 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling instructions matter in biomedical image analysis
Jul 20, 2022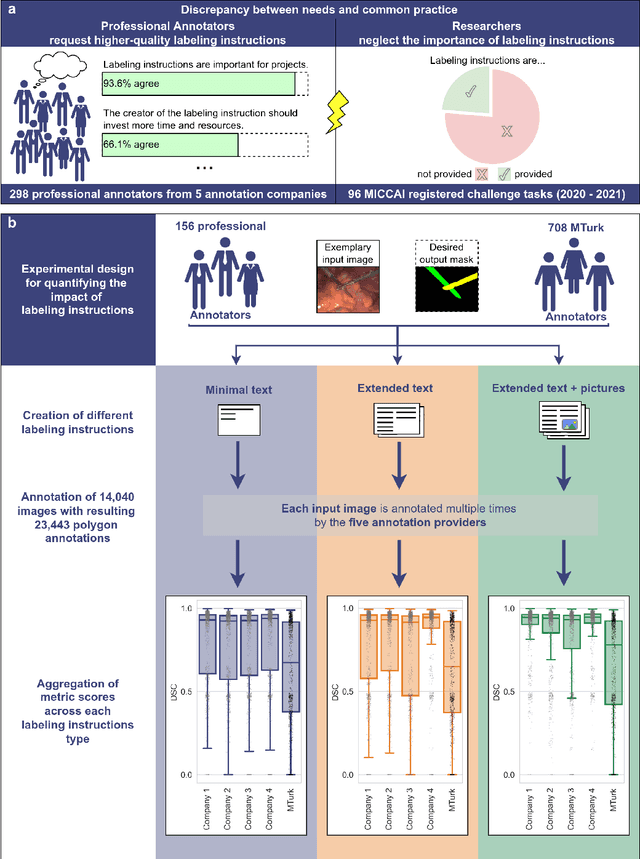
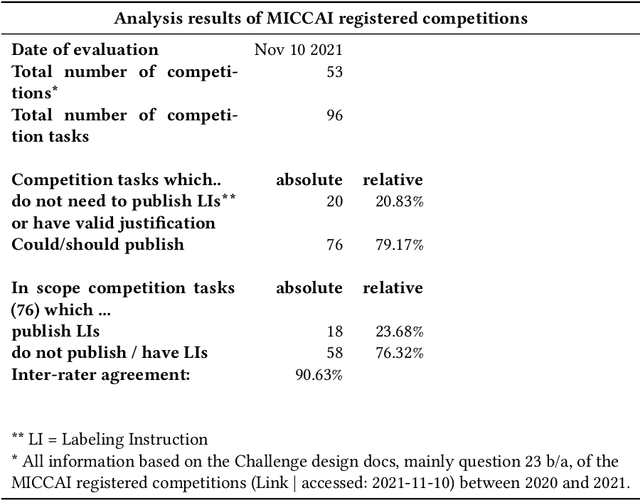
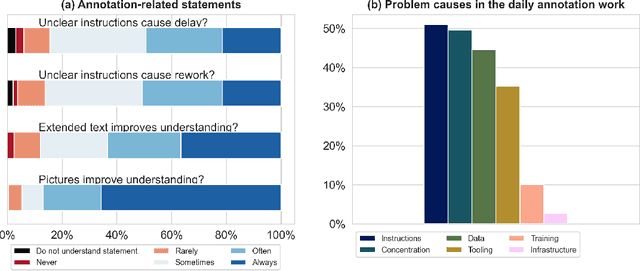
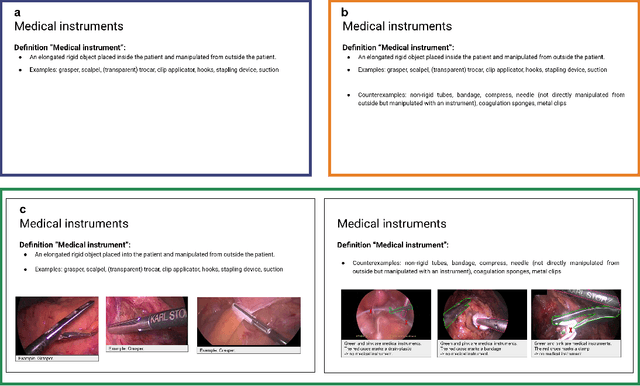
Biomedical image analysis algorithm validation depends on high-quality annotation of reference datasets, for which labeling instructions are key. Despite their importance, their optimization remains largely unexplored. Here, we present the first systematic study of labeling instructions and their impact on annotation quality in the field. Through comprehensive examination of professional practice and international competitions registered at the MICCAI Society, we uncovered a discrepancy between annotators' needs for labeling instructions and their current quality and availability. Based on an analysis of 14,040 images annotated by 156 annotators from four professional companies and 708 Amazon Mechanical Turk (MTurk) crowdworkers using instructions with different information density levels, we further found that including exemplary images significantly boosts annotation performance compared to text-only descriptions, while solely extending text descriptions does not. Finally, professional annotators constantly outperform MTurk crowdworkers. Our study raises awareness for the need of quality standards in biomedical image analysis labeling instructions.
