 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021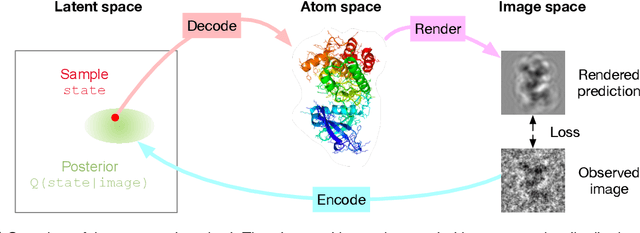
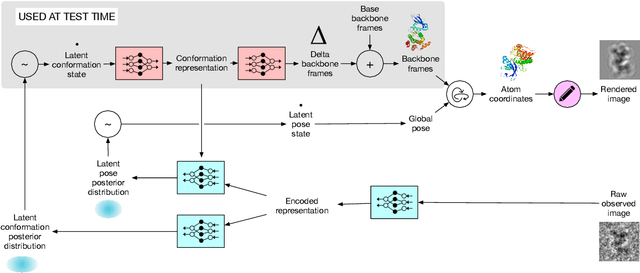
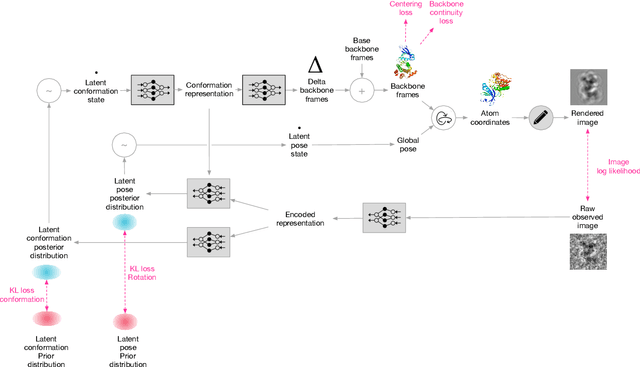
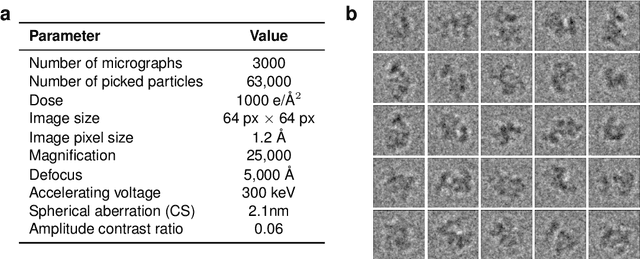
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.
The Medical Segmentation Decathlon
Jun 10, 2021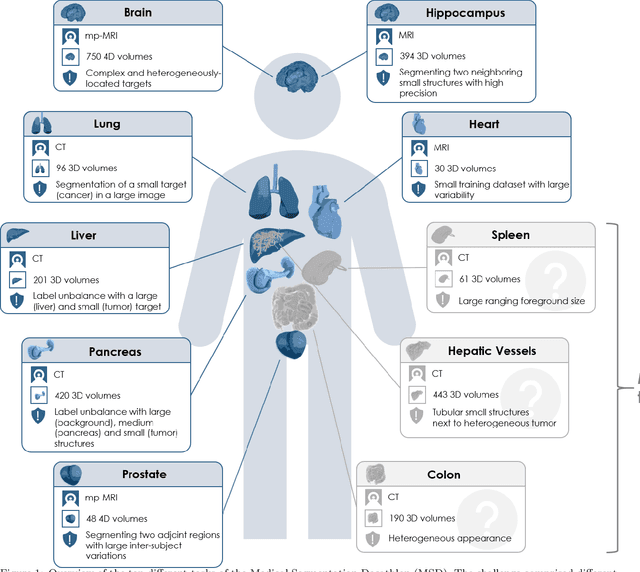
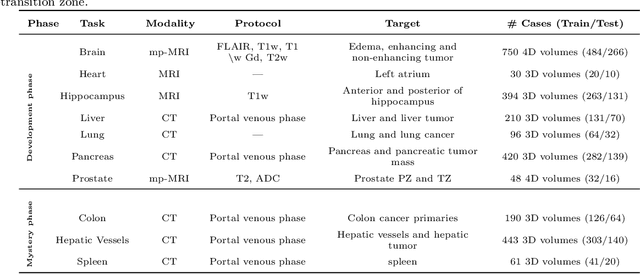
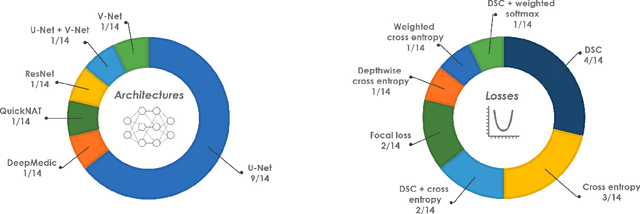
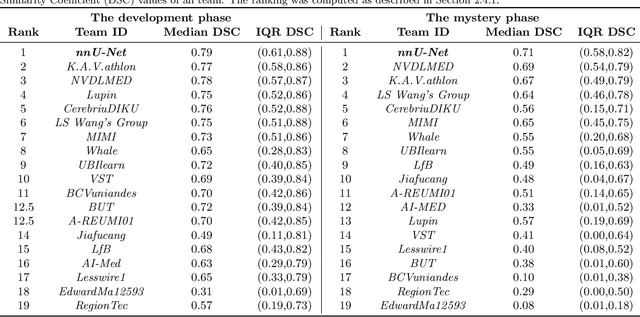
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Contrastive Training for Improved Out-of-Distribution Detection
Jul 10, 2020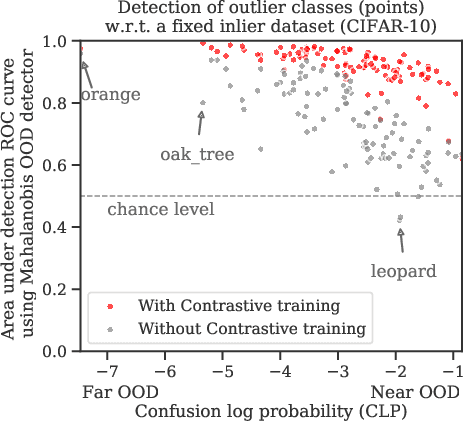
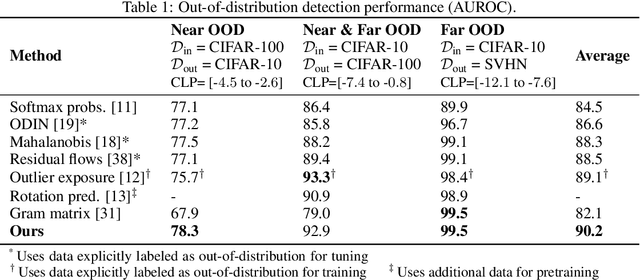
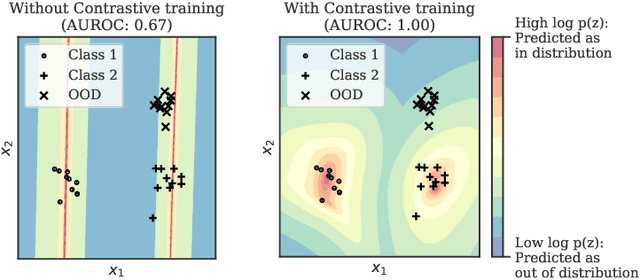
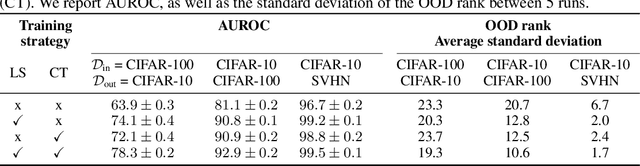
Reliable detection of out-of-distribution (OOD) inputs is increasingly understood to be a precondition for deployment of machine learning systems. This paper proposes and investigates the use of contrastive training to boost OOD detection performance. Unlike leading methods for OOD detection, our approach does not require access to examples labeled explicitly as OOD, which can be difficult to collect in practice. We show in extensive experiments that contrastive training significantly helps OOD detection performance on a number of common benchmarks. By introducing and employing the Confusion Log Probability (CLP) score, which quantifies the difficulty of the OOD detection task by capturing the similarity of inlier and outlier datasets, we show that our method especially improves performance in the `near OOD' classes -- a particularly challenging setting for previous methods.
