 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalse Promises in Medical Imaging AI? Assessing Validity of Outperformance Claims
May 07, 2025Performance comparisons are fundamental in medical imaging Artificial Intelligence (AI) research, often driving claims of superiority based on relative improvements in common performance metrics. However, such claims frequently rely solely on empirical mean performance. In this paper, we investigate whether newly proposed methods genuinely outperform the state of the art by analyzing a representative cohort of medical imaging papers. We quantify the probability of false claims based on a Bayesian approach that leverages reported results alongside empirically estimated model congruence to estimate whether the relative ranking of methods is likely to have occurred by chance. According to our results, the majority (>80%) of papers claims outperformance when introducing a new method. Our analysis further revealed a high probability (>5%) of false outperformance claims in 86% of classification papers and 53% of segmentation papers. These findings highlight a critical flaw in current benchmarking practices: claims of outperformance in medical imaging AI are frequently unsubstantiated, posing a risk of misdirecting future research efforts.
Confidence intervals uncovered: Are we ready for real-world medical imaging AI?
Sep 27, 2024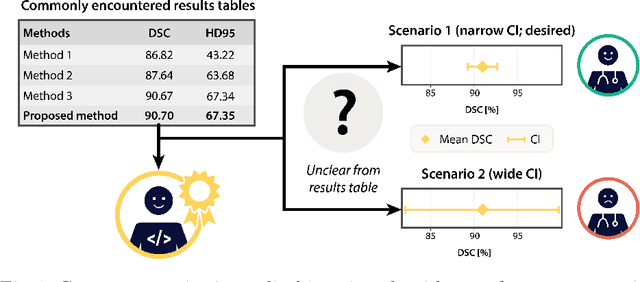
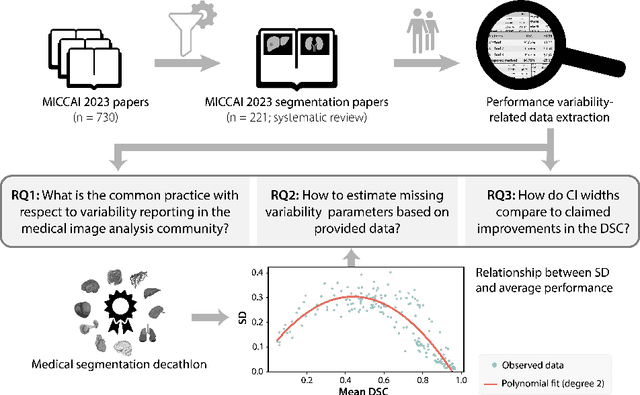
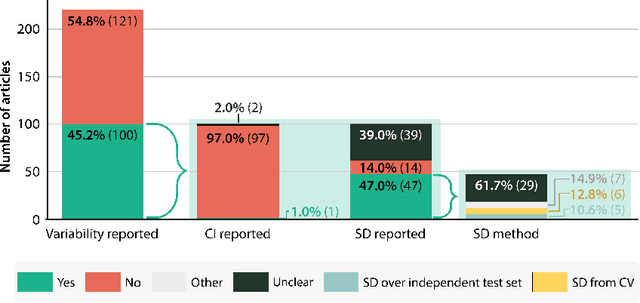

Medical imaging is spearheading the AI transformation of healthcare. Performance reporting is key to determine which methods should be translated into clinical practice. Frequently, broad conclusions are simply derived from mean performance values. In this paper, we argue that this common practice is often a misleading simplification as it ignores performance variability. Our contribution is threefold. (1) Analyzing all MICCAI segmentation papers (n = 221) published in 2023, we first observe that more than 50% of papers do not assess performance variability at all. Moreover, only one (0.5%) paper reported confidence intervals (CIs) for model performance. (2) To address the reporting bottleneck, we show that the unreported standard deviation (SD) in segmentation papers can be approximated by a second-order polynomial function of the mean Dice similarity coefficient (DSC). Based on external validation data from 56 previous MICCAI challenges, we demonstrate that this approximation can accurately reconstruct the CI of a method using information provided in publications. (3) Finally, we reconstructed 95% CIs around the mean DSC of MICCAI 2023 segmentation papers. The median CI width was 0.03 which is three times larger than the median performance gap between the first and second ranked method. For more than 60% of papers, the mean performance of the second-ranked method was within the CI of the first-ranked method. We conclude that current publications typically do not provide sufficient evidence to support which models could potentially be translated into clinical practice.
