 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of primary angle-closure on AS-OCT images with Convolutional Neural Networks
Oct 23, 2019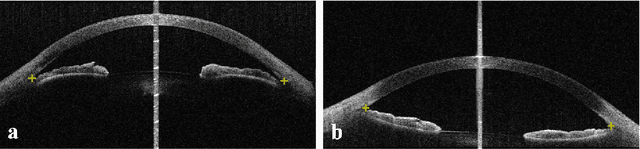
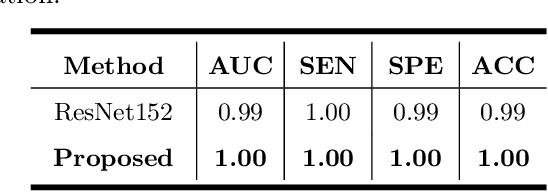
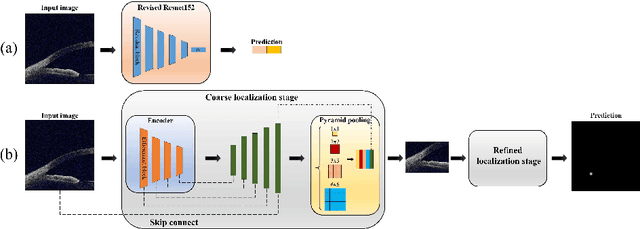
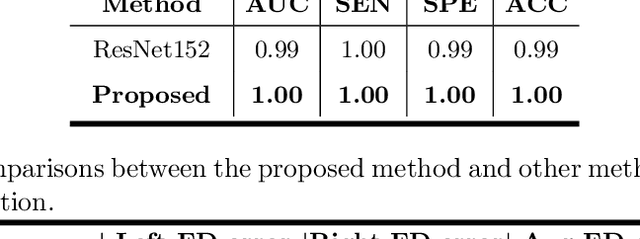
Primary angle-closure disease (PACD) is a severe retinal disease, which might cause irreversible vision loss. In clinic, accurate identification of angle-closure and localization of the scleral spur's position on anterior segment optical coherence tomography (AS-OCT) is essential for the diagnosis of PACD. However, manual delineation might confine in low accuracy and low efficiency. In this paper, we propose an efficient and accurate end-to-end architecture for angle-closure classification and scleral spur localization. Specifically, we utilize a revised ResNet152 as our backbone to improve the accuracy of the angle-closure identification. For scleral spur localization, we adopt EfficientNet as encoder because of its powerful feature extraction potential. By combining the skip-connect module and pyramid pooling module, the network is able to collect semantic cues in feature maps from multiple dimensions and scales. Afterward, we propose a novel keypoint registration loss to constrain the model's attention to the intensity and location of the scleral spur area. Several experiments are extensively conducted to evaluate our method on the angle-closure glaucoma evaluation (AGE) Challenge dataset. The results show that our proposed architecture ranks the first place of the classification task on the test dataset and achieves the average Euclidean distance error of 12.00 pixels in the scleral spur localization task.
Video to Fully Automatic 3D Hair Model
Sep 13, 2018
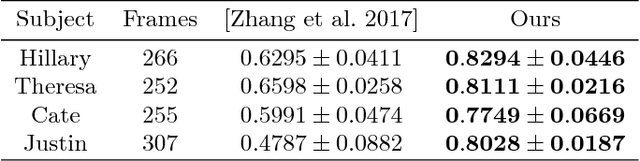

