 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and Fine-Grained Visual Explanations for Convolutional Neural Networks
Aug 07, 2019
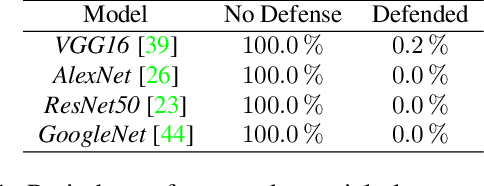

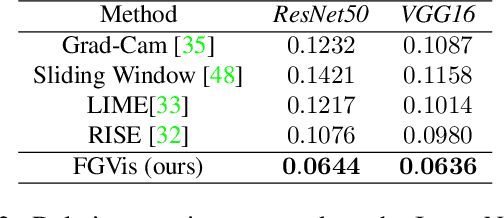
To verify and validate networks, it is essential to gain insight into their decisions, limitations as well as possible shortcomings of training data. In this work, we propose a post-hoc, optimization based visual explanation method, which highlights the evidence in the input image for a specific prediction. Our approach is based on a novel technique to defend against adversarial evidence (i.e. faulty evidence due to artefacts) by filtering gradients during optimization. The defense does not depend on human-tuned parameters. It enables explanations which are both fine-grained and preserve the characteristics of images, such as edges and colors. The explanations are interpretable, suited for visualizing detailed evidence and can be tested as they are valid model inputs. We qualitatively and quantitatively evaluate our approach on a multitude of models and datasets.
Inverse Reinforcement Learning with Simultaneous Estimation of Rewards and Dynamics
Apr 13, 2016
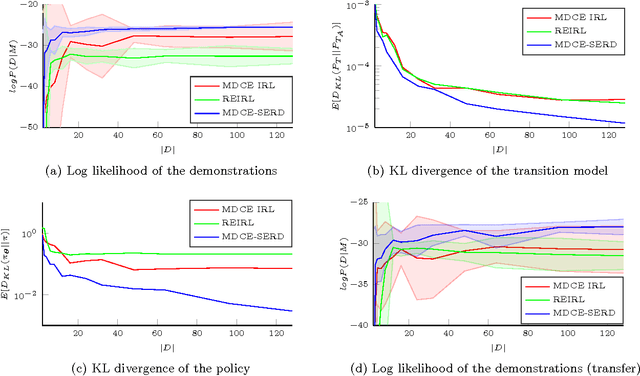
Inverse Reinforcement Learning (IRL) describes the problem of learning an unknown reward function of a Markov Decision Process (MDP) from observed behavior of an agent. Since the agent's behavior originates in its policy and MDP policies depend on both the stochastic system dynamics as well as the reward function, the solution of the inverse problem is significantly influenced by both. Current IRL approaches assume that if the transition model is unknown, additional samples from the system's dynamics are accessible, or the observed behavior provides enough samples of the system's dynamics to solve the inverse problem accurately. These assumptions are often not satisfied. To overcome this, we present a gradient-based IRL approach that simultaneously estimates the system's dynamics. By solving the combined optimization problem, our approach takes into account the bias of the demonstrations, which stems from the generating policy. The evaluation on a synthetic MDP and a transfer learning task shows improvements regarding the sample efficiency as well as the accuracy of the estimated reward functions and transition models.