 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Depth Estimation from Light Fields
Apr 01, 2022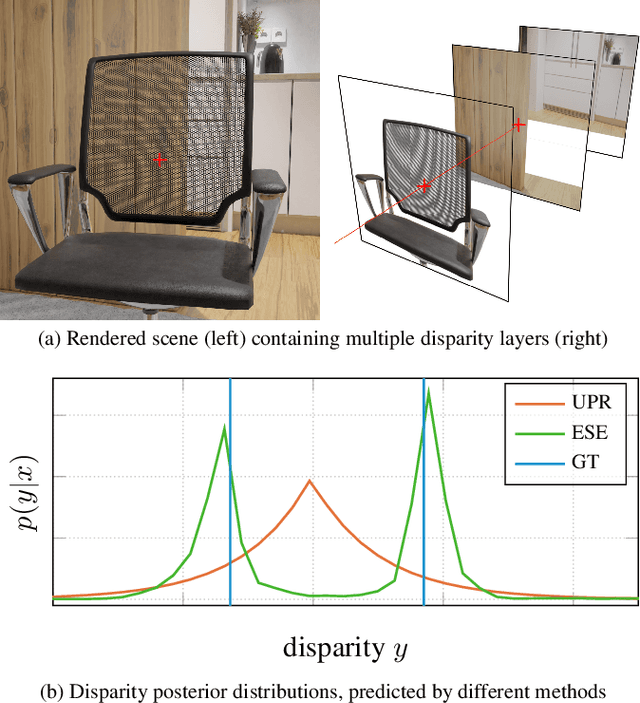
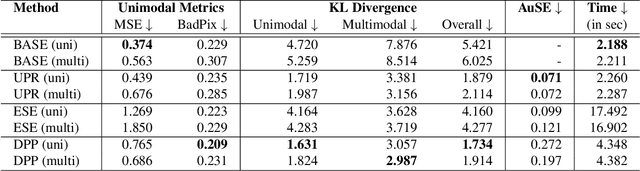

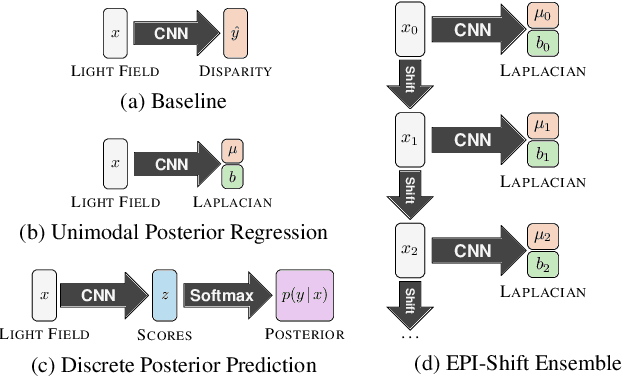
Light field applications, especially light field rendering and depth estimation, developed rapidly in recent years. While state-of-the-art light field rendering methods handle semi-transparent and reflective objects well, depth estimation methods either ignore these cases altogether or only deliver a weak performance. We argue that this is due current methods only considering a single "true" depth, even when multiple objects at different depths contributed to the color of a single pixel. Based on the simple idea of outputting a posterior depth distribution instead of only a single estimate, we develop and explore several different deep-learning-based approaches to the problem. Additionally, we contribute the first "multimodal light field depth dataset" that contains the depths of all objects which contribute to the color of a pixel. This allows us to supervise the multimodal depth prediction and also validate all methods by measuring the KL divergence of the predicted posteriors. With our thorough analysis and novel dataset, we aim to start a new line of depth estimation research that overcomes some of the long-standing limitations of this field.
