 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Learning of Scene Geometry from Poses for Global Localization
Dec 04, 2023Global visual localization estimates the absolute pose of a camera using a single image, in a previously mapped area. Obtaining the pose from a single image enables many robotics and augmented/virtual reality applications. Inspired by latest advances in deep learning, many existing approaches directly learn and regress 6 DoF pose from an input image. However, these methods do not fully utilize the underlying scene geometry for pose regression. The challenge in monocular relocalization is the minimal availability of supervised training data, which is just the corresponding 6 DoF poses of the images. In this paper, we propose to utilize these minimal available labels (.i.e, poses) to learn the underlying 3D geometry of the scene and use the geometry to estimate the 6 DoF camera pose. We present a learning method that uses these pose labels and rigid alignment to learn two 3D geometric representations (\textit{X, Y, Z coordinates}) of the scene, one in camera coordinate frame and the other in global coordinate frame. Given a single image, it estimates these two 3D scene representations, which are then aligned to estimate a pose that matches the pose label. This formulation allows for the active inclusion of additional learning constraints to minimize 3D alignment errors between the two 3D scene representations, and 2D re-projection errors between the 3D global scene representation and 2D image pixels, resulting in improved localization accuracy. During inference, our model estimates the 3D scene geometry in camera and global frames and aligns them rigidly to obtain pose in real-time. We evaluate our work on three common visual localization datasets, conduct ablation studies, and show that our method exceeds state-of-the-art regression methods' pose accuracy on all datasets.
Global Localization: Utilizing Relative Spatio-Temporal Geometric Constraints from Adjacent and Distant Cameras
Dec 01, 2023



