 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Depth Estimation from Light Fields
Apr 01, 2022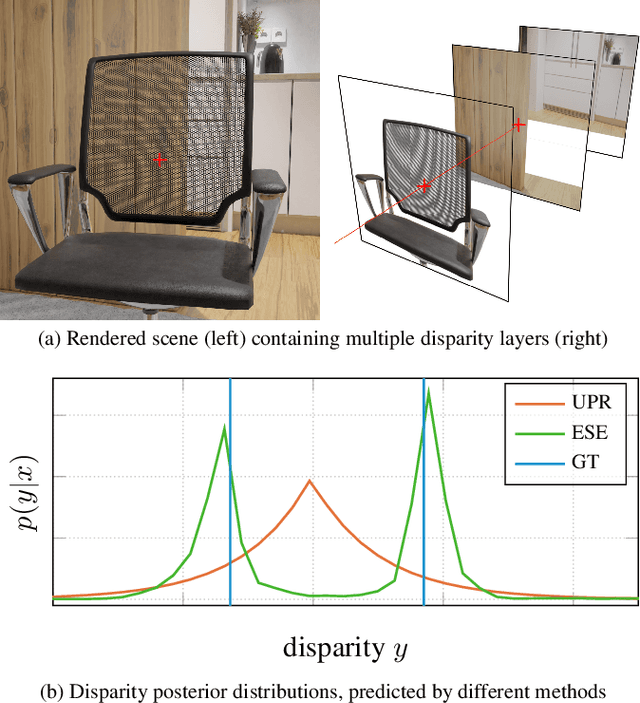
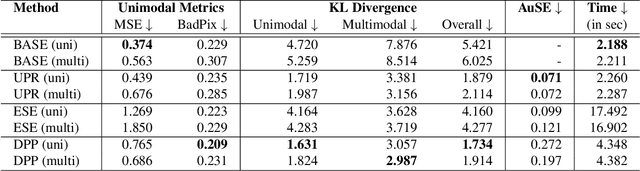

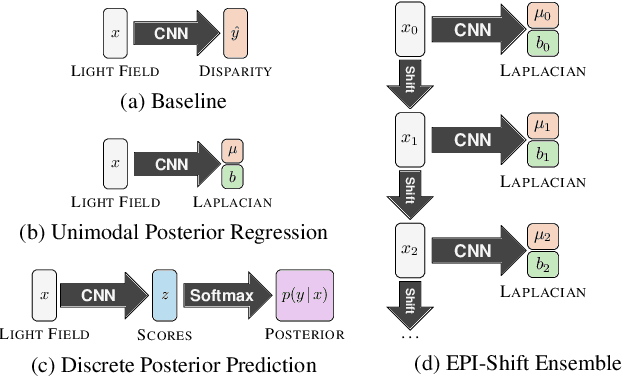
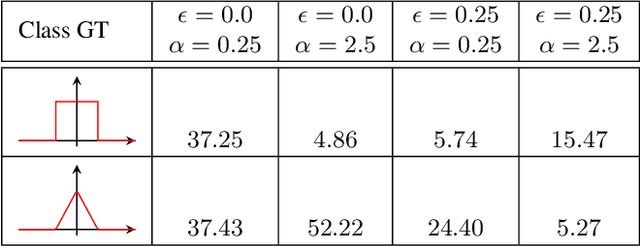
Light field applications, especially light field rendering and depth estimation, developed rapidly in recent years. While state-of-the-art light field rendering methods handle semi-transparent and reflective objects well, depth estimation methods either ignore these cases altogether or only deliver a weak performance. We argue that this is due current methods only considering a single "true" depth, even when multiple objects at different depths contributed to the color of a single pixel. Based on the simple idea of outputting a posterior depth distribution instead of only a single estimate, we develop and explore several different deep-learning-based approaches to the problem. Additionally, we contribute the first "multimodal light field depth dataset" that contains the depths of all objects which contribute to the color of a pixel. This allows us to supervise the multimodal depth prediction and also validate all methods by measuring the KL divergence of the predicted posteriors. With our thorough analysis and novel dataset, we aim to start a new line of depth estimation research that overcomes some of the long-standing limitations of this field.
