 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchies of Planning and Reinforcement Learning for Robot Navigation
Sep 23, 2021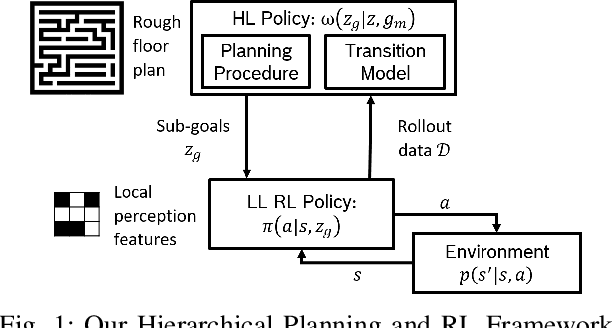
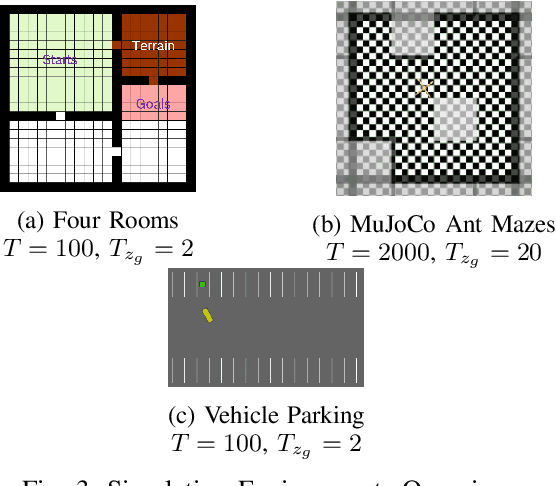
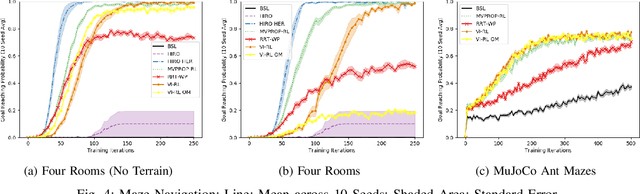
Solving robotic navigation tasks via reinforcement learning (RL) is challenging due to their sparse reward and long decision horizon nature. However, in many navigation tasks, high-level (HL) task representations, like a rough floor plan, are available. Previous work has demonstrated efficient learning by hierarchal approaches consisting of path planning in the HL representation and using sub-goals derived from the plan to guide the RL policy in the source task. However, these approaches usually neglect the complex dynamics and sub-optimal sub-goal-reaching capabilities of the robot during planning. This work overcomes these limitations by proposing a novel hierarchical framework that utilizes a trainable planning policy for the HL representation. Thereby robot capabilities and environment conditions can be learned utilizing collected rollout data. We specifically introduce a planning policy based on value iteration with a learned transition model (VI-RL). In simulated robotic navigation tasks, VI-RL results in consistent strong improvement over vanilla RL, is on par with vanilla hierarchal RL on single layouts but more broadly applicable to multiple layouts, and is on par with trainable HL path planning baselines except for a parking task with difficult non-holonomic dynamics where it shows marked improvements.
Reward (Mis)design for Autonomous Driving
Apr 28, 2021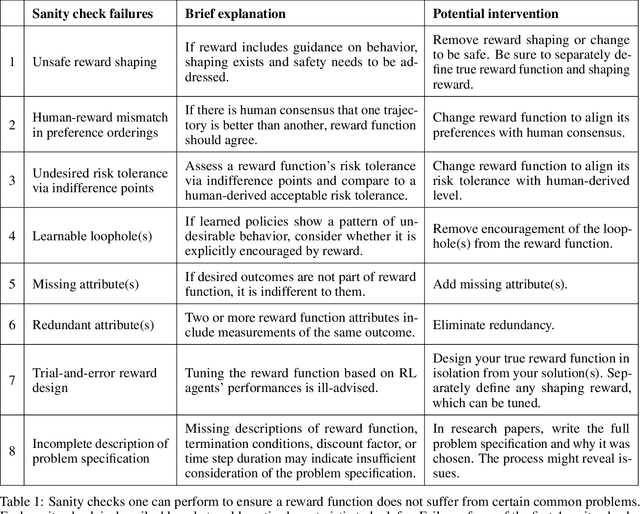
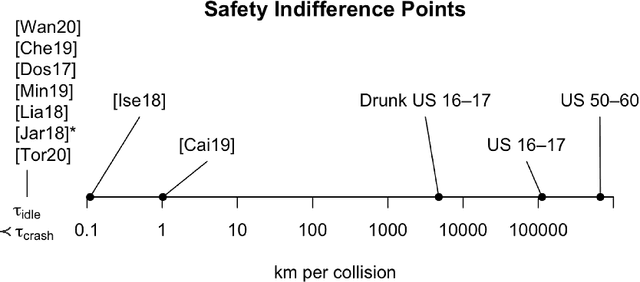
This paper considers the problem of reward design for autonomous driving (AD), with insights that are also applicable to the design of cost functions and performance metrics more generally. Herein we develop 8 simple sanity checks for identifying flaws in reward functions. The sanity checks are applied to reward functions from past work on reinforcement learning (RL) for autonomous driving, revealing near-universal flaws in reward design for AD that might also exist pervasively across reward design for other tasks. Lastly, we explore promising directions that may help future researchers design reward functions for AD.
Inverse Reinforcement Learning with Simultaneous Estimation of Rewards and Dynamics
Apr 13, 2016
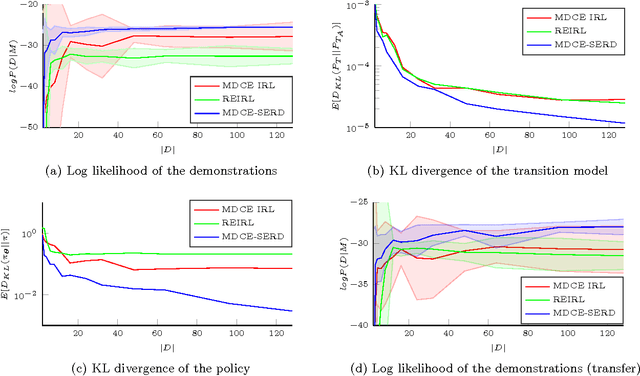
Inverse Reinforcement Learning (IRL) describes the problem of learning an unknown reward function of a Markov Decision Process (MDP) from observed behavior of an agent. Since the agent's behavior originates in its policy and MDP policies depend on both the stochastic system dynamics as well as the reward function, the solution of the inverse problem is significantly influenced by both. Current IRL approaches assume that if the transition model is unknown, additional samples from the system's dynamics are accessible, or the observed behavior provides enough samples of the system's dynamics to solve the inverse problem accurately. These assumptions are often not satisfied. To overcome this, we present a gradient-based IRL approach that simultaneously estimates the system's dynamics. By solving the combined optimization problem, our approach takes into account the bias of the demonstrations, which stems from the generating policy. The evaluation on a synthetic MDP and a transfer learning task shows improvements regarding the sample efficiency as well as the accuracy of the estimated reward functions and transition models.