 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication-driven Validation of Posteriors in Inverse Problems
Sep 18, 2023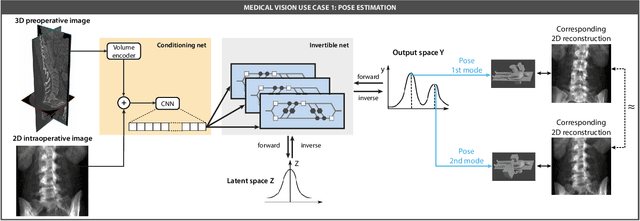
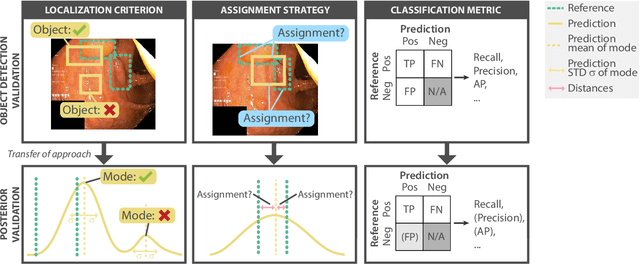
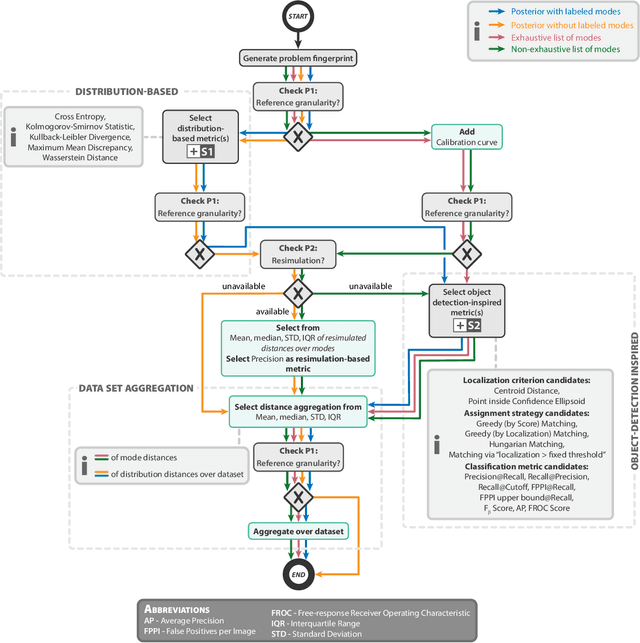
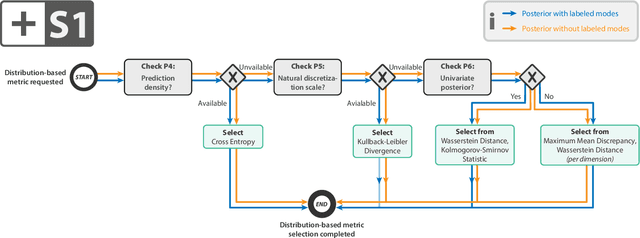
Current deep learning-based solutions for image analysis tasks are commonly incapable of handling problems to which multiple different plausible solutions exist. In response, posterior-based methods such as conditional Diffusion Models and Invertible Neural Networks have emerged; however, their translation is hampered by a lack of research on adequate validation. In other words, the way progress is measured often does not reflect the needs of the driving practical application. Closing this gap in the literature, we present the first systematic framework for the application-driven validation of posterior-based methods in inverse problems. As a methodological novelty, it adopts key principles from the field of object detection validation, which has a long history of addressing the question of how to locate and match multiple object instances in an image. Treating modes as instances enables us to perform mode-centric validation, using well-interpretable metrics from the application perspective. We demonstrate the value of our framework through instantiations for a synthetic toy example and two medical vision use cases: pose estimation in surgery and imaging-based quantification of functional tissue parameters for diagnostics. Our framework offers key advantages over common approaches to posterior validation in all three examples and could thus revolutionize performance assessment in inverse problems.