Quality Assured: Rethinking Annotation Strategies in Imaging AI
Jul 26, 2024



This paper does not describe a novel method. Instead, it studies an essential foundation for reliable benchmarking and ultimately real-world application of AI-based image analysis: generating high-quality reference annotations. Previous research has focused on crowdsourcing as a means of outsourcing annotations. However, little attention has so far been given to annotation companies, specifically regarding their internal quality assurance (QA) processes. Therefore, our aim is to evaluate the influence of QA employed by annotation companies on annotation quality and devise methodologies for maximizing data annotation efficacy. Based on a total of 57,648 instance segmented images obtained from a total of 924 annotators and 34 QA workers from four annotation companies and Amazon Mechanical Turk (MTurk), we derived the following insights: (1) Annotation companies perform better both in terms of quantity and quality compared to the widely used platform MTurk. (2) Annotation companies' internal QA only provides marginal improvements, if any. However, improving labeling instructions instead of investing in QA can substantially boost annotation performance. (3) The benefit of internal QA depends on specific image characteristics. Our work could enable researchers to derive substantially more value from a fixed annotation budget and change the way annotation companies conduct internal QA.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Labeling instructions matter in biomedical image analysis
Jul 20, 2022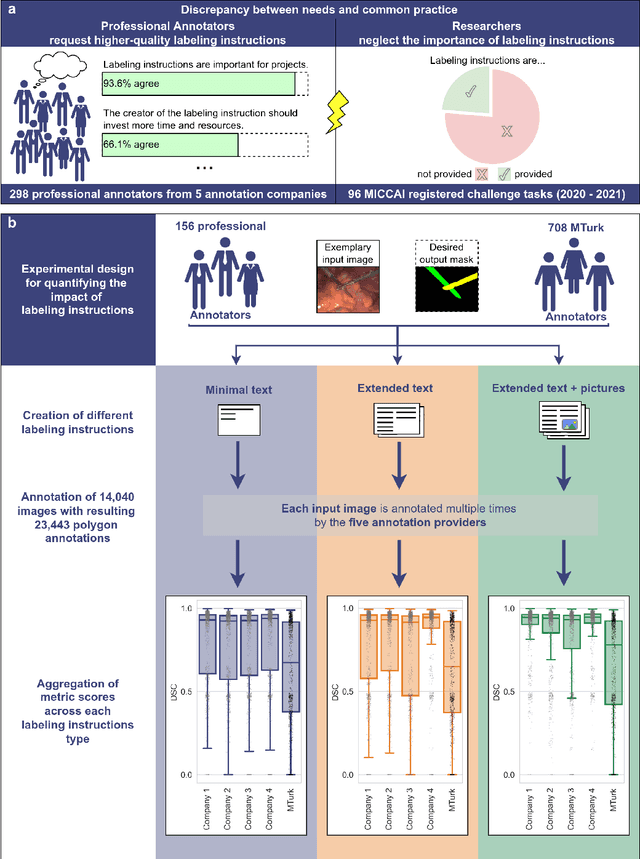
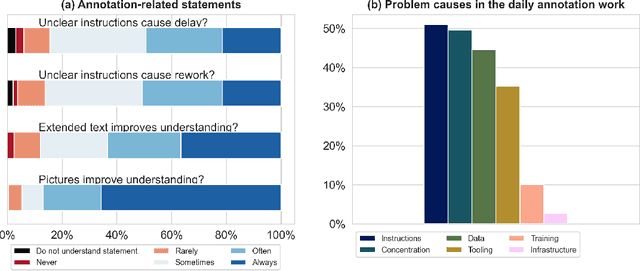
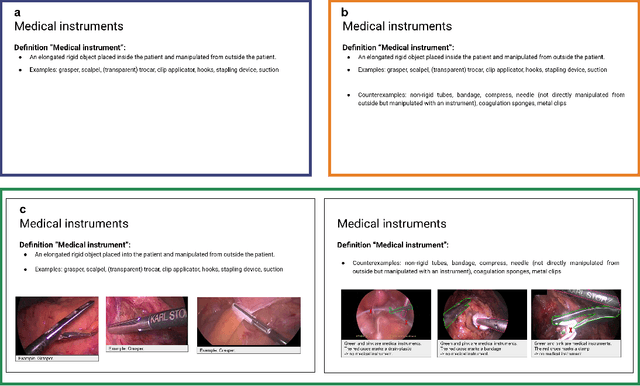
Biomedical image analysis algorithm validation depends on high-quality annotation of reference datasets, for which labeling instructions are key. Despite their importance, their optimization remains largely unexplored. Here, we present the first systematic study of labeling instructions and their impact on annotation quality in the field. Through comprehensive examination of professional practice and international competitions registered at the MICCAI Society, we uncovered a discrepancy between annotators' needs for labeling instructions and their current quality and availability. Based on an analysis of 14,040 images annotated by 156 annotators from four professional companies and 708 Amazon Mechanical Turk (MTurk) crowdworkers using instructions with different information density levels, we