 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Learning of Scene Geometry from Poses for Global Localization
Dec 04, 2023Global visual localization estimates the absolute pose of a camera using a single image, in a previously mapped area. Obtaining the pose from a single image enables many robotics and augmented/virtual reality applications. Inspired by latest advances in deep learning, many existing approaches directly learn and regress 6 DoF pose from an input image. However, these methods do not fully utilize the underlying scene geometry for pose regression. The challenge in monocular relocalization is the minimal availability of supervised training data, which is just the corresponding 6 DoF poses of the images. In this paper, we propose to utilize these minimal available labels (.i.e, poses) to learn the underlying 3D geometry of the scene and use the geometry to estimate the 6 DoF camera pose. We present a learning method that uses these pose labels and rigid alignment to learn two 3D geometric representations (\textit{X, Y, Z coordinates}) of the scene, one in camera coordinate frame and the other in global coordinate frame. Given a single image, it estimates these two 3D scene representations, which are then aligned to estimate a pose that matches the pose label. This formulation allows for the active inclusion of additional learning constraints to minimize 3D alignment errors between the two 3D scene representations, and 2D re-projection errors between the 3D global scene representation and 2D image pixels, resulting in improved localization accuracy. During inference, our model estimates the 3D scene geometry in camera and global frames and aligns them rigidly to obtain pose in real-time. We evaluate our work on three common visual localization datasets, conduct ablation studies, and show that our method exceeds state-of-the-art regression methods' pose accuracy on all datasets.
Weakly Supervised Multi-Object Tracking and Segmentation
Jan 03, 2021
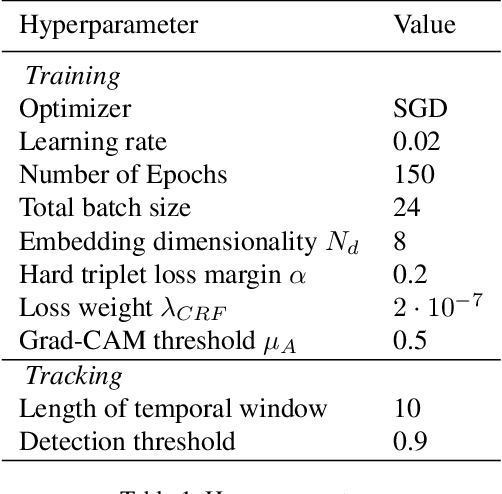
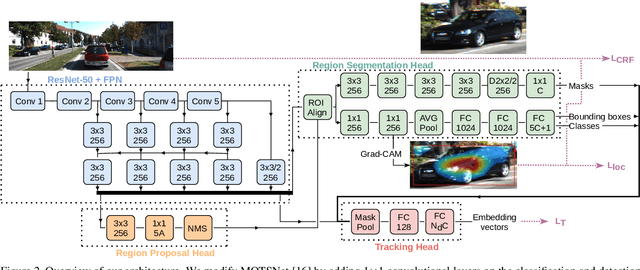
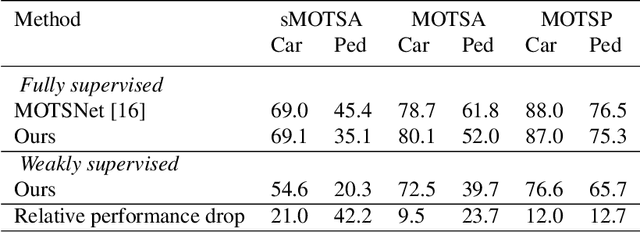
We introduce the problem of weakly supervised Multi-Object Tracking and Segmentation, i.e. joint weakly supervised instance segmentation and multi-object tracking, in which we do not provide any kind of mask annotation. To address it, we design a novel synergistic training strategy by taking advantage of multi-task learning, i.e. classification and tracking tasks guide the training of the unsupervised instance segmentation. For that purpose, we extract weak foreground localization information, provided by Grad-CAM heatmaps, to generate a partial ground truth to learn from. Additionally, RGB image level information is employed to refine the mask prediction at the edges of the objects. We evaluate our method on KITTI MOTS, the most representative benchmark for this task, reducing the performance gap on the MOTSP metric between the fully supervised and weakly supervised approach to just 12% and 12.7% for cars and pedestrians, respectively.