A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities
May 30, 2019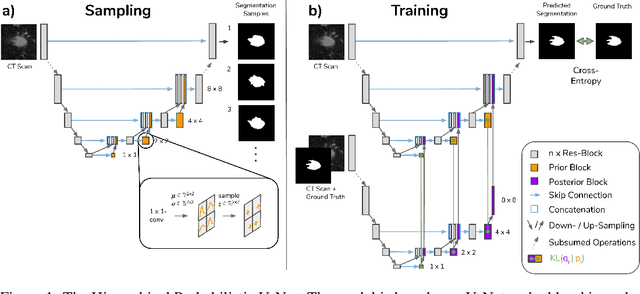
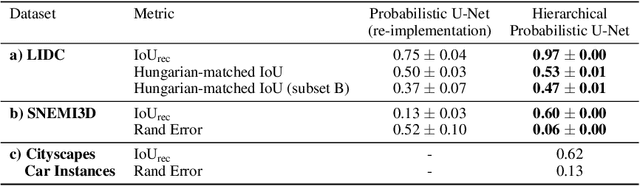
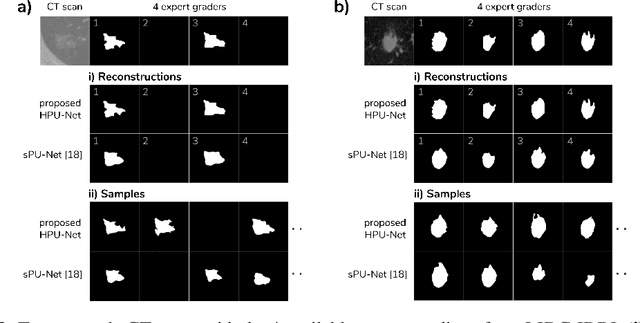

Medical imaging only indirectly measures the molecular identity of the tissue within each voxel, which often produces only ambiguous image evidence for target measures of interest, like semantic segmentation. This diversity and the variations of plausible interpretations are often specific to given image regions and may thus manifest on various scales, spanning all the way from the pixel to the image level. In order to learn a flexible distribution that can account for multiple scales of variations, we propose the Hierarchical Probabilistic U-Net, a segmentation network with a conditional variational auto-encoder (cVAE) that uses a hierarchical latent space decomposition. We show that this model formulation enables sampling and reconstruction of segmenations with high fidelity, i.e. with finely resolved detail, while providing the flexibility to learn complex structured distributions across scales. We demonstrate these abilities on the task of segmenting ambiguous medical scans as well as on instance segmentation of neurobiological and natural images. Our model automatically separates independent factors across scales, an inductive bias that we deem beneficial in structured output prediction tasks beyond segmentation.