Neural Head Avatars from Monocular RGB Videos
Dec 02, 2021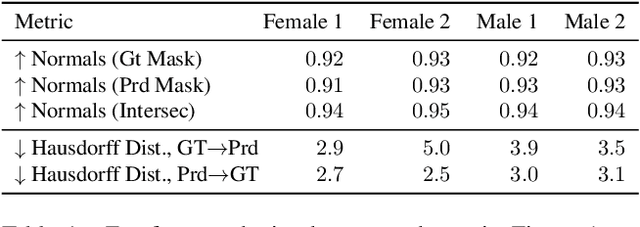
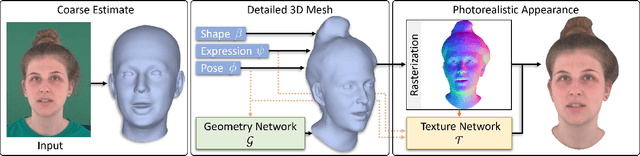
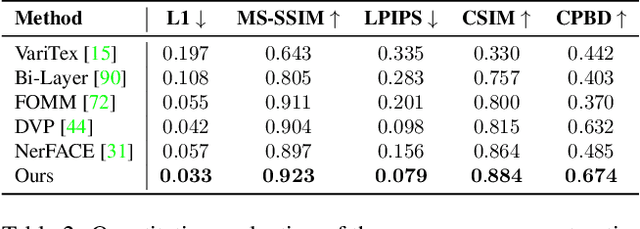
We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. Our representation can be learned from a monocular RGB portrait video that features a range of different expressions and views. Specifically, we propose a hybrid representation consisting of a morphable model for the coarse shape and expressions of the face, and two feed-forward networks, predicting vertex offsets of the underlying mesh as well as a view- and expression-dependent texture. We demonstrate that this representation is able to accurately extrapolate to unseen poses and view points, and generates natural expressions while providing sharp texture details. Compared to previous works on head avatars, our method provides a disentangled shape and appearance model of the complete human head (including hair) that is compatible with the standard graphics pipeline. Moreover, it quantitatively and qualitatively outperforms current state of the art in terms of reconstruction quality and novel-view synthesis.
Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift
Sep 19, 2019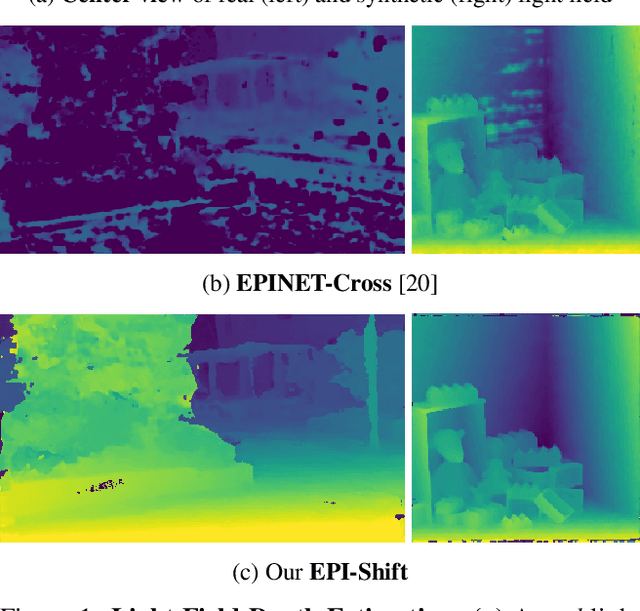


We propose a method for depth estimation from light field data, based on a fully convolutional neural network architecture. Our goal is to design a pipeline which achieves highly accurate results for small- and wide-baseline light fields. Since light field training data is scarce, all learning-based approaches use a small receptive field and operate on small disparity ranges. In order to work with wide-baseline light fields, we introduce the idea of EPI-Shift: To virtually shift the light field stack which enables to retain a small receptive field, independent of the disparity range. In this way, our approach "learns to think outside the box of the receptive field". Our network performs joint classification of integer disparities and regression of disparity-offsets. A U-Net component provides excellent long-range smoothing. EPI-Shift considerably outperforms the state-of-the-art learning-based approaches and is on par with hand-crafted methods. We demonstrate this on a publicly available, synthetic, small-baseline benchmark and on large-baseline real-world recordings.