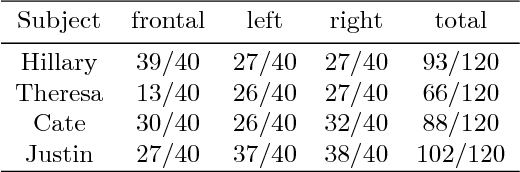
Imagine taking a selfie video with your mobile phone and getting as output a 3D model of your head (face and 3D hair strands) that can be later used in VR, AR, and any other domain. State of the art hair reconstruction methods allow either a single photo (thus compromising 3D quality) or multiple views, but they require manual user interaction (manual hair segmentation and capture of fixed camera views that span full 360 degree). In this paper, we describe a system that can completely automatically create a reconstruction from any video (even a selfie video), and we don't require specific views, since taking your -90 degree, 90 degree, and full back views is not feasible in a selfie capture. In the core of our system, in addition to the automatization components, hair strands are estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results. We provide qualitative, quantitative, and Mechanical Turk human studies that support the proposed system, and show results on a diverse variety of videos (8 different celebrity videos, 9 selfie mobile videos, spanning age, gender, hair length, type, and styling).
3D Face Hallucination from a Single Depth Frame
Sep 13, 2018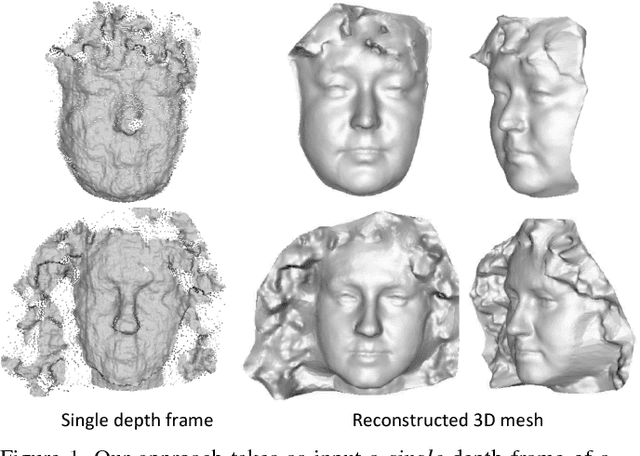

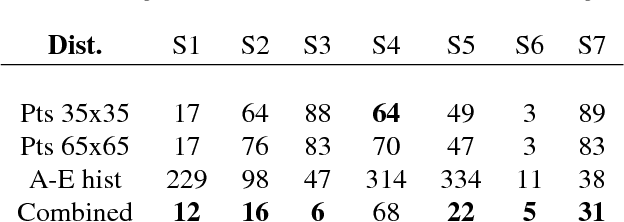
We present an algorithm that takes a single frame of a person's face from a depth camera, e.g., Kinect, and produces a high-resolution 3D mesh of the input face. We leverage a dataset of 3D face meshes of 1204 distinct individuals ranging from age 3 to 40, captured in a neutral expression. We divide the input depth frame into semantically significant regions (eyes, nose, mouth, cheeks) and search the database for the best matching shape per region. We further combine the input depth frame with the matched database shapes into a single mesh that results in a high-resolution shape of the input person. Our system is fully automatic and uses only depth data for matching, making it invariant to imaging conditions. We evaluate our results using ground truth shapes, as well as compare to state-of-the-art shape estimation methods. We demonstrate the robustness of our local matching approach with high-quality reconstruction of faces that fall outside of the dataset span, e.g., faces older than 40 years old, facial expressions, and different ethnicities.
Head Reconstruction from Internet Photos
Sep 13, 2018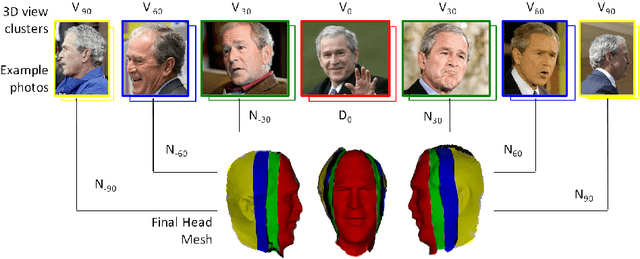
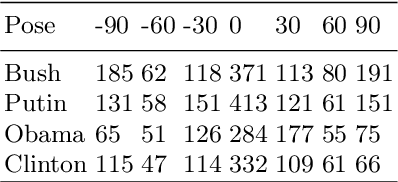


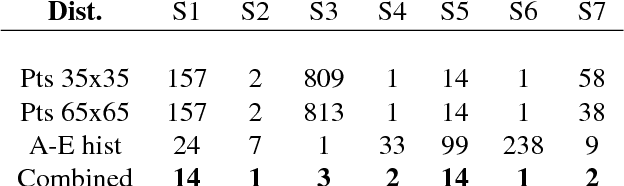
3D face reconstruction from Internet photos has recently produced exciting results. A person's face, e.g., Tom Hanks, can be modeled and animated in 3D from a completely uncalibrated photo collection. Most methods, however, focus solely on face area and mask out the rest of the head. This paper proposes that head modeling from the Internet is a problem we can solve. We target reconstruction of the rough shape of the head. Our method is to gradually "grow" the head mesh starting from the frontal face and extending to the rest of views using photometric stereo constraints. We call our method boundary-value growing algorithm. Results on photos of celebrities downloaded from the Internet are presented.