A large annotated medical image dataset for the development and evaluation of segmentation algorithms
Feb 25, 2019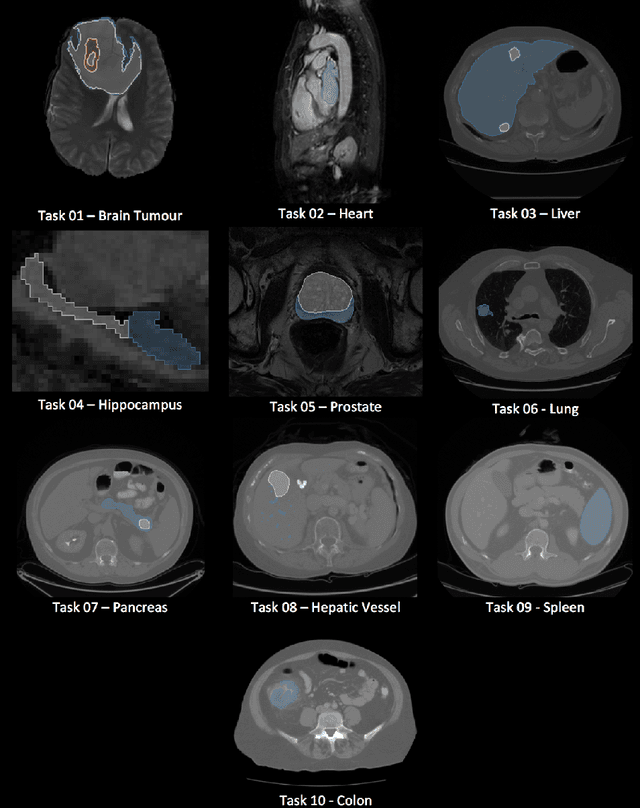

Semantic segmentation of medical images aims to associate a pixel with a label in a medical image without human initialization. The success of semantic segmentation algorithms is contingent on the availability of high-quality imaging data with corresponding labels provided by experts. We sought to create a large collection of annotated medical image datasets of various clinically relevant anatomies available under open source license to facilitate the development of semantic segmentation algorithms. Such a resource would allow: 1) objective assessment of general-purpose segmentation methods through comprehensive benchmarking and 2) open and free access to medical image data for any researcher interested in the problem domain. Through a multi-institutional effort, we generated a large, curated dataset representative of several highly variable segmentation tasks that was used in a crowd-sourced challenge - the Medical Segmentation Decathlon held during the 2018 Medical Image Computing and Computer Aided Interventions Conference in Granada, Spain. Here, we describe these ten labeled image datasets so that these data may be effectively reused by the research community.
A Probabilistic U-Net for Segmentation of Ambiguous Images
Oct 29, 2018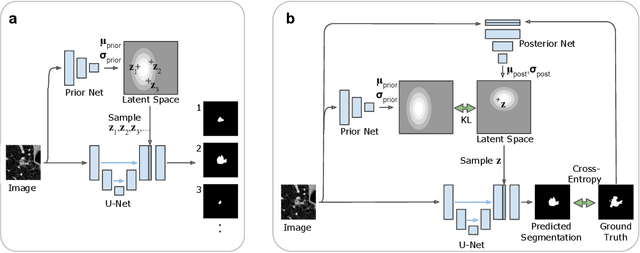

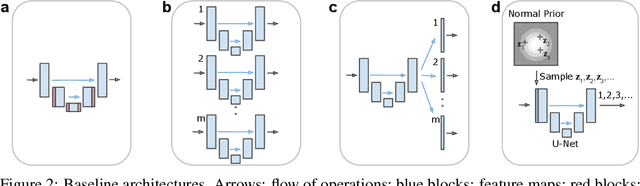

Many real-world vision problems suffer from inherent ambiguities. In clinical applications for example, it might not be clear from a CT scan alone which particular region is cancer tissue. Therefore a group of graders typically produces a set of diverse but plausible segmentations. We consider the task of learning a distribution over segmentations given an input. To this end we propose a generative segmentation model based on a combination of a U-Net with a conditional variational autoencoder that is capable of efficiently producing an unlimited number of plausible hypotheses. We show on a lung abnormalities segmentation task and on a Cityscapes segmentation task that our model reproduces the possible segmentation variants as well as the frequencies with which they occur, doing so significantly better than published approaches. These models could have a high impact in real-world applications, such as being used as clinical decision-making algorithms accounting for multiple plausible semantic segmentation hypotheses to provide possible diagnoses and recommend further actions to resolve the present ambiguities.
Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018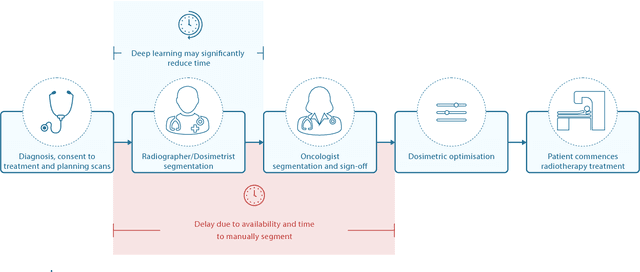
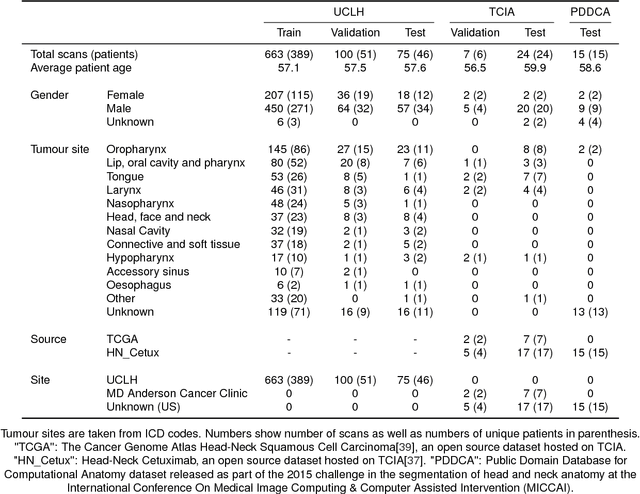
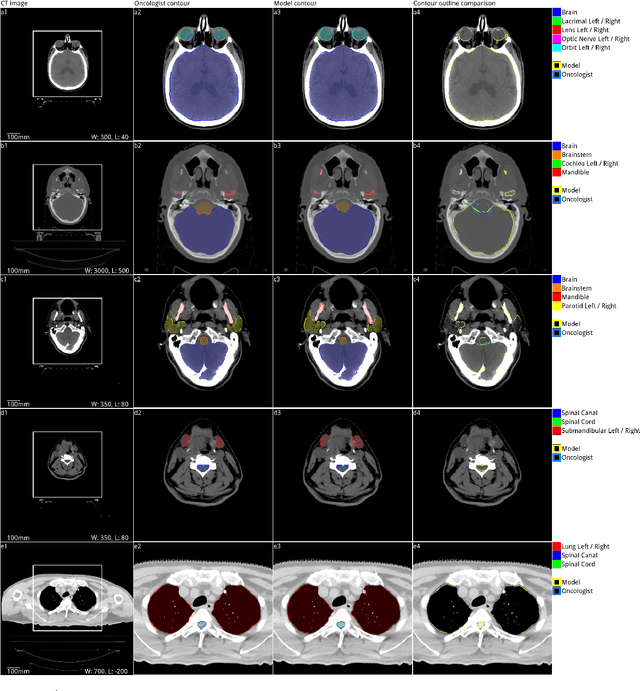
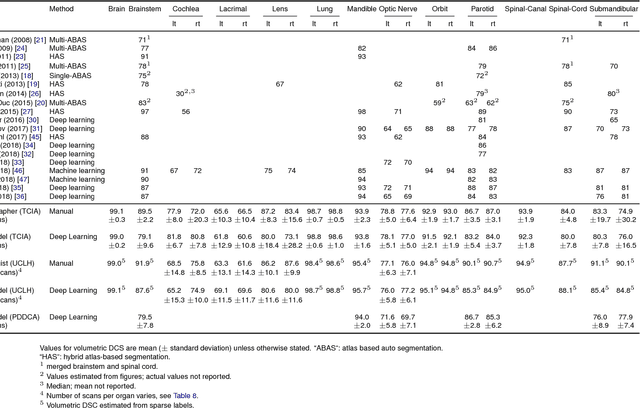
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.