Generative Classifiers as a Basis for Trustworthy Computer Vision
Jul 29, 2020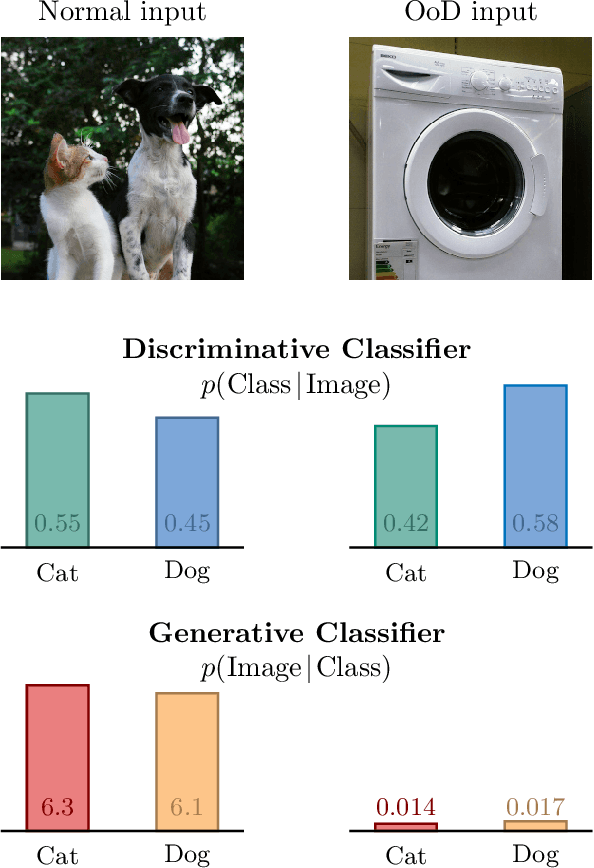
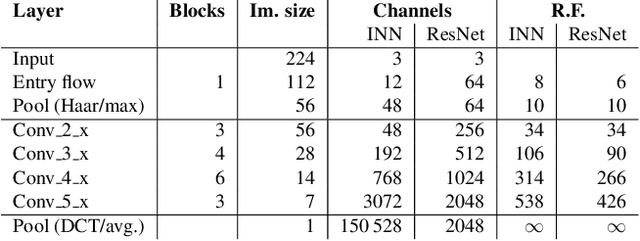
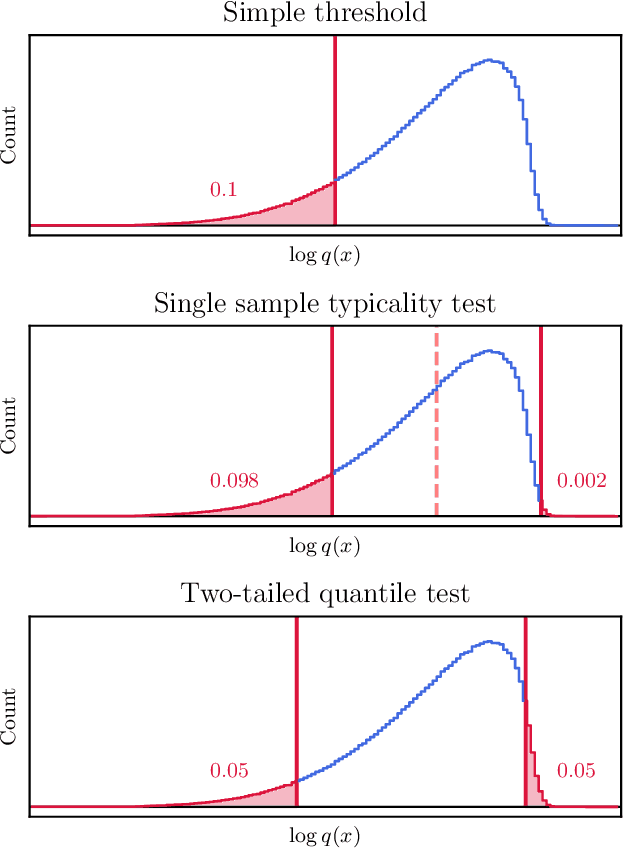
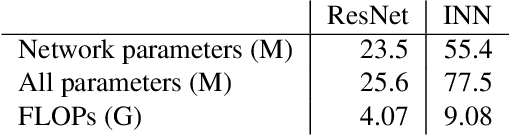
With the maturing of deep learning systems, trustworthiness is becoming increasingly important for model assessment. We understand trustworthiness as the combination of explainability and robustness. Generative classifiers (GCs) are a promising class of models that are said to naturally accomplish these qualities. However, this has mostly been demonstrated on simple datasets such as MNIST, SVHN and CIFAR in the past. In this work, we firstly develop an architecture and training scheme that allows for GCs to be trained on the ImageNet classification task, a more relevant level of complexity for practical computer vision. The resulting models use an invertible neural network architecture and achieve a competetive ImageNet top-1 accuracy of up to 76.2%. Secondly, we show the large potential of GCs for trustworthiness. Explainability and some aspects of robustness are vastly improved compared to standard feed-forward models, even when the GCs are just applied naively. While not all trustworthiness problems are solved completely, we argue from our observations that GCs are an extremely promising basis for further algorithms and modifications, as have been developed in the past for feedforward models to increase their trustworthiness. We release our trained model for download in the hope that it serves as a starting point for various other generative classification tasks in much the same way as pretrained ResNet models do for discriminative classification.
