 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Energy Consumption Measurements of Heterogeneous Artificial Intelligence Workloads
Dec 03, 2022



With the rise of AI in recent years and the increase in complexity of the models, the growing demand in computational resources is starting to pose a significant challenge. The need for higher compute power is being met with increasingly more potent accelerators and the use of large compute clusters. However, the gain in prediction accuracy from large models trained on distributed and accelerated systems comes at the price of a substantial increase in energy demand, and researchers have started questioning the environmental friendliness of such AI methods at scale. Consequently, energy efficiency plays an important role for AI model developers and infrastructure operators alike. The energy consumption of AI workloads depends on the model implementation and the utilized hardware. Therefore, accurate measurements of the power draw of AI workflows on different types of compute nodes is key to algorithmic improvements and the design of future compute clusters and hardware. To this end, we present measurements of the energy consumption of two typical applications of deep learning models on different types of compute nodes. Our results indicate that 1. deriving energy consumption directly from runtime is not accurate, but the consumption of the compute node needs to be considered regarding its composition; 2. neglecting accelerator hardware on mixed nodes results in overproportional inefficiency regarding energy consumption; 3. energy consumption of model training and inference should be considered separately - while training on GPUs outperforms all other node types regarding both runtime and energy consumption, inference on CPU nodes can be comparably efficient. One advantage of our approach is that the information on energy consumption is available to all users of the supercomputer, enabling an easy transfer to other workloads alongside a raise in user-awareness of energy consumption.
Classification of diffraction patterns using a convolutional neural network in single particle imaging experiments performed at X-ray free-electron lasers
Dec 16, 2021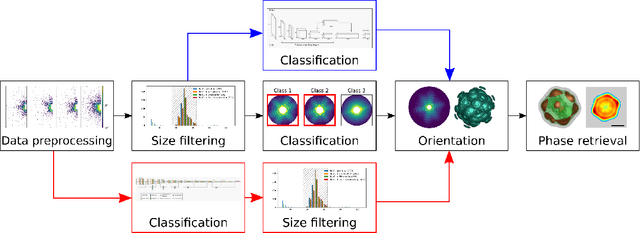
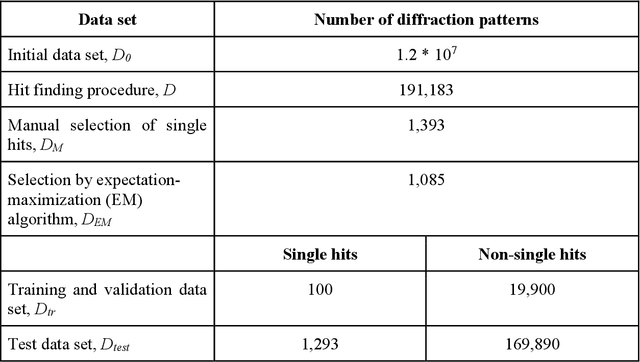

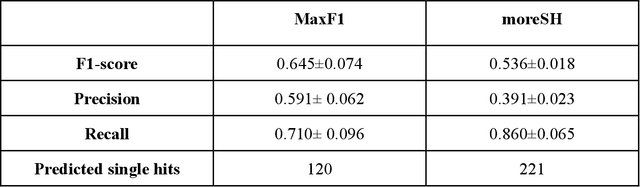
Single particle imaging (SPI) at X-ray free electron lasers (XFELs) is particularly well suited to determine the 3D structure of particles in their native environment. For a successful reconstruction, diffraction patterns originating from a single hit must be isolated from a large number of acquired patterns. We propose to formulate this task as an image classification problem and solve it using convolutional neural network (CNN) architectures. Two CNN configurations are developed: one that maximises the F1-score and one that emphasises high recall. We also combine the CNNs with expectation maximization (EM) selection as well as size filtering. We observed that our CNN selections have lower contrast in power spectral density functions relative to the EM selection, used in our previous work. However, the reconstruction of our CNN-based selections gives similar results. Introducing CNNs into SPI experiments allows streamlining the reconstruction pipeline, enables researchers to classify patterns on the fly, and, as a consequence, enables them to tightly control the duration of their experiments. We think that bringing non-standard artificial intelligence (AI) based solutions in a well-described SPI analysis workflow may be beneficial for the future development of the SPI experiments.
How can we learn from challenges? A statistical approach to driving future algorithm development
Jun 17, 2021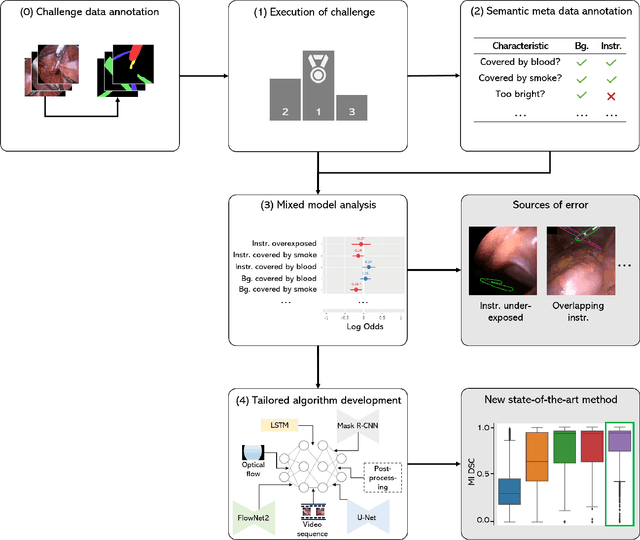