Gland Segmentation in Colon Histology Images: The GlaS Challenge Contest
Sep 01, 2016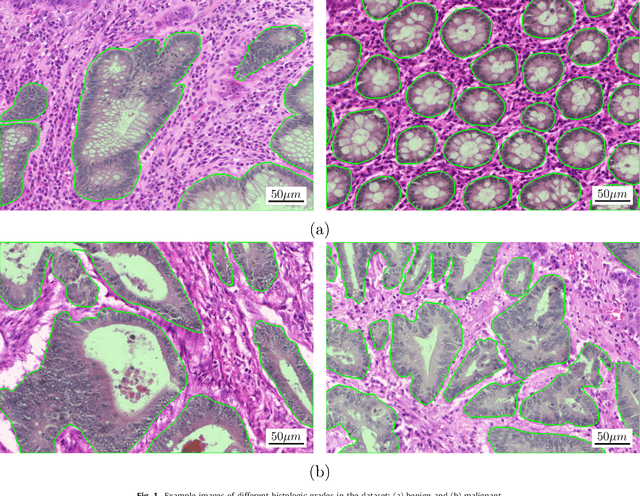
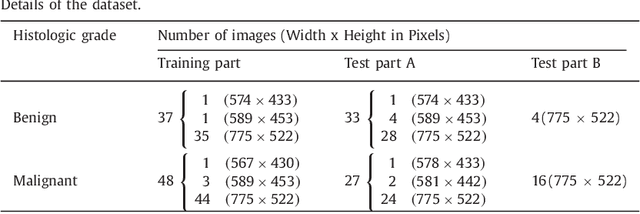
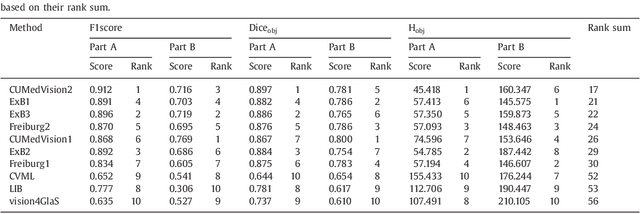
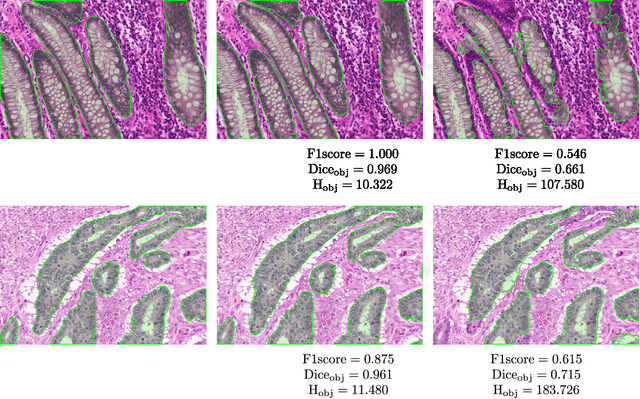
Colorectal adenocarcinoma originating in intestinal glandular structures is the most common form of colon cancer. In clinical practice, the morphology of intestinal glands, including architectural appearance and glandular formation, is used by pathologists to inform prognosis and plan the treatment of individual patients. However, achieving good inter-observer as well as intra-observer reproducibility of cancer grading is still a major challenge in modern pathology. An automated approach which quantifies the morphology of glands is a solution to the problem. This paper provides an overview to the Gland Segmentation in Colon Histology Images Challenge Contest (GlaS) held at MICCAI'2015. Details of the challenge, including organization, dataset and evaluation criteria, are presented, along with the method descriptions and evaluation results from the top performing methods.
3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
Jun 21, 2016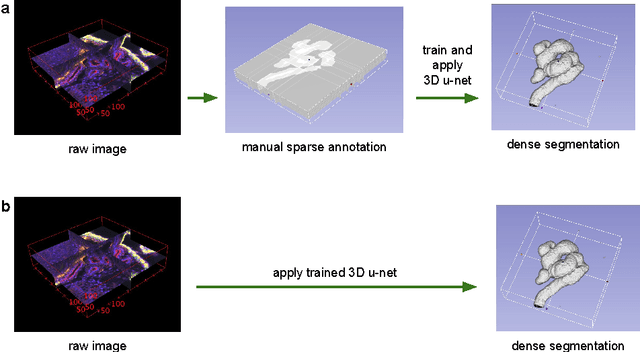
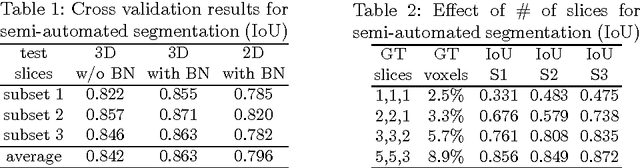
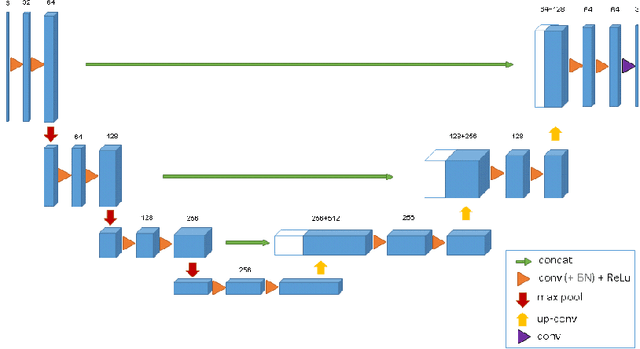