Training Invertible Neural Networks as Autoencoders
Mar 21, 2023Autoencoders are able to learn useful data representations in an unsupervised matter and have been widely used in various machine learning and computer vision tasks. In this work, we present methods to train Invertible Neural Networks (INNs) as (variational) autoencoders which we call INN (variational) autoencoders. Our experiments on MNIST, CIFAR and CelebA show that for low bottleneck sizes our INN autoencoder achieves results similar to the classical autoencoder. However, for large bottleneck sizes our INN autoencoder outperforms its classical counterpart. Based on the empirical results, we hypothesize that INN autoencoders might not have any intrinsic information loss and thereby are not bounded to a maximal number of layers (depth) after which only suboptimal results can be achieved.
* Conference Paper at GCPR2019
Towards Multimodal Depth Estimation from Light Fields
Apr 01, 2022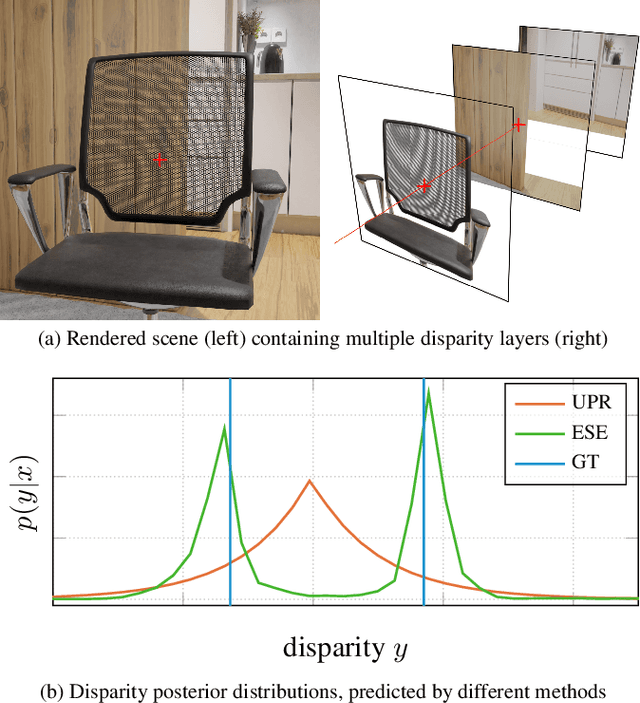
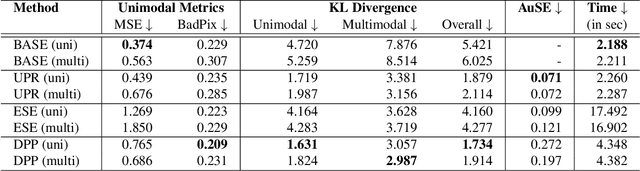

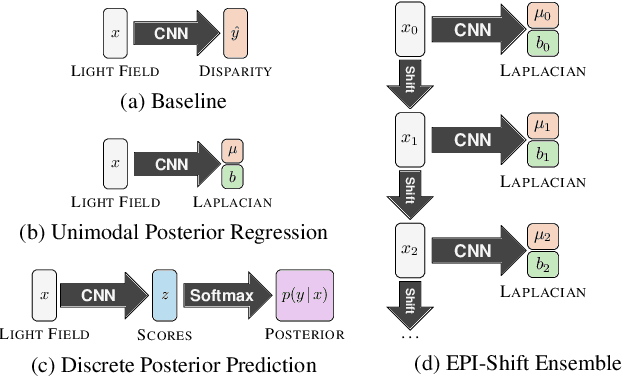
Light field applications, especially light field rendering and depth estimation, developed rapidly in recent years. While state-of-the-art light field rendering methods handle semi-transparent and reflective objects well, depth estimation methods either ignore these cases altogether or only deliver a weak performance. We argue that this is due current methods only considering a single "true" depth, even when multiple objects at different depths contributed to the color of a single pixel. Based on the simple idea of outputting a posterior depth distribution instead of only a single estimate, we develop and explore several different deep-learning-based approaches to the problem. Additionally, we contribute the first "multimodal light field depth dataset" that contains the depths of all objects which contribute to the color of a pixel. This allows us to supervise the multimodal depth prediction and also validate all methods by measuring the KL divergence of the predicted posteriors. With our thorough analysis and novel dataset, we aim to start a new line of depth estimation research that overcomes some of the long-standing limitations of this field.
