 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchies of Planning and Reinforcement Learning for Robot Navigation
Sep 23, 2021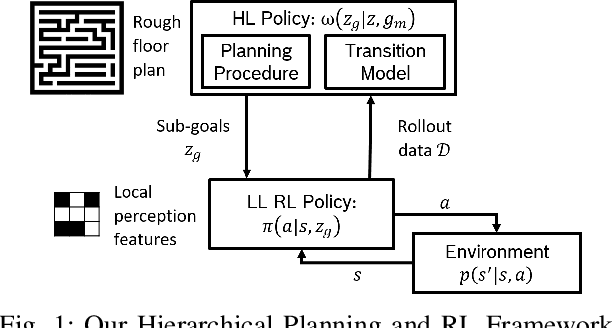
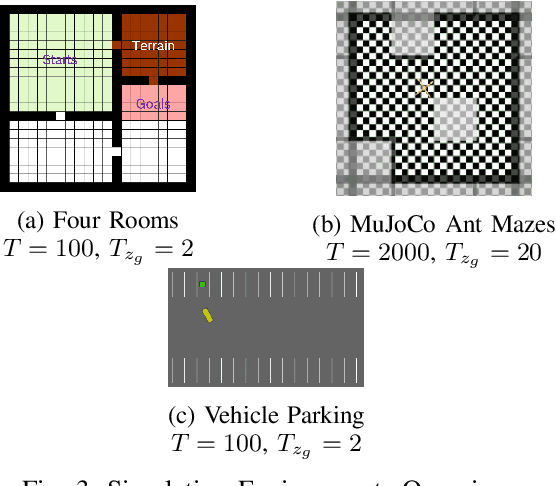
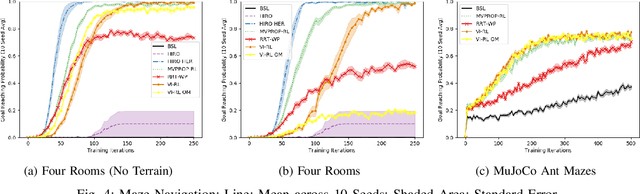
Solving robotic navigation tasks via reinforcement learning (RL) is challenging due to their sparse reward and long decision horizon nature. However, in many navigation tasks, high-level (HL) task representations, like a rough floor plan, are available. Previous work has demonstrated efficient learning by hierarchal approaches consisting of path planning in the HL representation and using sub-goals derived from the plan to guide the RL policy in the source task. However, these approaches usually neglect the complex dynamics and sub-optimal sub-goal-reaching capabilities of the robot during planning. This work overcomes these limitations by proposing a novel hierarchical framework that utilizes a trainable planning policy for the HL representation. Thereby robot capabilities and environment conditions can be learned utilizing collected rollout data. We specifically introduce a planning policy based on value iteration with a learned transition model (VI-RL). In simulated robotic navigation tasks, VI-RL results in consistent strong improvement over vanilla RL, is on par with vanilla hierarchal RL on single layouts but more broadly applicable to multiple layouts, and is on par with trainable HL path planning baselines except for a parking task with difficult non-holonomic dynamics where it shows marked improvements.
Model-based Hand Pose Estimation for Generalized Hand Shape with Appearance Normalization
Jul 02, 2018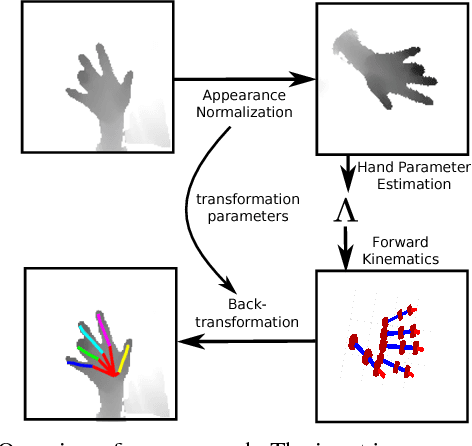

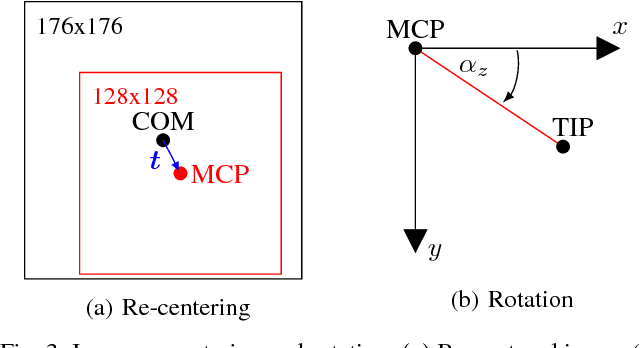
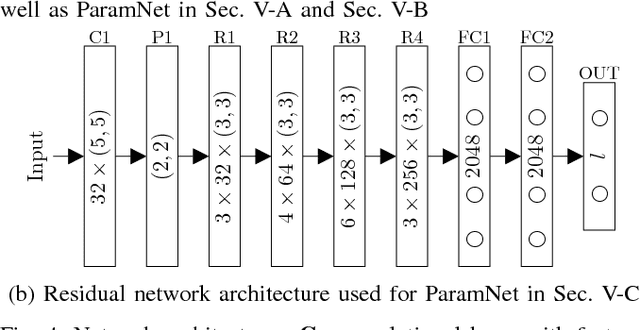
Since the emergence of large annotated datasets, state-of-the-art hand pose estimation methods have been mostly based on discriminative learning. Recently, a hybrid approach has embedded a kinematic layer into the deep learning structure in such a way that the pose estimates obey the physical constraints of human hand kinematics. However, the existing approach relies on a single person's hand shape parameters, which are fixed constants. Therefore, the existing hybrid method has problems to generalize to new, unseen hands. In this work, we extend the kinematic layer to make the hand shape parameters learnable. In this way, the learnt network can generalize towards arbitrary hand shapes. Furthermore, inspired by the idea of Spatial Transformer Networks, we apply a cascade of appearance normalization networks to decrease the variance in the input data. The input images are shifted, rotated, and globally scaled to a similar appearance. The effectiveness and limitations of our proposed approach are extensively evaluated on the Hands 2017 challenge dataset and the NYU dataset.