further found that including exemplary images significantly boosts annotation performance compared to text-only descriptions, while solely extending text descriptions does not. Finally, professional annotators constantly outperform MTurk crowdworkers. Our study raises awareness for the need of quality standards in biomedical image analysis labeling instructions.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022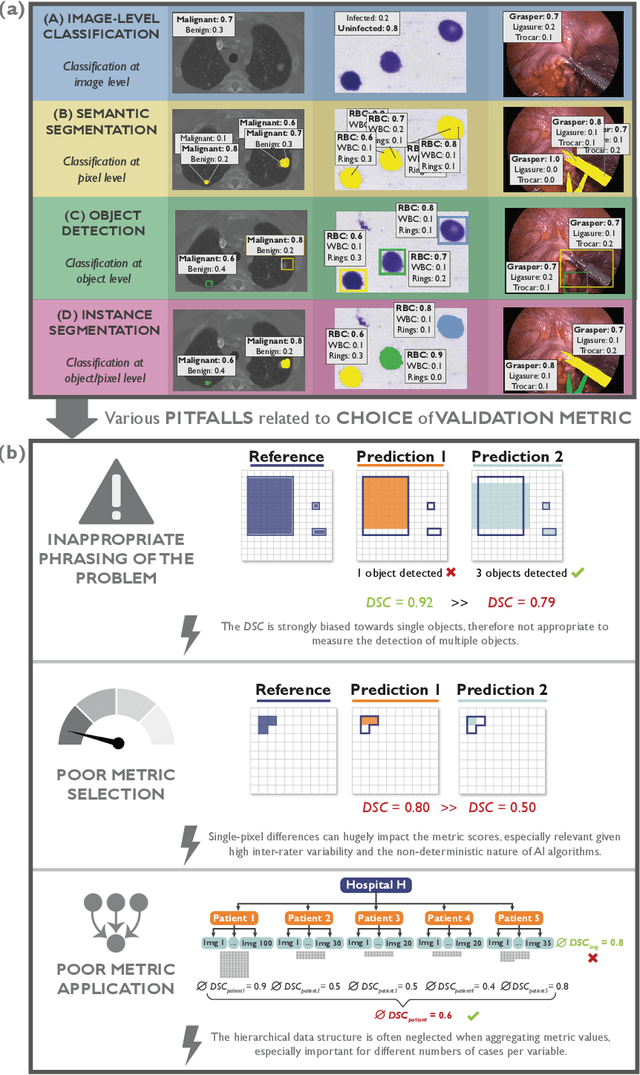
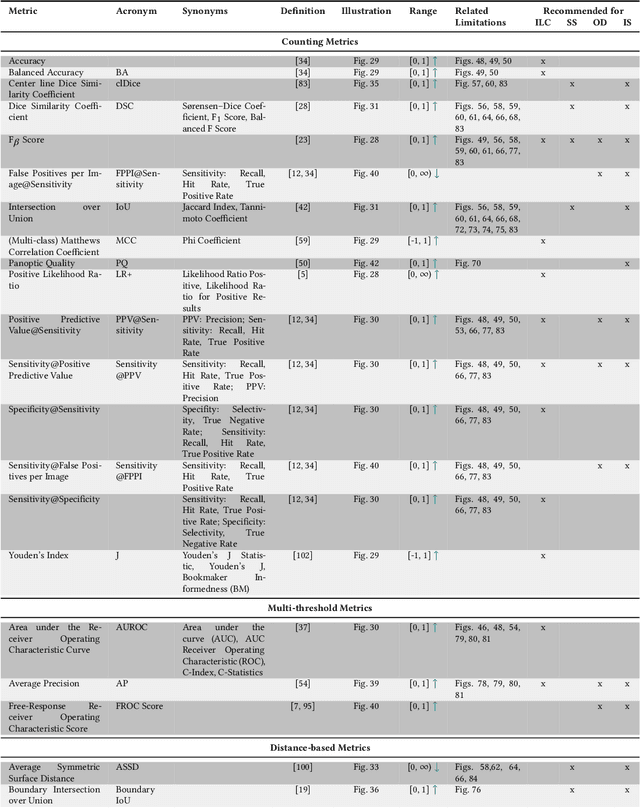
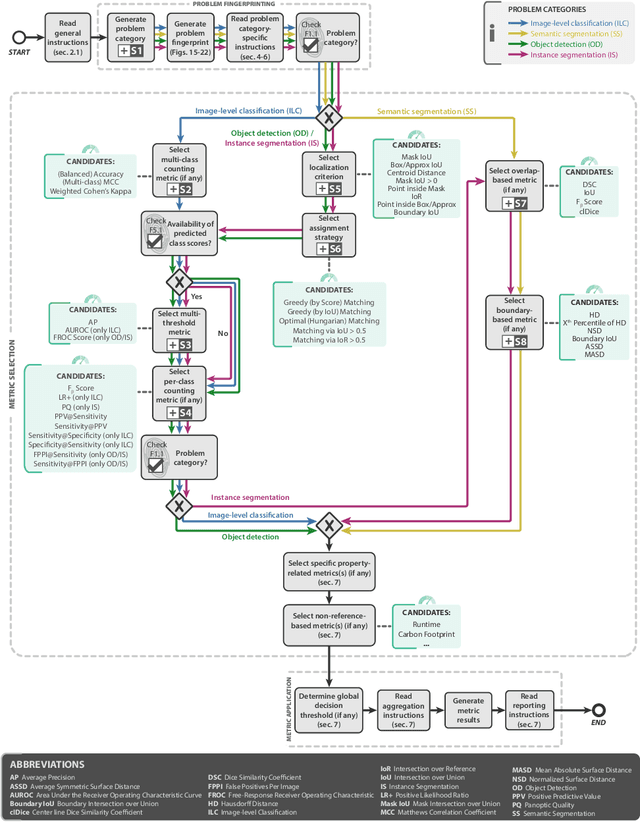
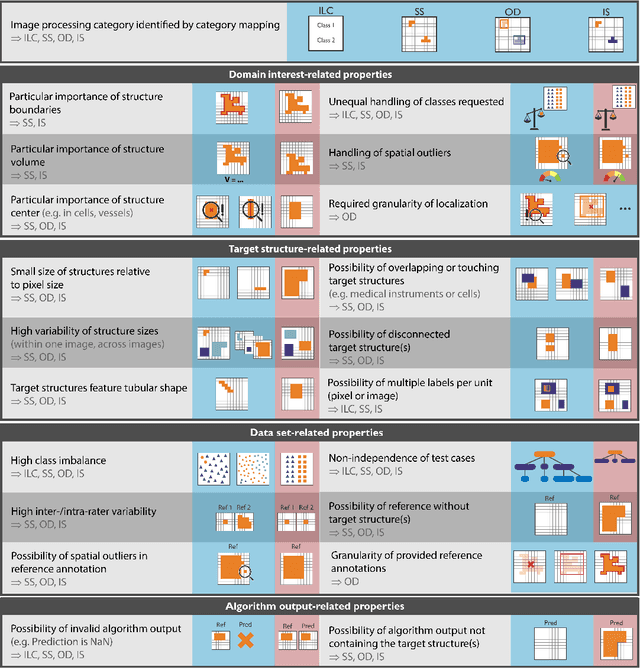
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
How can we learn from challenges? A statistical approach to driving future algorithm development
Jun 17, 2021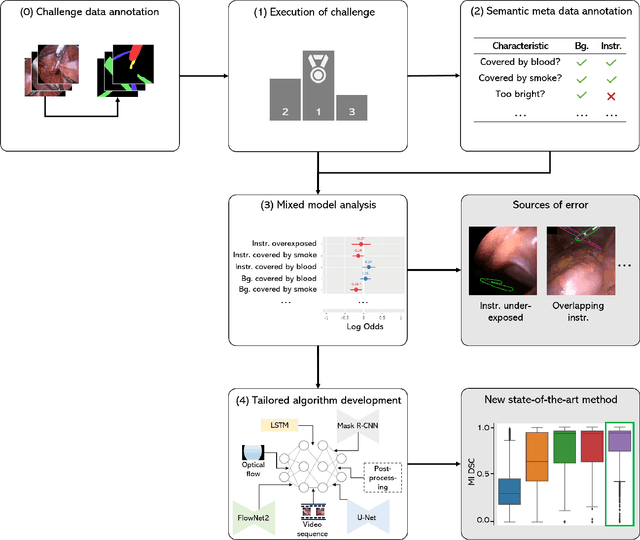


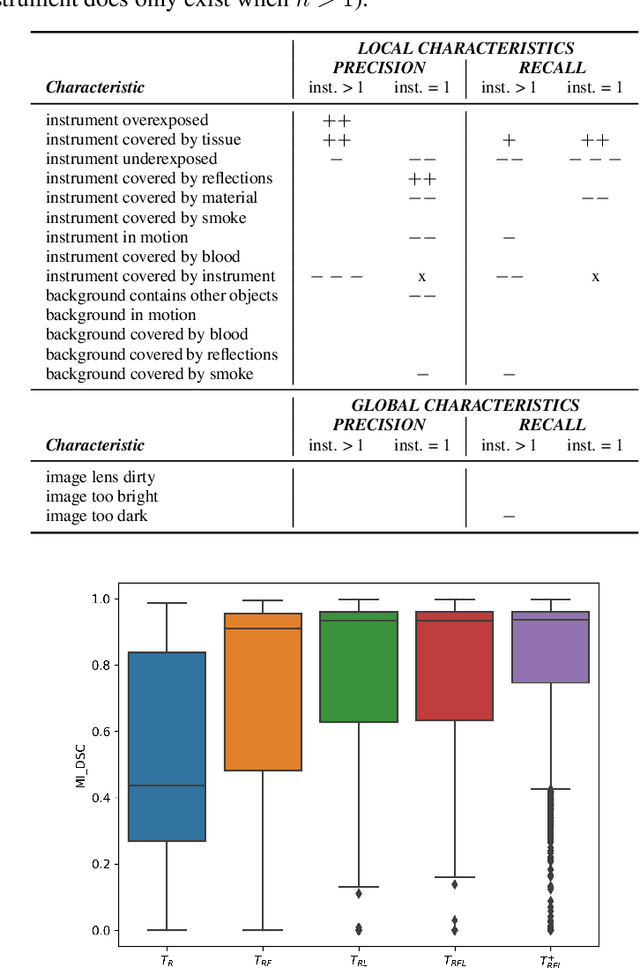
Challenges have become the state-of-the-art approach to benchmark image analysis algorithms in a comparative manner. While the validation on identical data sets was a great step forward, results analysis is often restricted to pure ranking tables, leaving relevant questions unanswered. Specifically, little effort has been put into the systematic investigation on what characterizes images in which state-of-the-art algorithms fail. To