Review of Disentanglement Approaches for Medical Applications -- Towards Solving the Gordian Knot of Generative Models in Healthcare
Mar 21, 2022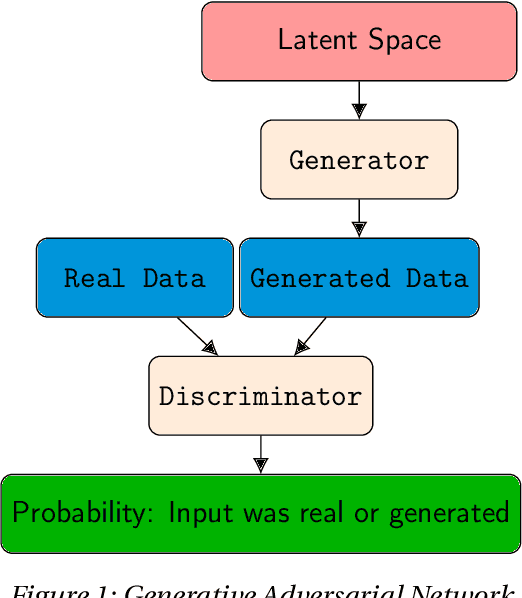
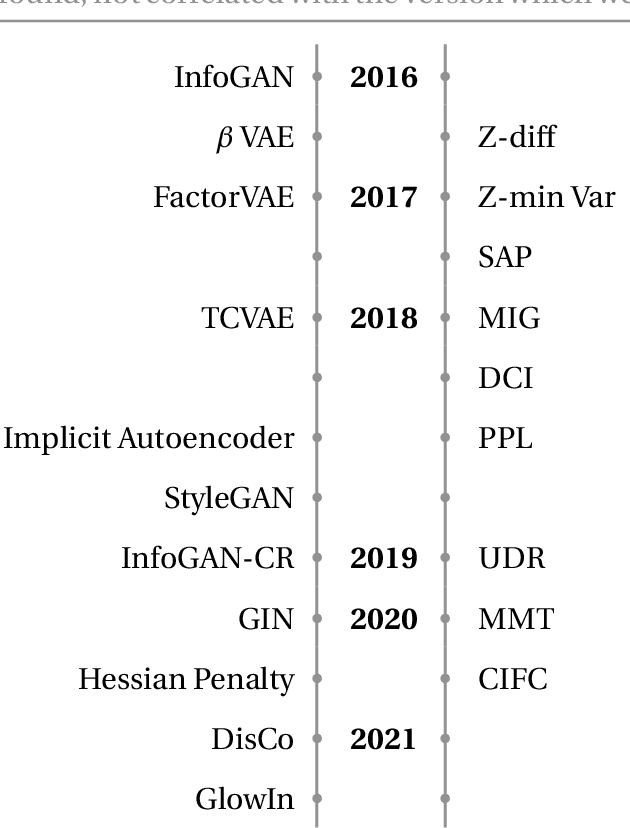
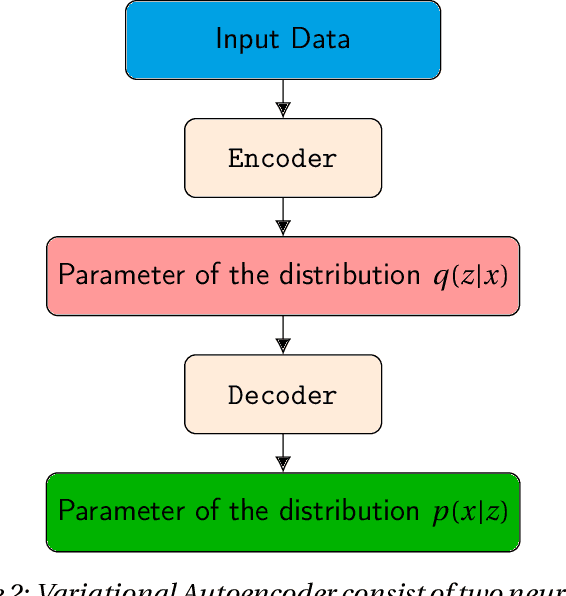
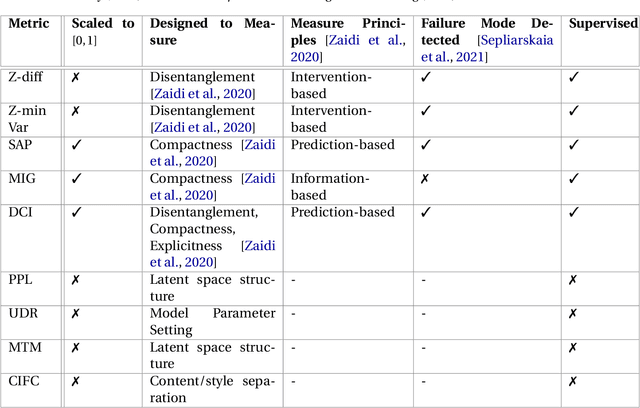
Deep neural networks are commonly used for medical purposes such as image generation, segmentation, or classification. Besides this, they are often criticized as black boxes as their decision process is often not human interpretable. Encouraging the latent representation of a generative model to be disentangled offers new perspectives of control and interpretability. Understanding the data generation process could help to create artificial medical data sets without violating patient privacy, synthesizing different data modalities, or discovering data generating characteristics. These characteristics might unravel novel relationships that can be related to genetic traits or patient outcomes. In this paper, we give a comprehensive overview of popular generative models, like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Flow-based Models. Furthermore, we summarize the different notions of disentanglement, review approaches to disentangle latent space representations and metrics to evaluate the degree of disentanglement. After introducing the theoretical frameworks, we give an overview of recent medical applications and discuss the impact and importance of disentanglement approaches for medical applications.
Exoplanet Characterization using Conditional Invertible Neural Networks
Jan 31, 2022