Exact Information Bottleneck with Invertible Neural Networks: Getting the Best of Discriminative and Generative Modeling
Jan 20, 2020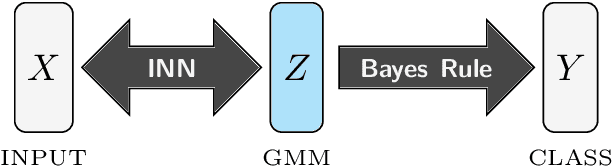

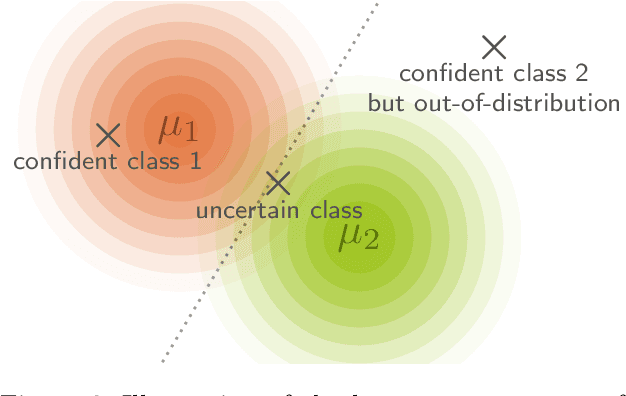
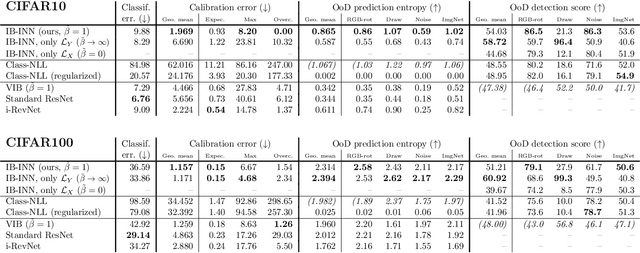
The Information Bottleneck (IB) principle offers a unified approach to many learning and prediction problems. Although optimal in an information-theoretic sense, practical applications of IB are hampered by a lack of accurate high-dimensional estimators of mutual information, its main constituent. We propose to combine IB with invertible neural networks (INNs), which for the first time allows exact calculation of the required mutual information. Applied to classification, our proposed method results in a generative classifier we call IB-INN. It accurately models the class conditional likelihoods, generalizes well to unseen data and reliably recognizes out-of-distribution examples. In contrast to existing generative classifiers, these advantages incur only minor reductions in classification accuracy in comparison to corresponding discriminative methods such as feed-forward networks. Furthermore, we provide insight into why IB-INNs are superior to other generative architectures and training procedures and show experimentally that our method outperforms alternative models of comparable complexity.
Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift
Sep 19, 2019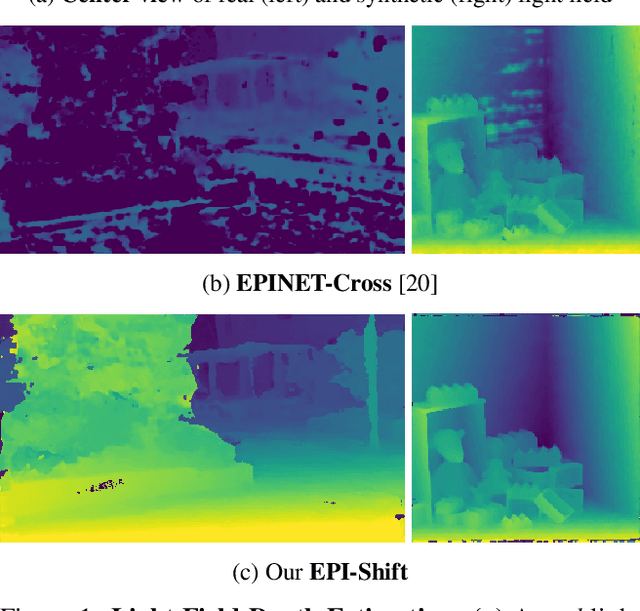


We propose a method for depth estimation from light field data, based on a fully convolutional neural network architecture. Our goal is to design a pipeline which achieves highly accurate results for small- and wide-baseline light fields. Since light field training data is scarce, all learning-based approaches use a small receptive field and operate on small disparity ranges. In order to work with wide-baseline light fields, we introduce the idea of EPI-Shift: To virtually shift the light field stack which enables to retain a small receptive field, independent of the disparity range. In this way, our approach "learns to think outside the box of the receptive field". Our network performs joint classification of integer disparities and regression of disparity-offsets. A U-Net component provides excellent long-range smoothing. EPI-Shift considerably outperforms the state-of-the-art learning-based approaches and is on par with hand-crafted methods. We demonstrate this on a publicly available, synthetic, small-baseline benchmark and on large-baseline real-world recordings.
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

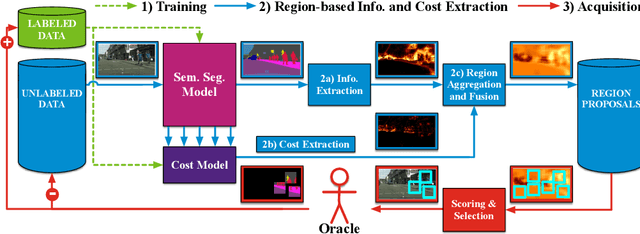
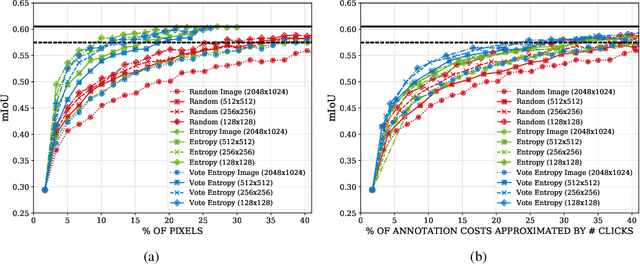
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.