* Accepted at Autonomous Vehicle Vision WACV 2021 Workshop
Monitoring War Destruction from Space: A Machine Learning Approach
Oct 14, 2020
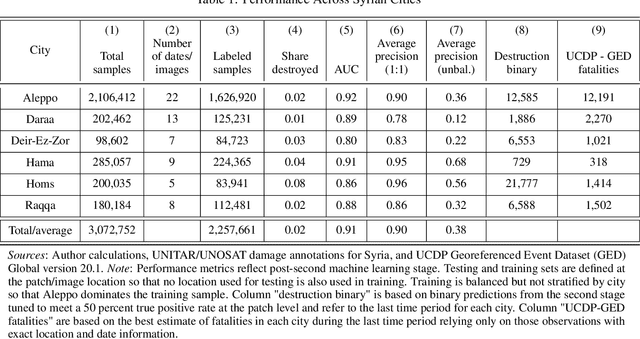
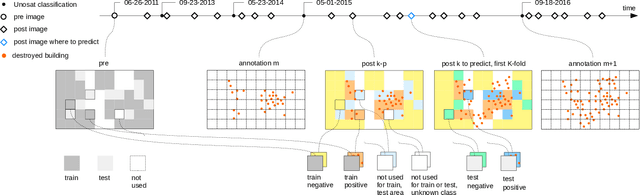
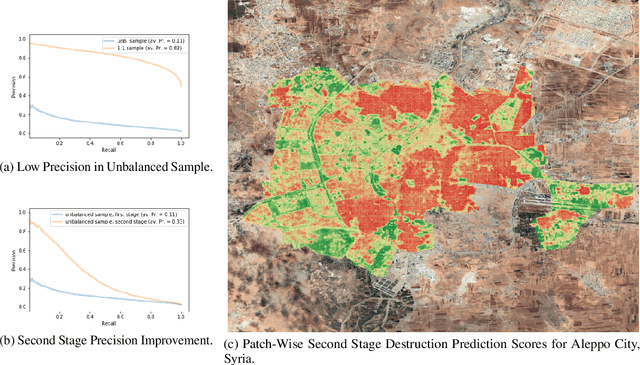
Existing data on building destruction in conflict zones rely on eyewitness reports or manual detection, which makes it generally scarce, incomplete and potentially biased. This lack of reliable data imposes severe limitations for media reporting, humanitarian relief efforts, human rights monitoring, reconstruction initiatives, and academic studies of violent conflict. This article introduces an automated method of measuring destruction in high-resolution satellite images using deep learning techniques combined with data augmentation to expand training samples. We apply this method to the Syrian civil war and reconstruct the evolution of damage in major cities across the country. The approach allows generating destruction data with unprecedented scope, resolution, and frequency - only limited by the available satellite imagery - which can alleviate data limitations decisively.
Learning Multi-Object Tracking and Segmentation from Automatic Annotations
Dec 04, 2019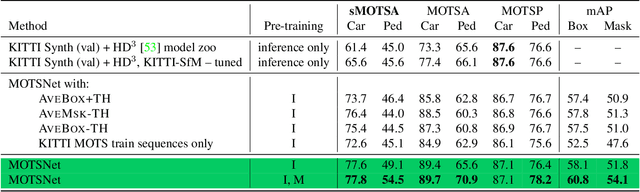
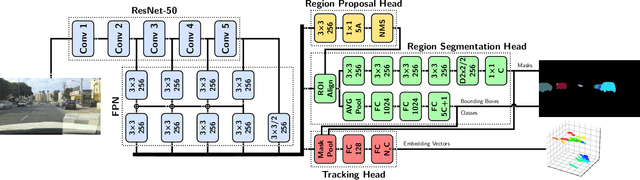
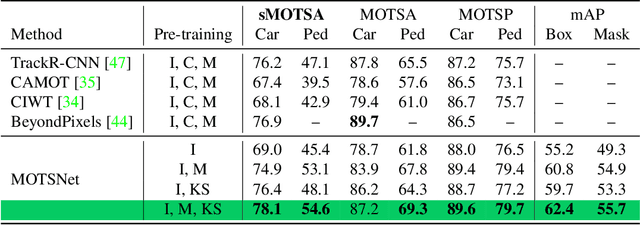
In this work we contribute a novel pipeline to automatically generate training data, and to improve over state-of-the-art multi-object tracking and segmentation (MOTS) methods. Our proposed tracklet mining algorithm turns raw street-level videos into high-fidelity MOTS training data, is scalable and overcomes the need of expensive and time-consuming manual annotation approaches. We leverage state-of-the-art instance segmentation results in combination with optical flow obtained from models also trained on automatically harvested training data. Our second major contribution is MOTSNet - a deep learning, tracking-by-detection architecture for MOTS - deploying a novel mask-pooling layer for improved object association over time. Training MOTSNet with our automatically extracted data leads to significantly improved sMOTSA scores on the novel KITTI MOTS dataset (+1.9%/+7.5% on cars/pedestrians). Even without learning from a single, manually annotated MOTS training example we still improve over prior state-of-the-art, confirming the compelling properties of our pipeline. On the MOTSChallenge dataset we improve by +4.1%, further confirming the efficacy of our proposed MOTSNet.