Machine learning-based analysis of hyperspectral images for automated sepsis diagnosis
Jun 15, 2021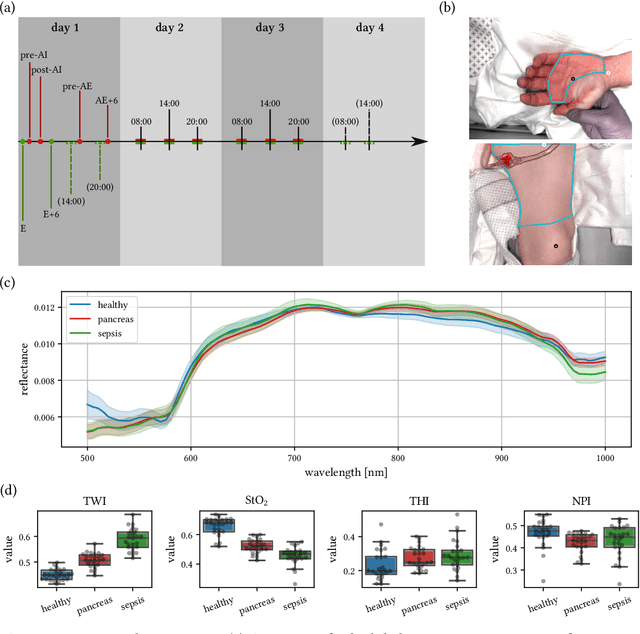
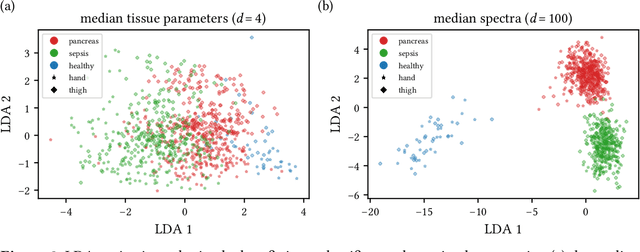
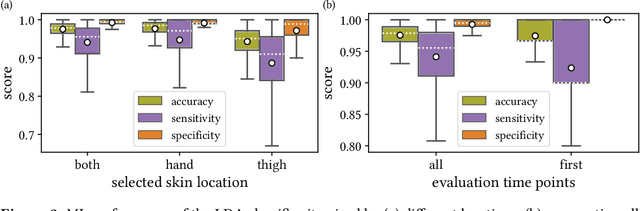
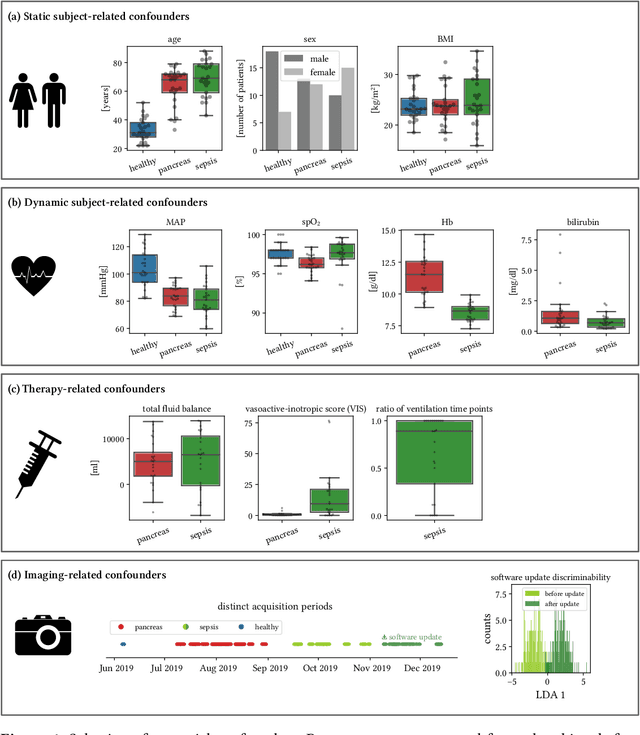
Sepsis is a leading cause of mortality and critical illness worldwide. While robust biomarkers for early diagnosis are still missing, recent work indicates that hyperspectral imaging (HSI) has the potential to overcome this bottleneck by monitoring microcirculatory alterations. Automated machine learning-based diagnosis of sepsis based on HSI data, however, has not been explored to date. Given this gap in the literature, we leveraged an existing data set to (1) investigate whether HSI-based automated diagnosis of sepsis is possible and (2) put forth a list of possible confounders relevant for HSI-based tissue classification. While we were able to classify sepsis with an accuracy of over $98\,\%$ using the existing data, our research also revealed several subject-, therapy- and imaging-related confounders that may lead to an overestimation of algorithm performance when not balanced across the patient groups. We conclude that further prospective studies, carefully designed with respect to these confounders, are necessary to confirm the preliminary results obtained in this study.