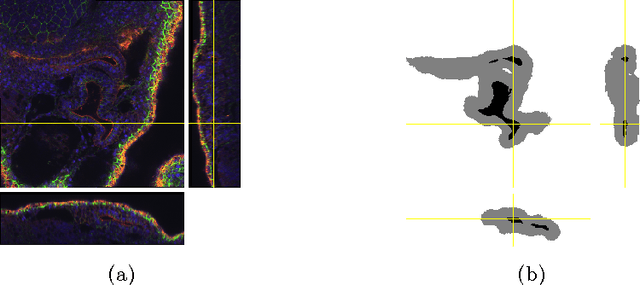
This paper introduces a network for volumetric segmentation that learns from sparsely annotated volumetric images. We outline two attractive use cases of this method: (1) In a semi-automated setup, the user annotates some slices in the volume to be segmented. The network learns from these sparse annotations and provides a dense 3D segmentation. (2) In a fully-automated setup, we assume that a representative, sparsely annotated training set exists. Trained on this data set, the network densely segments new volumetric images. The proposed network extends the previous u-net architecture from Ronneberger et al. by replacing all 2D operations with their 3D counterparts. The implementation performs on-the-fly elastic deformations for efficient data augmentation during training. It is trained end-to-end from scratch, i.e., no pre-trained network is required. We test the performance of the proposed method on a complex, highly variable 3D structure, the Xenopus kidney, and achieve good results for both use cases.
U-Net: Convolutional Networks for Biomedical Image Segmentation
May 18, 2015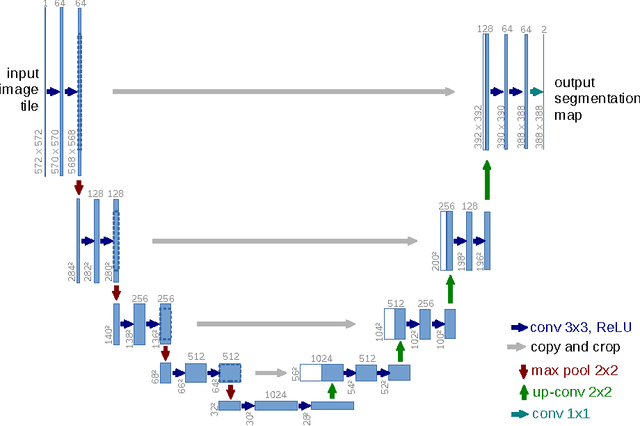
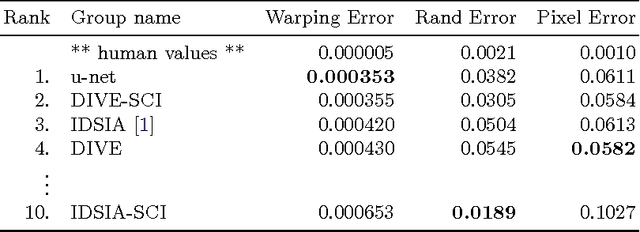
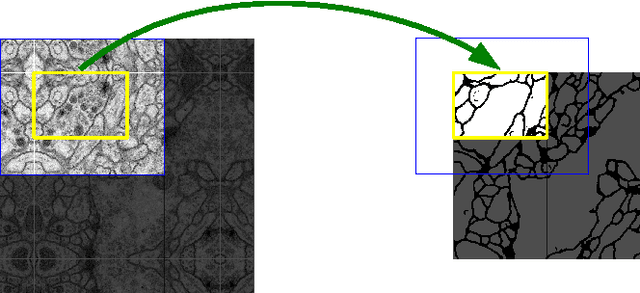

There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net .