 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023



Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
Contrastive Training for Improved Out-of-Distribution Detection
Jul 10, 2020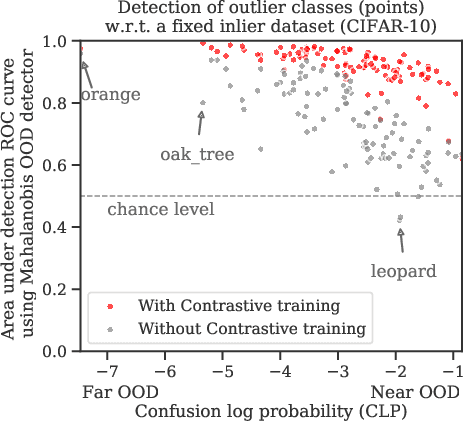
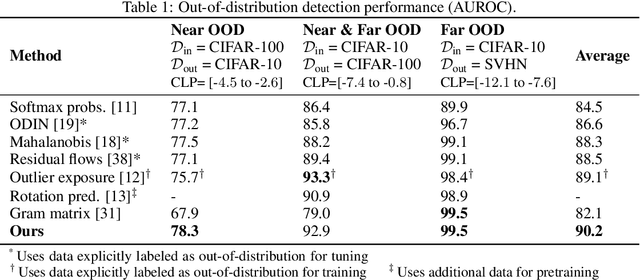
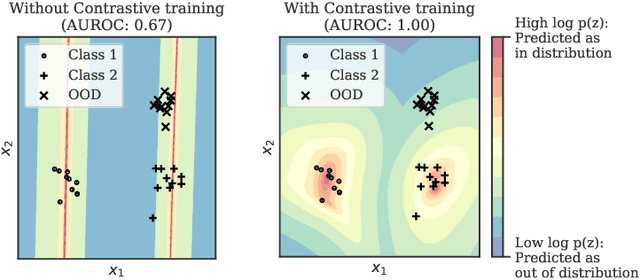
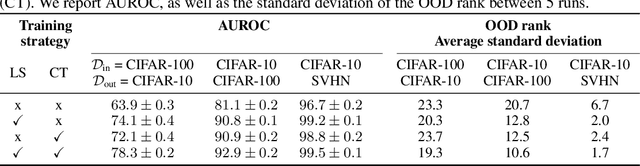
Reliable detection of out-of-distribution (OOD) inputs is increasingly understood to be a precondition for deployment of machine learning systems. This paper proposes and investigates the use of contrastive training to boost OOD detection performance. Unlike leading methods for OOD detection, our approach does not require access to examples labeled explicitly as OOD, which can be difficult to collect in practice. We show in extensive experiments that contrastive training significantly helps OOD detection performance on a number of common benchmarks. By introducing and employing the Confusion Log Probability (CLP) score, which quantifies the difficulty of the OOD detection task by capturing the similarity of inlier and outlier datasets, we show that our method especially improves performance in the `near OOD' classes -- a particularly challenging setting for previous methods.
Unsupervised Anomaly Localization using Variational Auto-Encoders
Jul 11, 2019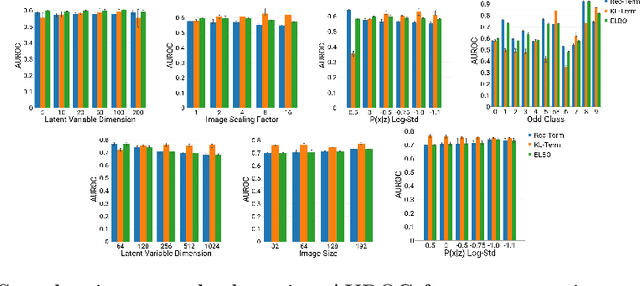

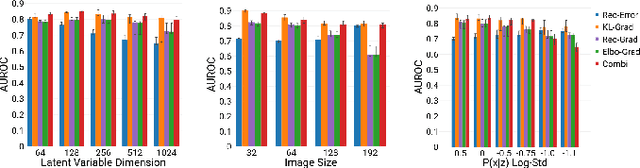

An assumption-free automatic check of medical images for potentially overseen anomalies would be a valuable assistance for a radiologist. Deep learning and especially Variational Auto-Encoders (VAEs) have shown great potential in the unsupervised learning of data distributions. In principle, this allows for such a check and even the localization of parts in the image that are most suspicious. Currently, however, the reconstruction-based localization by design requires adjusting the model architecture to the specific problem looked at during evaluation. This contradicts the principle of building assumption-free models. We propose complementing the localization part with a term derived from the Kullback-Leibler (KL)-divergence. For validation, we perform a series of experiments on FashionMNIST as well as on a medical task including >1000 healthy and >250 brain tumor patients. Results show that the proposed formalism outperforms the state of the art VAE-based localization of anomalies across many hyperparameter settings and also shows a competitive max performance.
nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation
Sep 27, 2018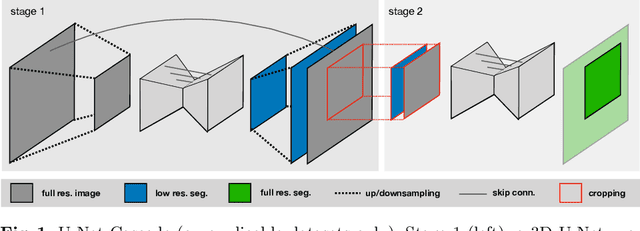
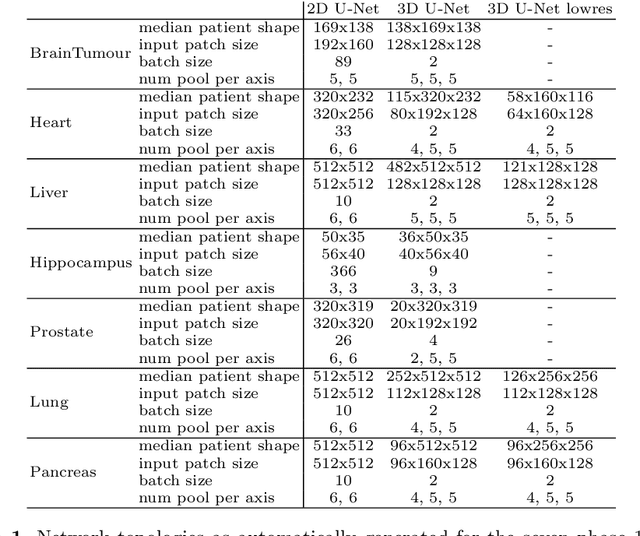
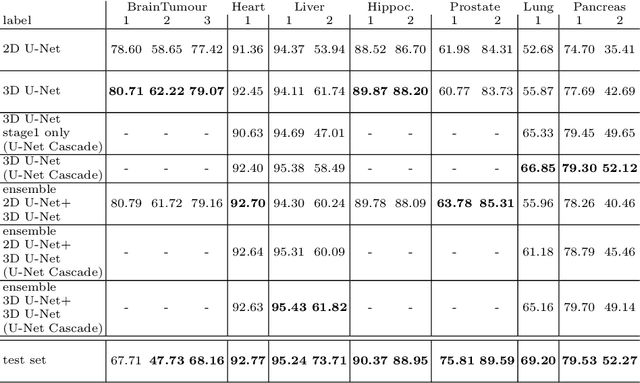
The U-Net was presented in 2015. With its straight-forward and successful architecture it quickly evolved to a commonly used benchmark in medical image segmentation. The adaptation of the U-Net to novel problems, however, comprises several degrees of freedom regarding the exact architecture, preprocessing, training and inference. These choices are not independent of each other and substantially impact the overall performance. The present paper introduces the nnU-Net ('no-new-Net'), which refers to a robust and self-adapting framework on the basis of 2D and 3D vanilla U-Nets. We argue the strong case for taking away superfluous bells and whistles of many proposed network designs and instead focus on the remaining aspects that make out the performance and generalizability of a method. We evaluate the nnU-Net in the context of the Medical Segmentation Decathlon challenge, which measures segmentation performance in ten disciplines comprising distinct entities, image modalities, image geometries and dataset sizes, with no manual adjustments between datasets allowed. At the time of manuscript submission, nnU-Net achieves the highest mean dice scores across all classes and seven phase 1 tasks (except class 1 in BrainTumour) in the online leaderboard of the challenge.
Adversarial Networks for Prostate Cancer Detection
Nov 28, 2017
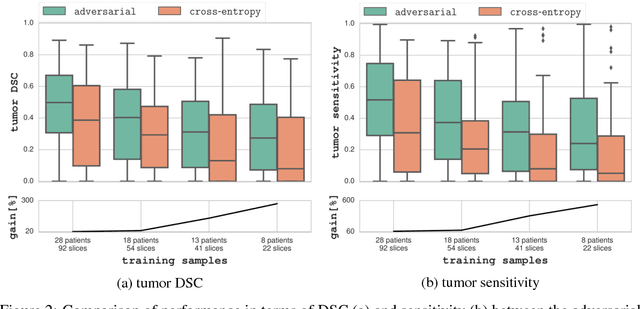
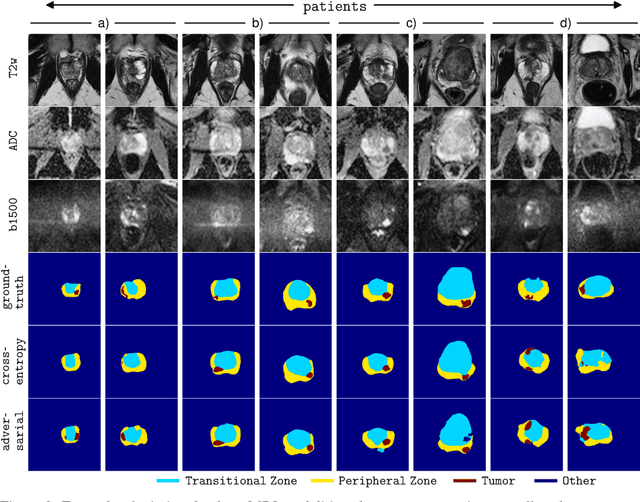
The large number of trainable parameters of deep neural networks renders them inherently data hungry. This characteristic heavily challenges the medical imaging community and to make things even worse, many imaging modalities are ambiguous in nature leading to rater-dependant annotations that current loss formulations fail to capture. We propose employing adversarial training for segmentation networks in order to alleviate aforementioned problems. We learn to segment aggressive prostate cancer utilizing challenging MRI images of 152 patients and show that the proposed scheme is superior over the de facto standard in terms of the detection sensitivity and the dice-score for aggressive prostate cancer. The achieved relative gains are shown to be particularly pronounced in the small dataset limit.
