 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Keyword Spotting through long-range interactions with Temporal Lambda Networks
Apr 16, 2021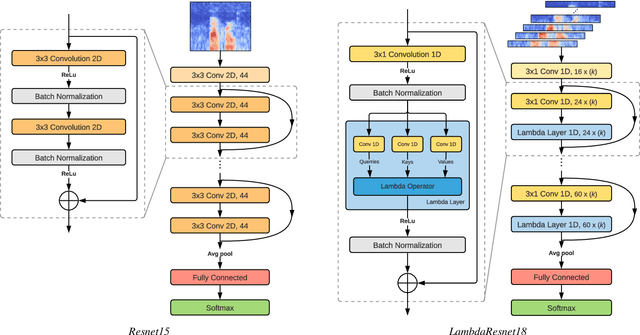
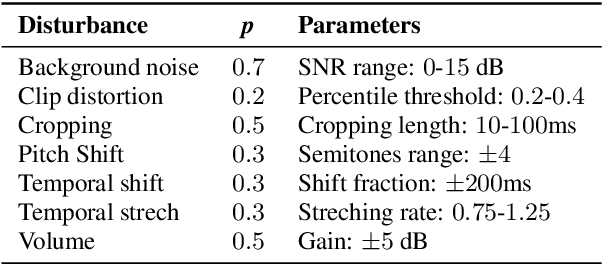
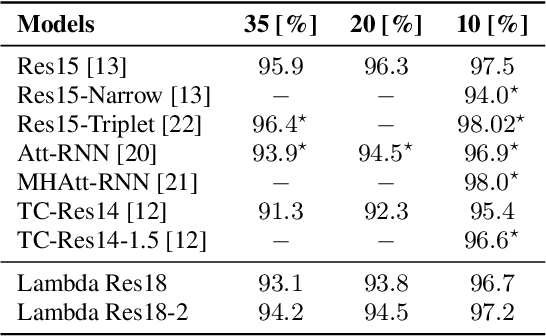
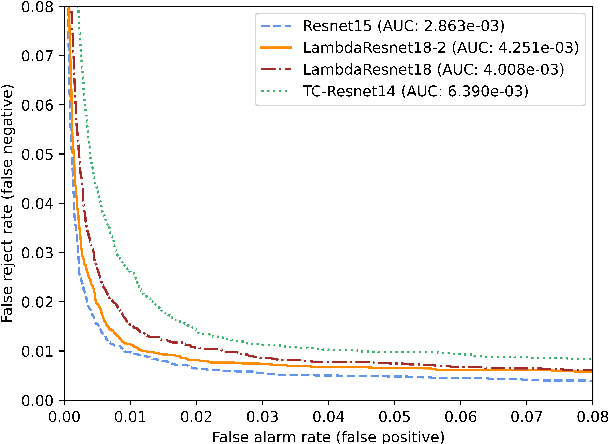
Recent models based on attention mechanisms have shown unprecedented performance in the speech recognition domain. These are computational expensive and unnecessarily complex for the keyword spotting task where its main usage is in small-footprint devices. This work explores the application of the Lambda networks, a framework for capturing long-range interactions, within this spotting task. The proposed architecture is inspired by current state-of-the-art models for keyword spotting built on residual connections. Our main contribution consists on swapping the residual blocks by temporal Lambda layers thus bypassing the expensive computation of attention maps, largely reducing the model complexity. Furthermore, the proposed Lambda network is built upon uni-dimensional convolutions which also dramatically decreases the number of floating point operations performed along the inference stage. This architecture does not only reach state-of-the-art accuracies on the Google Speech Commands dataset, but it is 85% and 65% lighter than its multi headed attention (MHAtt-RNN) and residual convolutional (Res15) counterparts, while being up to 100x faster than them. To the best of our knowledge, this is the first attempt to examine the Lambda framework within the speech domain and therefore, we unravel further research and development of future speech interfaces based on this architecture.
Transcription-Enriched Joint Embeddings for Spoken Descriptions of Images and Videos
Jun 01, 2020
In this work, we propose an effective approach for training unique embedding representations by combining three simultaneous modalities: image and spoken and textual narratives. The proposed methodology departs from a baseline system that spawns a embedding space trained with only spoken narratives and image cues. Our experiments on the EPIC-Kitchen and Places Audio Caption datasets show that introducing the human-generated textual transcriptions of the spoken narratives helps to the training procedure yielding to get better embedding representations. The triad speech, image and words allows for a better estimate of the point embedding and show an improving of the performance within tasks like image and speech retrieval, even when text third modality, text, is not present in the task.