Metric Learning for Novelty and Anomaly Detection
Aug 16, 2018
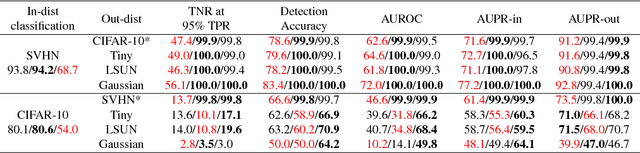

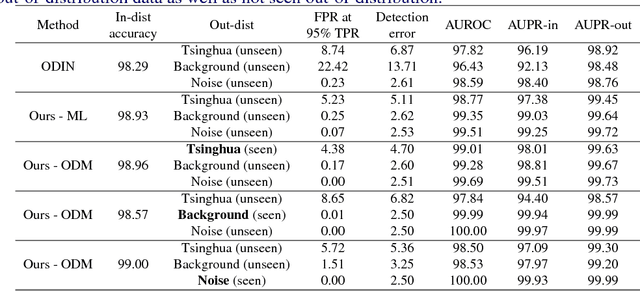
When neural networks process images which do not resemble the distribution seen during training, so called out-of-distribution images, they often make wrong predictions, and do so too confidently. The capability to detect out-of-distribution images is therefore crucial for many real-world applications. We divide out-of-distribution detection between novelty detection ---images of classes which are not in the training set but are related to those---, and anomaly detection ---images with classes which are unrelated to the training set. By related we mean they contain the same type of objects, like digits in MNIST and SVHN. Most existing work has focused on anomaly detection, and has addressed this problem considering networks trained with the cross-entropy loss. Differently from them, we propose to use metric learning which does not have the drawback of the softmax layer (inherent to cross-entropy methods), which forces the network to divide its prediction power over the learned classes. We perform extensive experiments and evaluate both novelty and anomaly detection, even in a relevant application such as traffic sign recognition, obtaining comparable or better results than previous works.
Road Detection via On--line Label Transfer
Dec 10, 2014
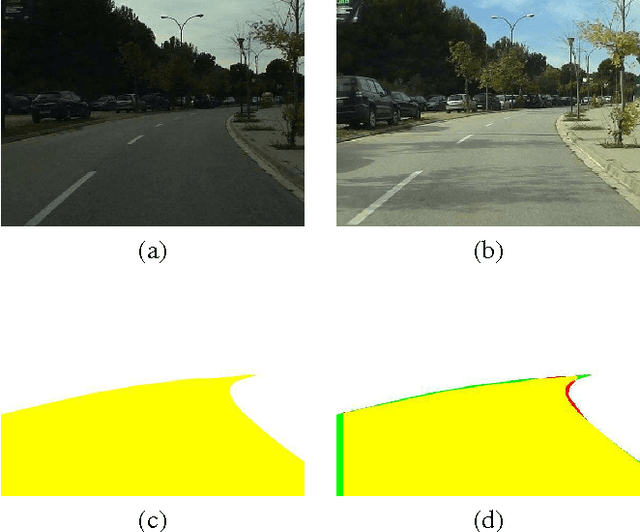
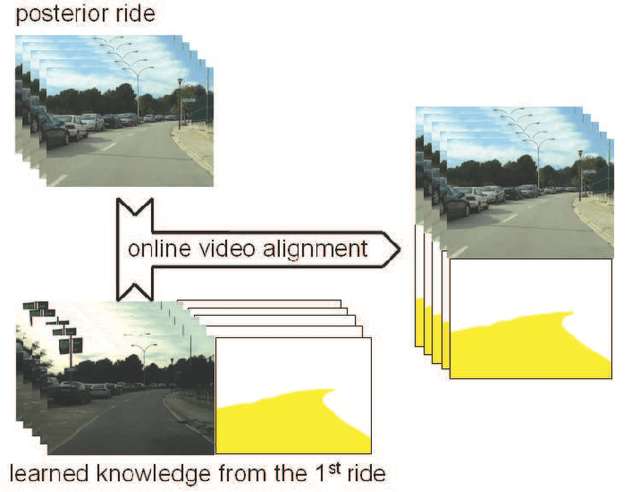

Vision-based road detection is an essential functionality for supporting advanced driver assistance systems (ADAS) such as road following and vehicle and pedestrian detection. The major challenges of road detection are dealing with shadows and lighting variations and the presence of other objects in the scene. Current road detection algorithms characterize road areas at pixel level and group pixels accordingly. However, these algorithms fail in presence of strong shadows and lighting variations. Therefore, we propose a road detection algorithm based on video alignment. The key idea of the algorithm is to exploit the similarities occurred when a vehicle follows the same trajectory more than once. In this way, road areas are learned in a first ride and then, this road knowledge is used to infer areas depicting drivable road surfaces in subsequent rides. Two different experiments are conducted to validate the proposal on different video sequences taken at different scenarios and different daytime. The former aims to perform on-line road detection. The latter aims to perform off-line road detection and is applied to automatically generate the ground-truth necessary to validate road detection algorithms. Qualitative and quantitative evaluations prove that the proposed algorithm is a valid road detection approach.