Adversarial Networks for the Detection of Aggressive Prostate Cancer
Feb 26, 2017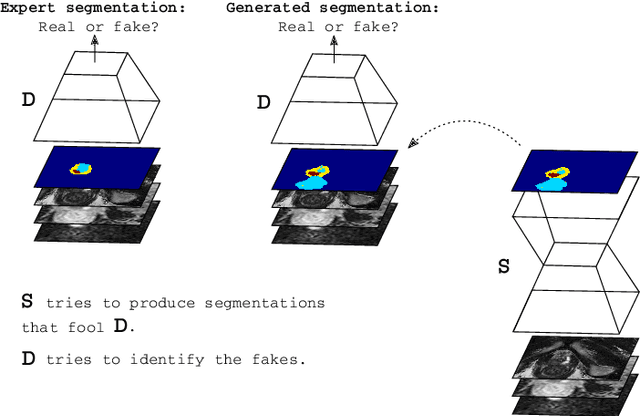

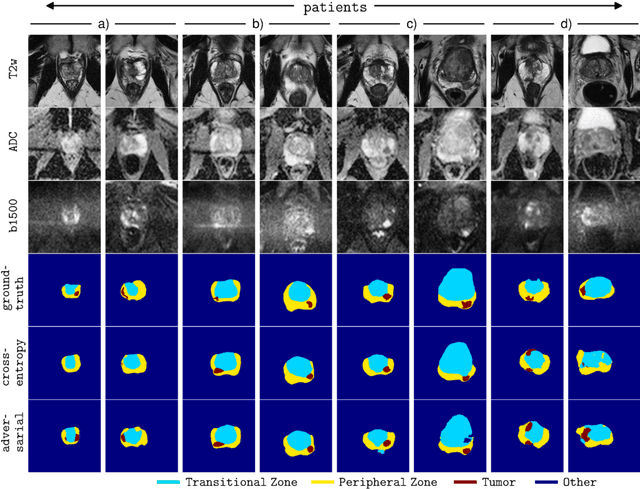
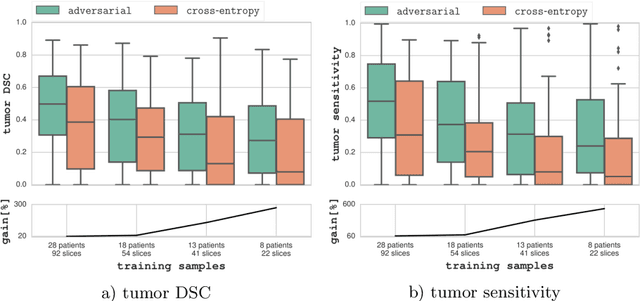
Semantic segmentation constitutes an integral part of medical image analyses for which breakthroughs in the field of deep learning were of high relevance. The large number of trainable parameters of deep neural networks however renders them inherently data hungry, a characteristic that heavily challenges the medical imaging community. Though interestingly, with the de facto standard training of fully convolutional networks (FCNs) for semantic segmentation being agnostic towards the `structure' of the predicted label maps, valuable complementary information about the global quality of the segmentation lies idle. In order to tap into this potential, we propose utilizing an adversarial network which discriminates between expert and generated annotations in order to train FCNs for semantic segmentation. Because the adversary constitutes a learned parametrization of what makes a good segmentation at a global level, we hypothesize that the method holds particular advantages for segmentation tasks on complex structured, small datasets. This holds true in our experiments: We learn to segment aggressive prostate cancer utilizing MRI images of 152 patients and show that the proposed scheme is superior over the de facto standard in terms of the detection sensitivity and the dice-score for aggressive prostate cancer. The achieved relative gains are shown to be particularly pronounced in the small dataset limit.