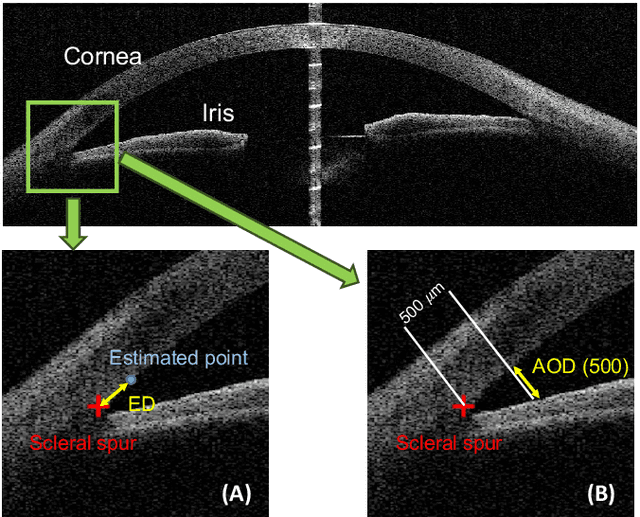
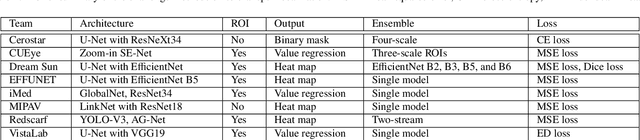
Angle closure glaucoma (ACG) is a more aggressive disease than open-angle glaucoma, where the abnormal anatomical structures of the anterior chamber angle (ACA) may cause an elevated intraocular pressure and gradually leads to glaucomatous optic neuropathy and eventually to visual impairment and blindness. Anterior Segment Optical Coherence Tomography (AS-OCT) imaging provides a fast and contactless way to discriminate angle closure from open angle. Although many medical image analysis algorithms have been developed for glaucoma diagnosis, only a few studies have focused on AS-OCT imaging. In particular, there is no public AS-OCT dataset available for evaluating the existing methods in a uniform way, which limits the progress in the development of automated techniques for angle closure detection and assessment. To address this, we organized the Angle closure Glaucoma Evaluation challenge (AGE), held in conjunction with MICCAI 2019. The AGE challenge consisted of two tasks: scleral spur localization and angle closure classification. For this challenge, we released a large data of 4800 annotated AS-OCT images from 199 patients, and also proposed an evaluation framework to benchmark and compare different models. During the AGE challenge, over 200 teams registered online, and more than 1100 results were submitted for online evaluation. Finally, eight teams participated in the onsite challenge. In this paper, we summarize these eight onsite challenge methods and analyze their corresponding results in the two tasks. We further discuss limitations and future directions. In the AGE challenge, the top-performing approach had an average Euclidean Distance of 10 pixel in scleral spur localization, while in the task of angle closure classification, all the algorithms achieved the satisfactory performances, especially, 100% accuracy rate for top-two performances.
Identification of primary angle-closure on AS-OCT images with Convolutional Neural Networks
Oct 23, 2019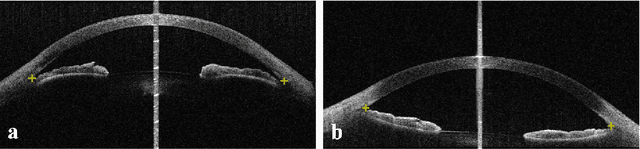
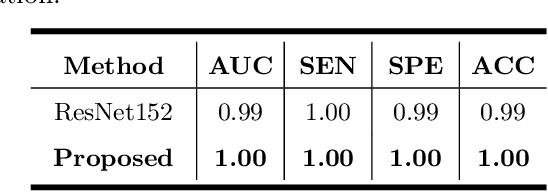
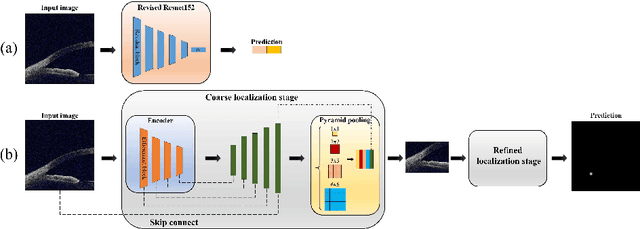
Primary angle-closure disease (PACD) is a severe retinal disease, which might cause irreversible vision loss. In clinic, accurate identification of angle-closure and localization of the scleral spur's position on anterior segment optical coherence tomography (AS-OCT) is essential for the diagnosis of PACD. However, manual delineation might confine in low accuracy and low efficiency. In this paper, we propose an efficient and accurate end-to-end architecture for angle-closure classification and scleral spur localization. Specifically, we utilize a revised ResNet152 as our backbone to improve the accuracy of the angle-closure identification. For scleral spur localization, we adopt EfficientNet as encoder because of its powerful feature extraction potential. By combining the skip-connect module and pyramid pooling module, the network is able to collect semantic cues in feature maps from multiple dimensions and scales. Afterward, we propose a novel keypoint registration loss to constrain the model's attention to the intensity and location of the scleral spur area. Several experiments are extensively conducted to evaluate our method on the angle-closure glaucoma evaluation (AGE) Challenge dataset. The results show that our proposed architecture ranks the first place of the classification task on the test dataset and achieves the average Euclidean distance error of 12.00 pixels in the scleral spur localization task.