address this gap in the literature, we (1) present a statistical framework for learning from challenges and (2) instantiate it for the specific task of instrument instance segmentation in laparoscopic videos. Our framework relies on the semantic meta data annotation of images, which serves as foundation for a General Linear Mixed Models (GLMM) analysis. Based on 51,542 meta data annotations performed on 2,728 images, we applied our approach to the results of the Robust Medical Instrument Segmentation Challenge (ROBUST-MIS) challenge 2019 and revealed underexposure, motion and occlusion of instruments as well as the presence of smoke or other objects in the background as major sources of algorithm failure. Our subsequent method development, tailored to the specific remaining issues, yielded a deep learning model with state-of-the-art overall performance and specific strengths in the processing of images in which previous methods tended to fail. Due to the objectivity and generic applicability of our approach, it could become a valuable tool for validation in the field of medical image analysis and beyond. and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Machine learning-based analysis of hyperspectral images for automated sepsis diagnosis
Jun 15, 2021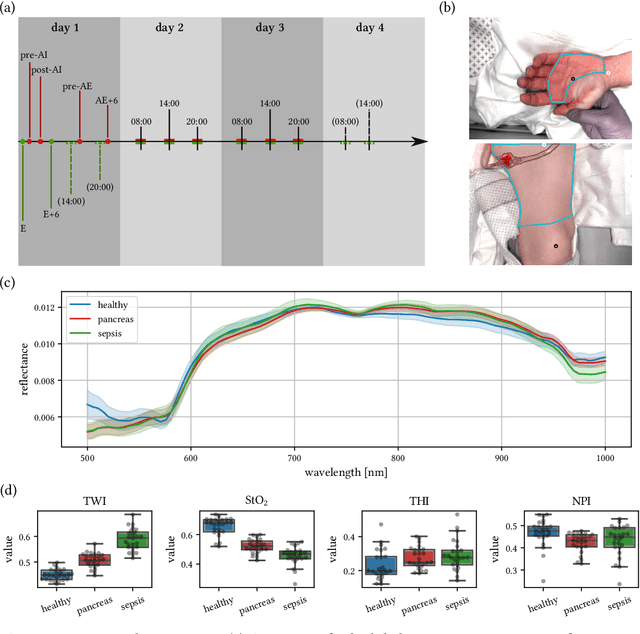
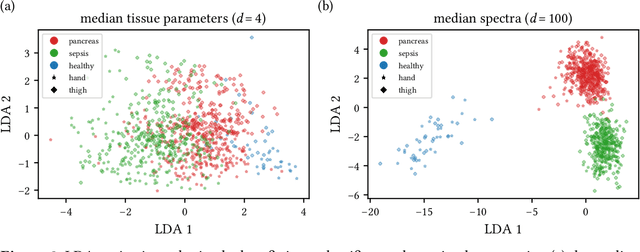
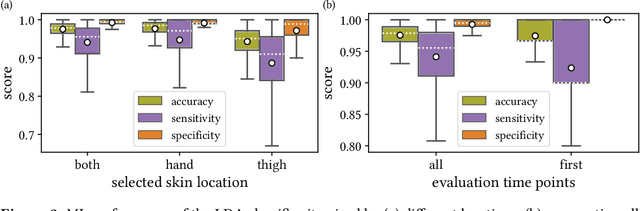
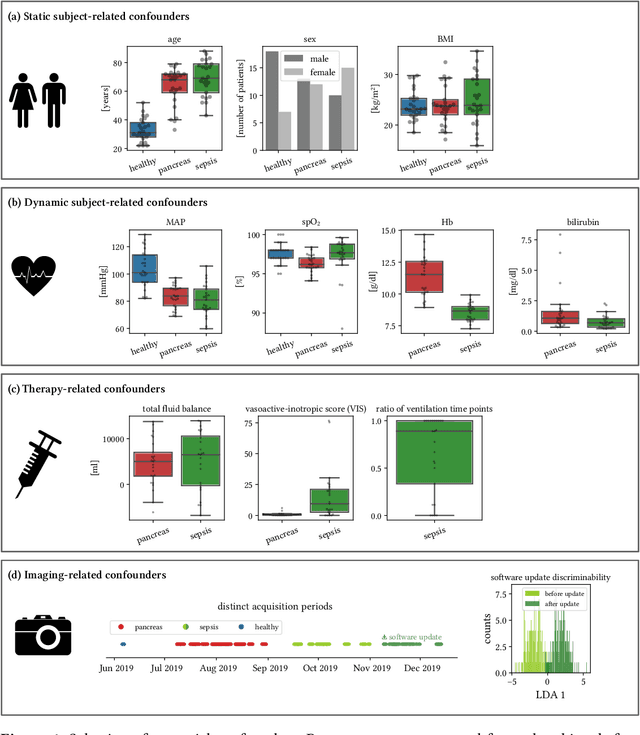
Sepsis is a leading cause of mortality and critical illness worldwide. While robust biomarkers for early diagnosis are still missing, recent work indicates that hyperspectral imaging (HSI) has the potential to overcome this bottleneck by monitoring microcirculatory alterations. Automated machine learning-based diagnosis of sepsis based on HSI data, however, has not been explored to date. Given this gap in the literature, we leveraged an existing data set to (1) investigate whether HSI-based automated diagnosis of sepsis is possible and (2) put forth a list of possible confounders relevant for HSI-based tissue classification. While we were able to classify sepsis with an accuracy of over $98\,\%$ using the existing data, our research also revealed several subject-, therapy- and imaging-related confounders that may lead to an overestimation of algorithm performance when not balanced across the patient groups. We conclude that further prospective studies, carefully designed with respect to these confounders, are necessary to confirm the preliminary results obtained in this study.