The characterization of an exoplanet's interior is an inverse problem, which requires statistical methods such as Bayesian inference in order to be solved. Current methods employ Markov Chain Monte Carlo (MCMC) sampling to infer the posterior probability of planetary structure parameters for a given exoplanet. These methods are time consuming since they require the calculation of a large number of planetary structure models. To speed up the inference process when characterizing an exoplanet, we propose to use conditional invertible neural networks (cINNs) to calculate the posterior probability of the internal structure parameters. cINNs are a special type of neural network which excel in solving inverse problems. We constructed a cINN using FrEIA, which was then trained on a database of $5.6\cdot 10^6$ internal structure models to recover the inverse mapping between internal structure parameters and observable features (i.e., planetary mass, planetary radius and composition of the host star). The cINN method was compared to a Metropolis-Hastings MCMC. For that we repeated the characterization of the exoplanet K2-111 b, using both the MCMC method and the trained cINN. We show that the inferred posterior probability of the internal structure parameters from both methods are very similar, with the biggest differences seen in the exoplanet's water content. Thus cINNs are a possible alternative to the standard time-consuming sampling methods. Indeed, using cINNs allows for orders of magnitude faster inference of an exoplanet's composition than what is possible using an MCMC method, however, it still requires the computation of a large database of internal structures to train the cINN. Since this database is only computed once, we found that using a cINN is more efficient than an MCMC, when more than 10 exoplanets are characterized using the same cINN.
