 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Hallucination from a Single Depth Frame
Paper and Code
Sep 13, 2018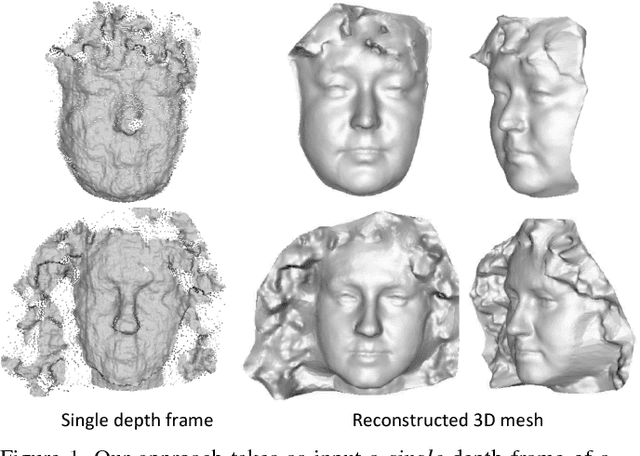
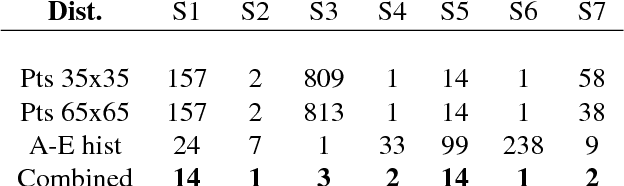

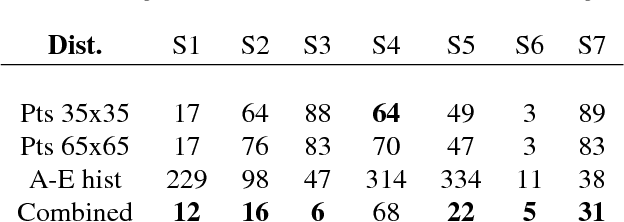
We present an algorithm that takes a single frame of a person's face from a depth camera, e.g., Kinect, and produces a high-resolution 3D mesh of the input face. We leverage a dataset of 3D face meshes of 1204 distinct individuals ranging from age 3 to 40, captured in a neutral expression. We divide the input depth frame into semantically significant regions (eyes, nose, mouth, cheeks) and search the database for the best matching shape per region. We further combine the input depth frame with the matched database shapes into a single mesh that results in a high-resolution shape of the input person. Our system is fully automatic and uses only depth data for matching, making it invariant to imaging conditions. We evaluate our results using ground truth shapes, as well as compare to state-of-the-art shape estimation methods. We demonstrate the robustness of our local matching approach with high-quality reconstruction of faces that fall outside of the dataset span, e.g., faces older than 40 years old, facial expressions, and different ethnicities.