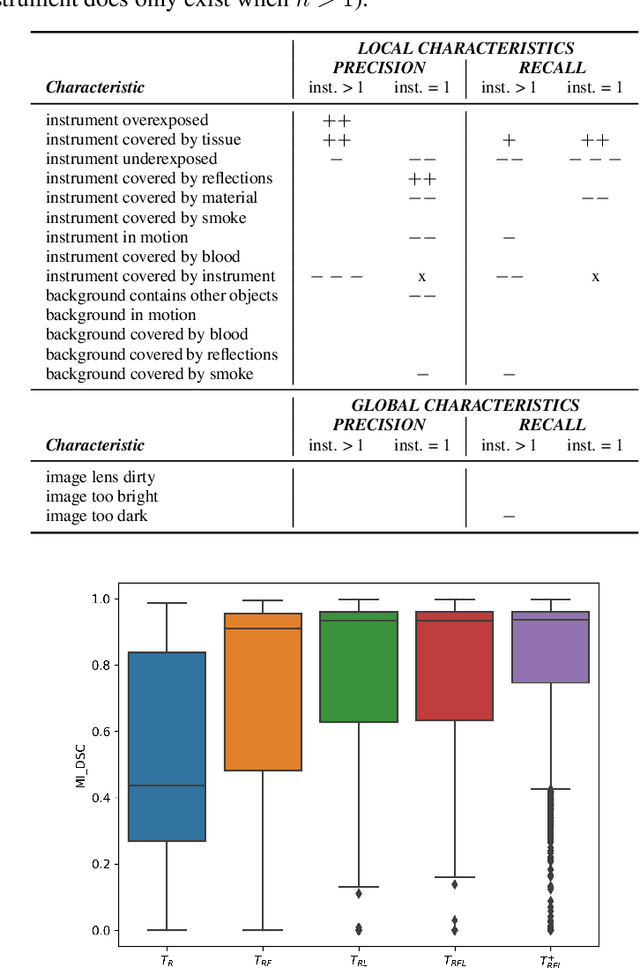
Challenges have become the state-of-the-art approach to benchmark image analysis algorithms in a comparative manner. While the validation on identical data sets was a great step forward, results analysis is often restricted to pure ranking tables, leaving relevant questions unanswered. Specifically, little effort has been put into the systematic investigation on what characterizes images in which state-of-the-art algorithms fail. To address this gap in the literature, we (1) present a statistical framework for learning from challenges and (2) instantiate it for the specific task of instrument instance segmentation in laparoscopic videos. Our framework relies on the semantic meta data annotation of images, which serves as foundation for a General Linear Mixed Models (GLMM) analysis. Based on 51,542 meta data annotations performed on 2,728 images, we applied our approach to the results of the Robust Medical Instrument Segmentation Challenge (ROBUST-MIS) challenge 2019 and revealed underexposure, motion and occlusion of instruments as well as the presence of smoke or other objects in the background as major sources of algorithm failure. Our subsequent method development, tailored to the specific remaining issues, yielded a deep learning model with state-of-the-art overall performance and specific strengths in the processing of images in which previous methods tended to fail. Due to the objectivity and generic applicability of our approach, it could become a valuable tool for validation in the field of medical image analysis and beyond. and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Representing Ambiguity in Registration Problems with Conditional Invertible Neural Networks
Dec 15, 2020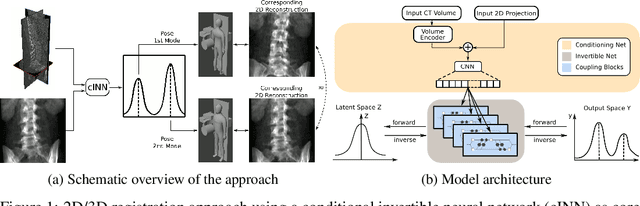
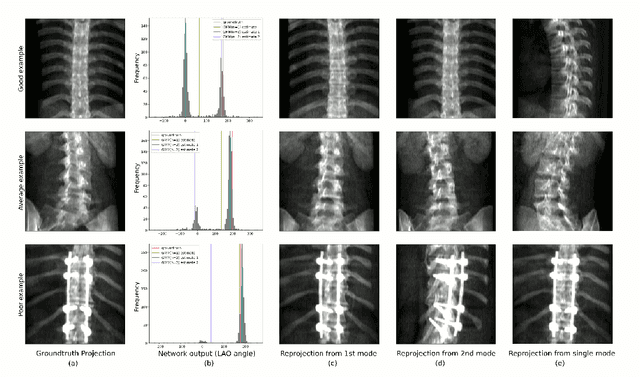
Image registration is the basis for many applications in the fields of medical image computing and computer assisted interventions. One example is the registration of 2D X-ray images with preoperative three-dimensional computed tomography (CT) images in intraoperative surgical guidance systems. Due to the high safety requirements in medical applications, estimating registration uncertainty is of a crucial importance in such a scenario. However, previously proposed methods, including classical iterative registration methods and deep learning-based methods have one characteristic in common: They lack the capacity to represent the fact that a registration problem may be inherently ambiguous, meaning that multiple (substantially different) plausible solutions exist. To tackle this limitation, we explore the application of invertible neural networks (INN) as core component of a registration methodology. In the proposed framework, INNs enable going beyond point estimates as network output by representing the possible solutions to a registration problem by a probability distribution that encodes different plausible solutions via multiple modes. In a first feasibility study, we test the approach for a 2D 3D registration setting by registering spinal CT volumes to X-ray images. To this end, we simulate the X-ray images taken by a C-Arm with multiple orientations using the principle of digitially reconstructed radiographs (DRRs). Due to the symmetry of human spine, there are potentially multiple substantially different poses of the C-Arm that can lead to similar projections. The hypothesis of this work is that the proposed approach is able to identify multiple solutions in such ambiguous registration problems.