Re-localizing a camera from a single image in a previously mapped area is vital for many computer vision applications in robotics and augmented/virtual reality. In this work, we address the problem of estimating the 6 DoF camera pose relative to a global frame from a single image. We propose to leverage a novel network of relative spatial and temporal geometric constraints to guide the training of a Deep Network for localization. We employ simultaneously spatial and temporal relative pose constraints that are obtained not only from adjacent camera frames but also from camera frames that are distant in the spatio-temporal space of the scene. We show that our method, through these constraints, is capable of learning to localize when little or very sparse ground-truth 3D coordinates are available. In our experiments, this is less than 1% of available ground-truth data. We evaluate our method on 3 common visual localization datasets and show that it outperforms other direct pose estimation methods.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
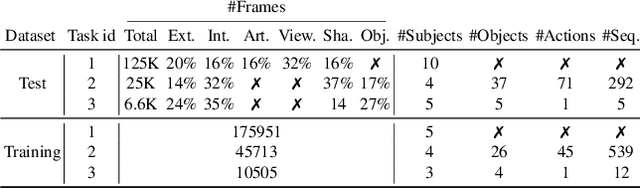
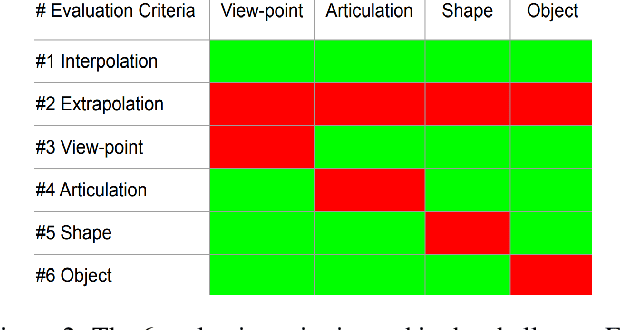
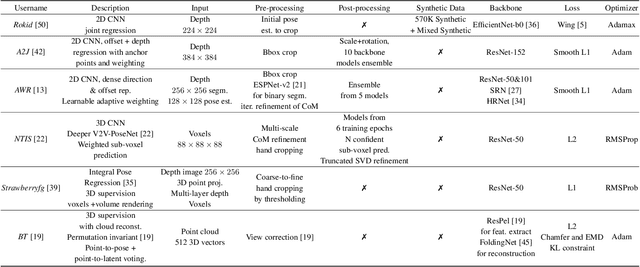
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Point-to-Pose Voting based Hand Pose Estimation using Residual Permutation Equivariant Layer
Dec 05, 2018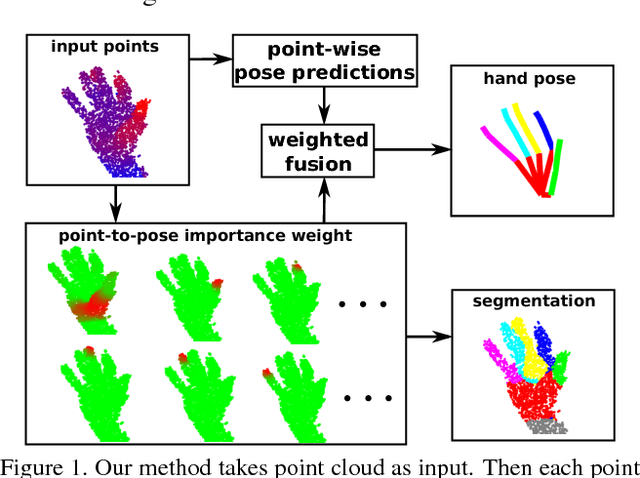
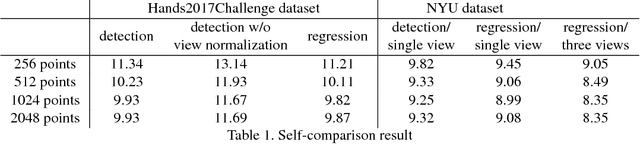
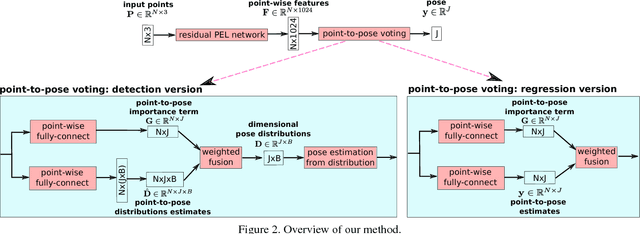
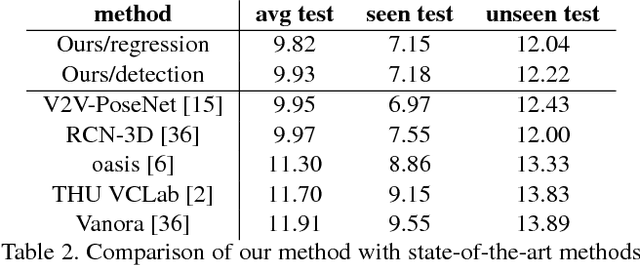
Recently, 3D input data based hand pose estimation methods have shown state-of-the-art performance, because 3D data capture more spatial information than the depth image. Whereas 3D voxel-based methods need a large amount of memory, PointNet based methods need tedious preprocessing steps such as K-nearest neighbour search for each point. In this paper, we present a novel deep learning hand pose estimation method for an unordered point cloud. Our method takes 1024 3D points as input and does not require additional information. We use Permutation Equivariant Layer (PEL) as the basic element, where a residual network version of PEL is proposed for the hand pose estimation task. Furthermore, we propose a voting based scheme to merge information from individual points to the final pose output. In addition to the pose estimation task, the voting-based scheme can also provide point cloud segmentation result without ground-truth for segmentation. We evaluate our method on both NYU dataset and the Hands2017Challenge dataset. Our method outperforms recent state-of-the-art methods, where our pose accuracy is currently the best for the Hands2017Challenge dataset.