Unsupervised Representation Learning by Discovering Reliable Image Relations
Nov 18, 2019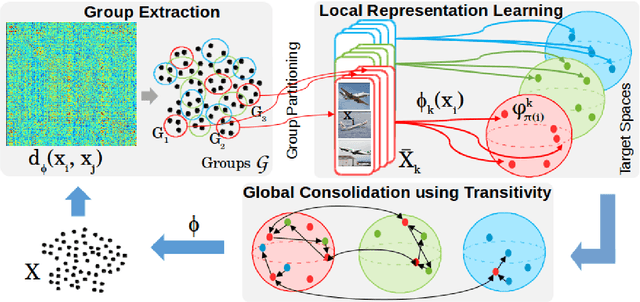
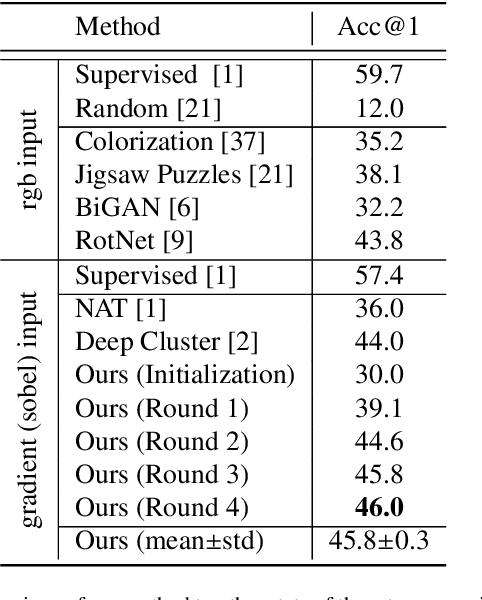
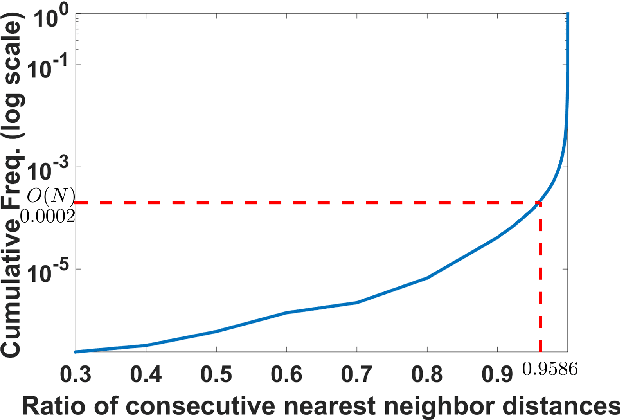
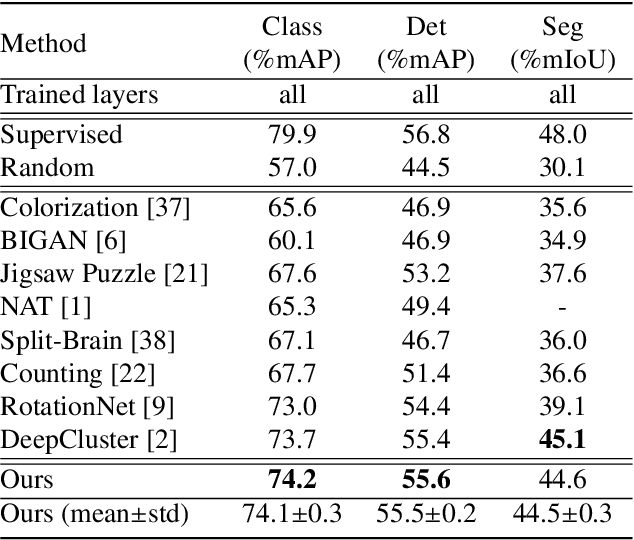
Learning robust representations that allow to reliably establish relations between images is of paramount importance for virtually all of computer vision. Annotating the quadratic number of pairwise relations between training images is simply not feasible, while unsupervised inference is prone to noise, thus leaving the vast majority of these relations to be unreliable. To nevertheless find those relations which can be reliably utilized for learning, we follow a divide-and-conquer strategy: We find reliable similarities by extracting compact groups of images and reliable dissimilarities by partitioning these groups into subsets, converting the complicated overall problem into few reliable local subproblems. For each of the subsets we obtain a representation by learning a mapping to a target feature space so that their reliable relations are kept. Transitivity relations between the subsets are then exploited to consolidate the local solutions into a concerted global representation. While iterating between grouping, partitioning, and learning, we can successively use more and more reliable relations which, in turn, improves our image representation. In experiments, our approach shows state-of-the-art performance on unsupervised classification on ImageNet with 46.0% and competes favorably on different transfer learning tasks on PASCAL VOC.
