 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Progression Masked Autoencoder with Fusion CNN Network for Classifying Evolution Between Two Pairs of 2D OCT Slices
Aug 27, 2025Age-related Macular Degeneration (AMD) is a prevalent eye condition affecting visual acuity. Anti-vascular endothelial growth factor (anti-VEGF) treatments have been effective in slowing the progression of neovascular AMD, with better outcomes achieved through timely diagnosis and consistent monitoring. Tracking the progression of neovascular activity in OCT scans of patients with exudative AMD allows for the development of more personalized and effective treatment plans. This was the focus of the Monitoring Age-related Macular Degeneration Progression in Optical Coherence Tomography (MARIO) challenge, in which we participated. In Task 1, which involved classifying the evolution between two pairs of 2D slices from consecutive OCT acquisitions, we employed a fusion CNN network with model ensembling to further enhance the model's performance. For Task 2, which focused on predicting progression over the next three months based on current exam data, we proposed the Patch Progression Masked Autoencoder that generates an OCT for the next exam and then classifies the evolution between the current OCT and the one generated using our solution from Task 1. The results we achieved allowed us to place in the Top 10 for both tasks. Some team members are part of the same organization as the challenge organizers; therefore, we are not eligible to compete for the prize.
* 10 pages, 5 figures, 3 tables, challenge/conference paper
Context-Aware Vision Language Foundation Models for Ocular Disease Screening in Retinal Images
Mar 19, 2025Foundation models are large-scale versatile systems trained on vast quantities of diverse data to learn generalizable representations. Their adaptability with minimal fine-tuning makes them particularly promising for medical imaging, where data variability and domain shifts are major challenges. Currently, two types of foundation models dominate the literature: self-supervised models and more recent vision-language models. In this study, we advance the application of vision-language foundation (VLF) models for ocular disease screening using the OPHDIAT dataset, which includes nearly 700,000 fundus photographs from a French diabetic retinopathy (DR) screening network. This dataset provides extensive clinical data (patient-specific information such as diabetic health conditions, and treatments), labeled diagnostics, ophthalmologists text-based findings, and multiple retinal images for each examination. Building on the FLAIR model $\unicode{x2013}$ a VLF model for retinal pathology classification $\unicode{x2013}$ we propose novel context-aware VLF models (e.g jointly analyzing multiple images from the same visit or taking advantage of past diagnoses and contextual data) to fully leverage the richness of the OPHDIAT dataset and enhance robustness to domain shifts. Our approaches were evaluated on both in-domain (a testing subset of OPHDIAT) and out-of-domain data (public datasets) to assess their generalization performance. Our model demonstrated improved in-domain performance for DR grading, achieving an area under the curve (AUC) ranging from 0.851 to 0.9999, and generalized well to ocular disease detection on out-of-domain data (AUC: 0.631-0.913).
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022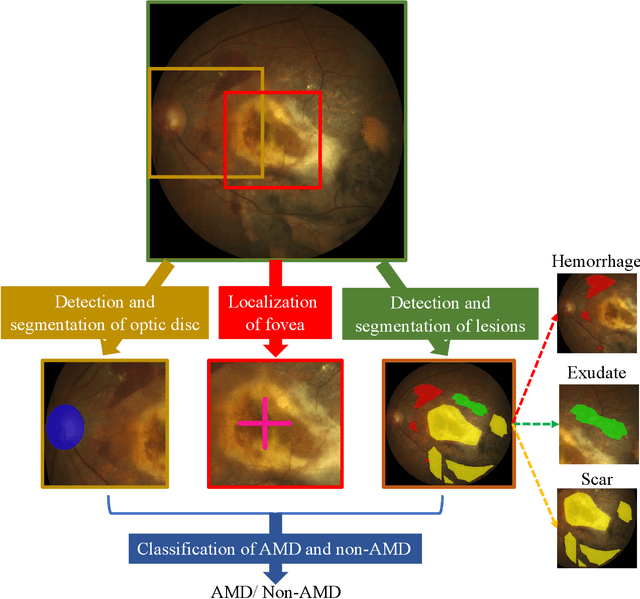

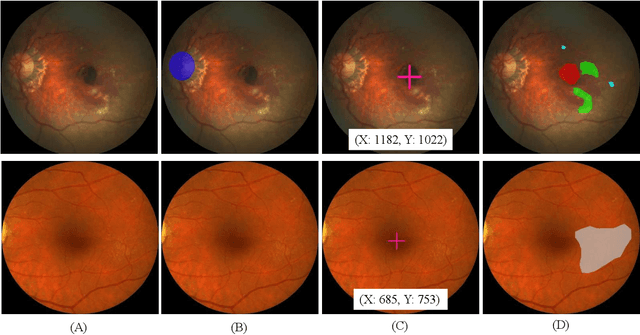
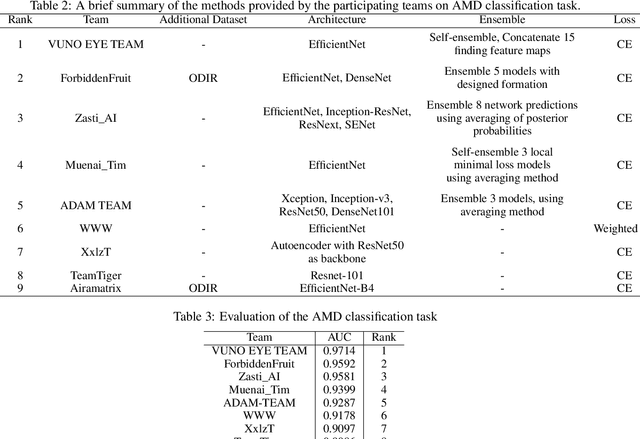
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.