Model-based Hand Pose Estimation for Generalized Hand Shape with Appearance Normalization
Jul 02, 2018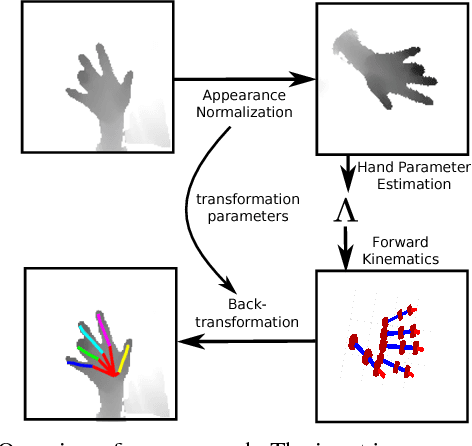

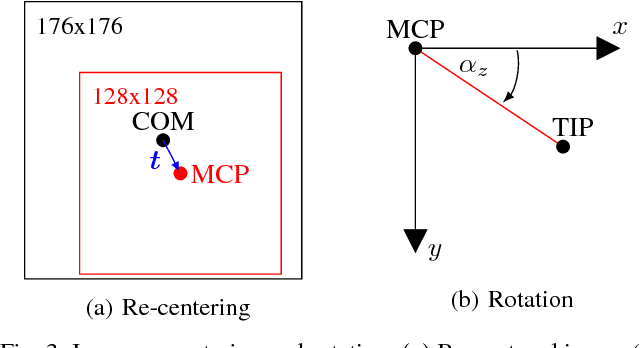
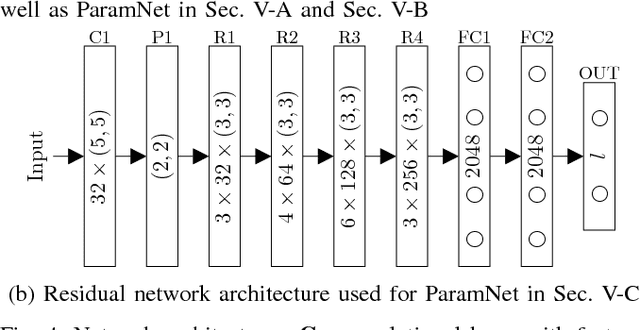
Since the emergence of large annotated datasets, state-of-the-art hand pose estimation methods have been mostly based on discriminative learning. Recently, a hybrid approach has embedded a kinematic layer into the deep learning structure in such a way that the pose estimates obey the physical constraints of human hand kinematics. However, the existing approach relies on a single person's hand shape parameters, which are fixed constants. Therefore, the existing hybrid method has problems to generalize to new, unseen hands. In this work, we extend the kinematic layer to make the hand shape parameters learnable. In this way, the learnt network can generalize towards arbitrary hand shapes. Furthermore, inspired by the idea of Spatial Transformer Networks, we apply a cascade of appearance normalization networks to decrease the variance in the input data. The input images are shifted, rotated, and globally scaled to a similar appearance. The effectiveness and limitations of our proposed approach are extensively evaluated on the Hands 2017 challenge dataset and the NYU dataset.
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
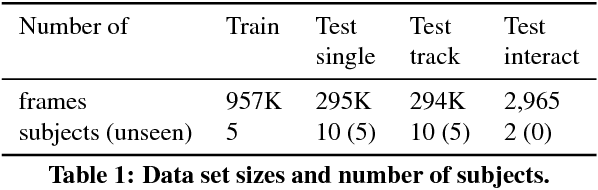
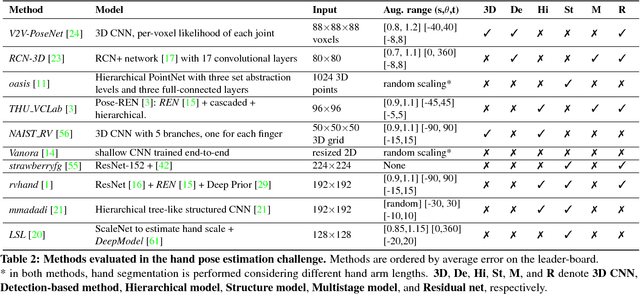
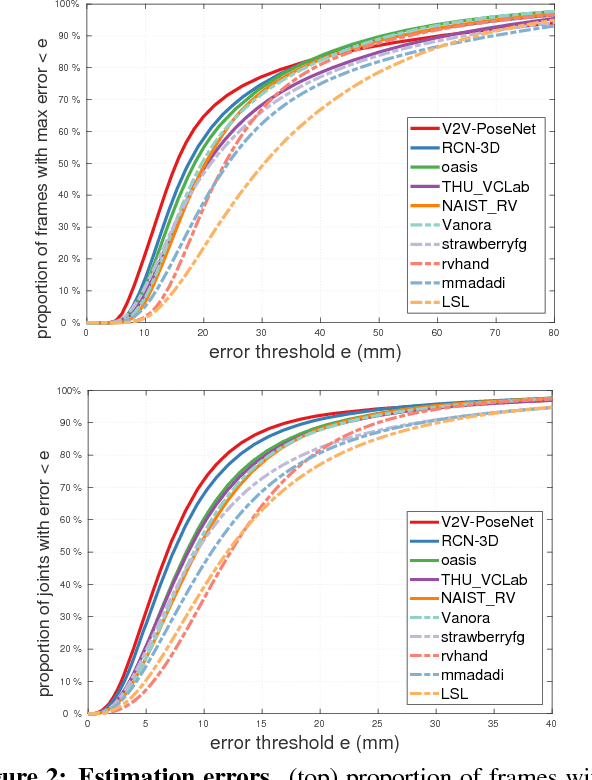
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.