Conditional Invertible Neural Networks for Diverse Image-to-Image Translation
May 05, 2021

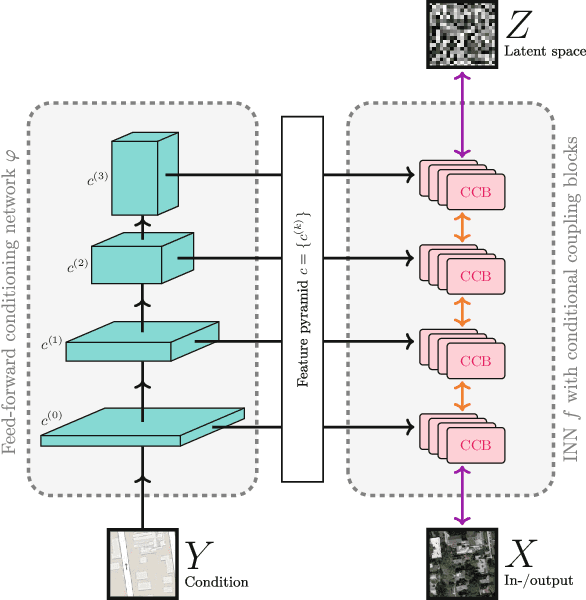
We introduce a new architecture called a conditional invertible neural network (cINN), and use it to address the task of diverse image-to-image translation for natural images. This is not easily possible with existing INN models due to some fundamental limitations. The cINN combines the purely generative INN model with an unconstrained feed-forward network, which efficiently preprocesses the conditioning image into maximally informative features. All parameters of a cINN are jointly optimized with a stable, maximum likelihood-based training procedure. Even though INN-based models have received far less attention in the literature than GANs, they have been shown to have some remarkable properties absent in GANs, e.g. apparent immunity to mode collapse. We find that our cINNs leverage these properties for image-to-image translation, demonstrated on day to night translation and image colorization. Furthermore, we take advantage of our bidirectional cINN architecture to explore and manipulate emergent properties of the latent space, such as changing the image style in an intuitive way.
Benchmarking Invertible Architectures on Inverse Problems
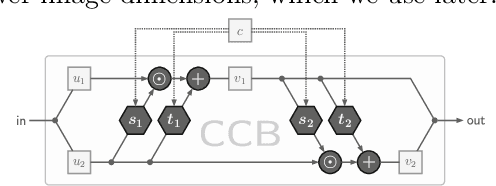
Jan 26, 2021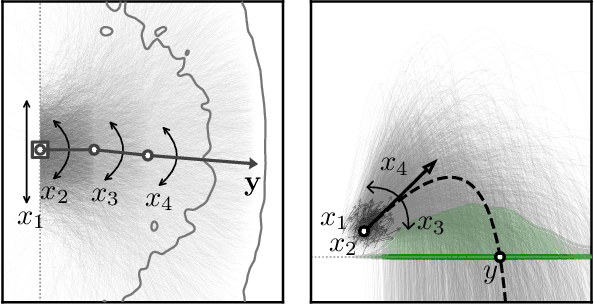
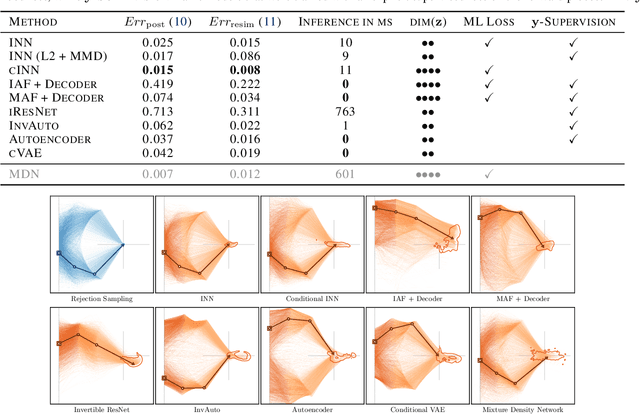
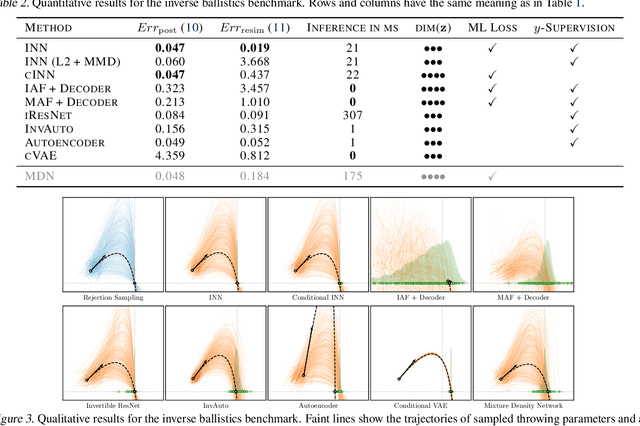
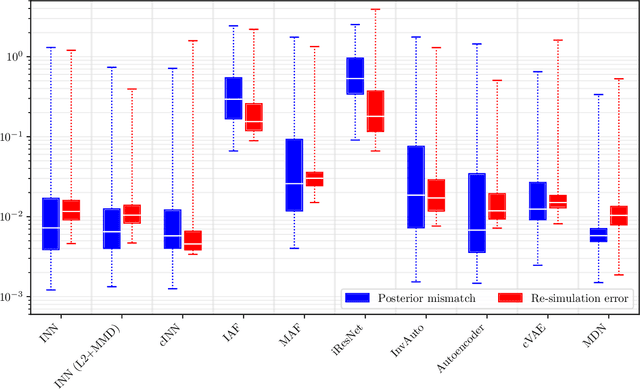
Recent work demonstrated that flow-based invertible neural networks are promising tools for solving ambiguous inverse problems. Following up on this, we investigate how ten invertible architectures and related models fare on two intuitive, low-dimensional benchmark problems, obtaining the best results with coupling layers and simple autoencoders. We hope that our initial efforts inspire other researchers to evaluate their invertible architectures in the same setting and put forth additional benchmarks, so our evaluation may eventually grow into an official community challenge.