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

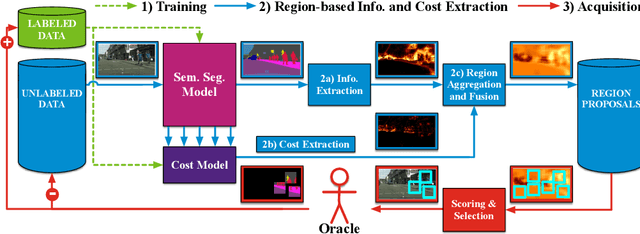
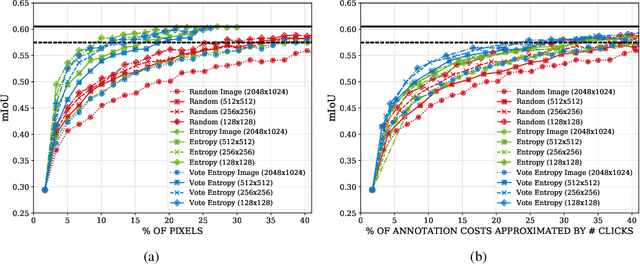
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.
Road Detection via On--line Label Transfer
Dec 10, 2014
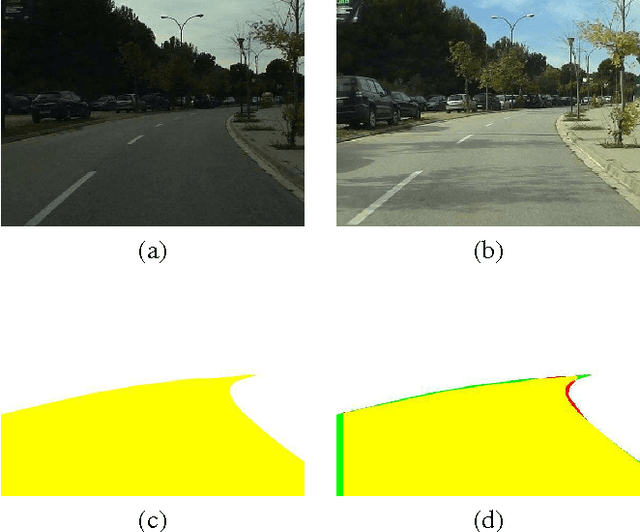
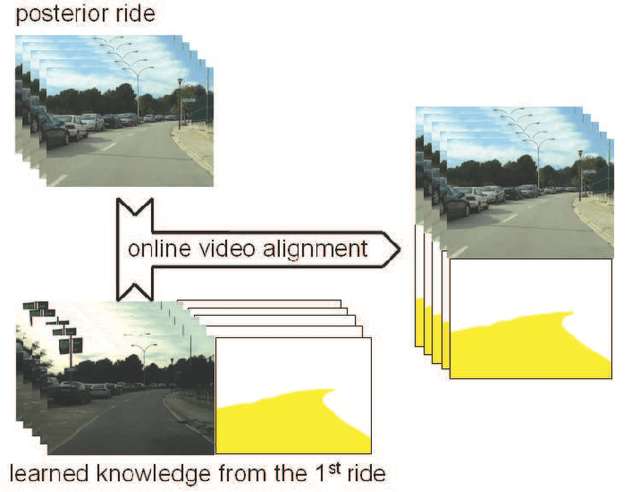

Vision-based road detection is an essential functionality for supporting advanced driver assistance systems (ADAS) such as road following and vehicle and pedestrian detection. The major challenges of road detection are dealing with shadows and lighting variations and the presence of other objects in the scene. Current road detection algorithms characterize road areas at pixel level and group pixels accordingly. However, these algorithms fail in presence of strong shadows and lighting variations. Therefore, we propose a road detection algorithm based on video alignment. The key idea of the algorithm is to exploit the similarities occurred when a vehicle follows the same trajectory more than once. In this way, road areas are learned in a first ride and then, this road knowledge is used to infer areas depicting drivable road surfaces in subsequent rides. Two different experiments are conducted to validate the proposal on different video sequences taken at different scenarios and different daytime. The former aims to perform on-line road detection. The latter aims to perform off-line road detection and is applied to automatically generate the ground-truth necessary to validate road detection algorithms. Qualitative and quantitative evaluations prove that the proposed algorithm is a valid road detection approach.