Representing Ambiguity in Registration Problems with Conditional Invertible Neural Networks
Dec 15, 2020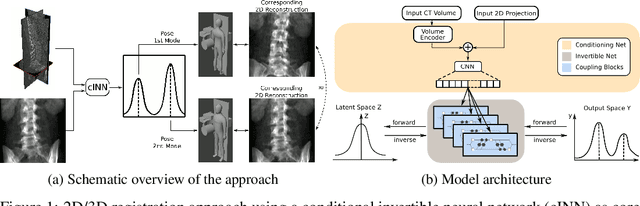
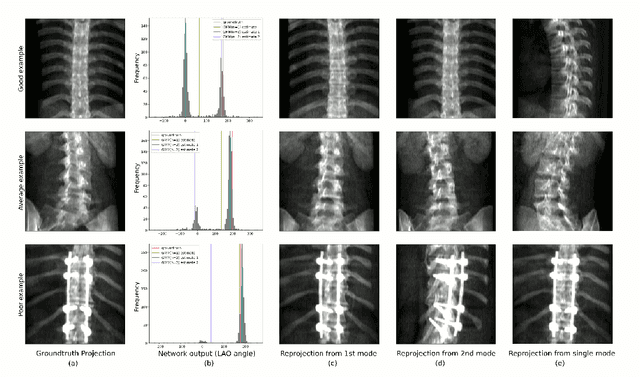
Image registration is the basis for many applications in the fields of medical image computing and computer assisted interventions. One example is the registration of 2D X-ray images with preoperative three-dimensional computed tomography (CT) images in intraoperative surgical guidance systems. Due to the high safety requirements in medical applications, estimating registration uncertainty is of a crucial importance in such a scenario. However, previously proposed methods, including classical iterative registration methods and deep learning-based methods have one characteristic in common: They lack the capacity to represent the fact that a registration problem may be inherently ambiguous, meaning that multiple (substantially different) plausible solutions exist. To tackle this limitation, we explore the application of invertible neural networks (INN) as core component of a registration methodology. In the proposed framework, INNs enable going beyond point estimates as network output by representing the possible solutions to a registration problem by a probability distribution that encodes different plausible solutions via multiple modes. In a first feasibility study, we test the approach for a 2D 3D registration setting by registering spinal CT volumes to X-ray images. To this end, we simulate the X-ray images taken by a C-Arm with multiple orientations using the principle of digitially reconstructed radiographs (DRRs). Due to the symmetry of human spine, there are potentially multiple substantially different poses of the C-Arm that can lead to similar projections. The hypothesis of this work is that the proposed approach is able to identify multiple solutions in such ambiguous registration problems.
Invertible Neural Networks for Uncertainty Quantification in Photoacoustic Imaging
Nov 10, 2020



Multispectral photoacoustic imaging (PAI) is an emerging imaging modality which enables the recovery of functional tissue parameters such as blood oxygenation. However, the underlying inverse problems are potentially ill-posed, meaning that radically different tissue properties may - in theory - yield comparable measurements. In this work, we present a new approach for handling this specific type of uncertainty by leveraging the concept of conditional invertible neural networks (cINNs). Specifically, we propose going beyond commonly used point estimates for tissue oxygenation and converting single-pixel initial pressure spectra to the full posterior probability density. This way, the inherent ambiguity of a problem can be encoded with multiple modes in the output. Based on the presented architecture, we demonstrate two use cases which leverage this information to not only detect and quantify but also to compensate for uncertainties: (1) photoacoustic device design and (2) optimization of photoacoustic image acquisition. Our in silico studies demonstrate the potential of the proposed methodology to become an important building block for uncertainty-aware reconstruction of physiological parameters with PAI.
Learning Robust Models Using The Principle of Independent Causal Mechanisms
Oct 14, 2020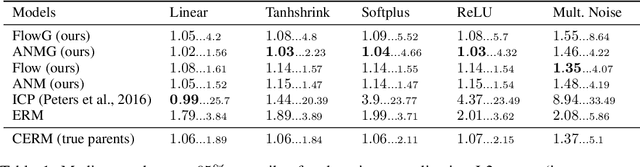

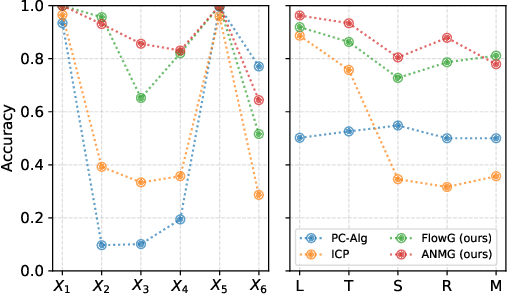
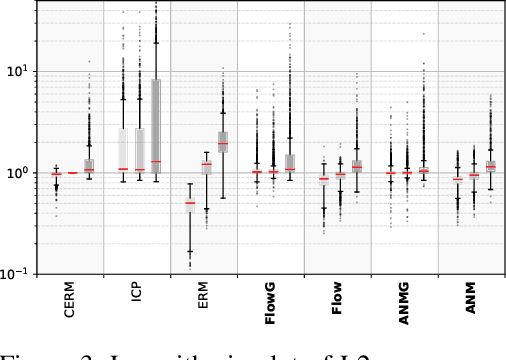
Standard supervised learning breaks down under data distribution shift. However, the principle of independent causal mechanisms (ICM, Peters et al. (2017)) can turn this weakness into an opportunity: one can take advantage of distribution shift between different environments during training in order to obtain more robust models. We propose a new gradient-based learning framework whose objective function is derived from the ICM principle. We show theoretically and experimentally that neural networks trained in this framework focus on relations remaining invariant across environments and ignore unstable ones. Moreover, we prove that the recovered stable relations correspond to the true causal mechanisms under certain conditions. In both regression and classification, the resulting models generalize well to unseen scenarios where traditionally trained models fail.