 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Behavior Prediction for Automated Driving: Requirements, Metrics, and Relevant Features
Dec 15, 2020
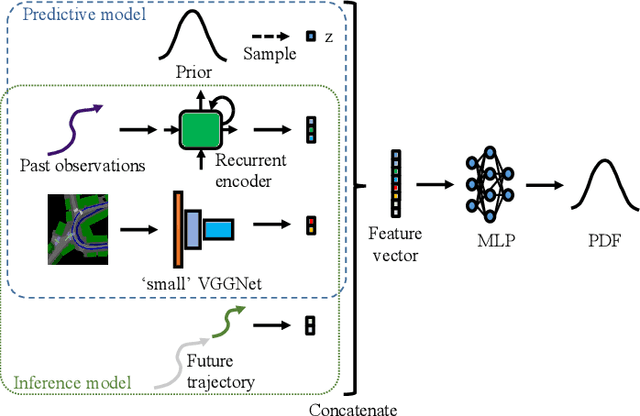
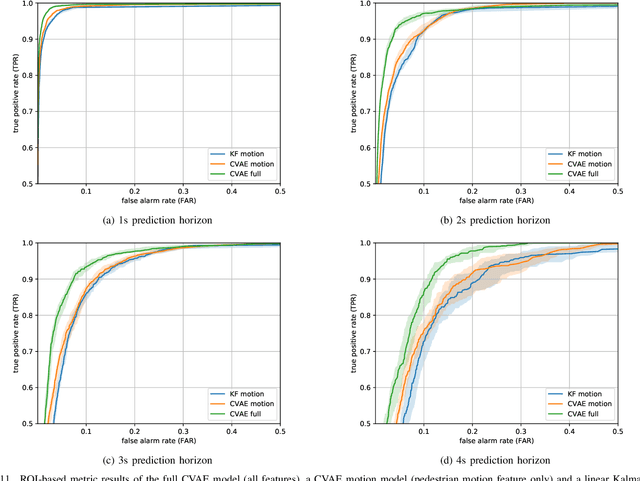
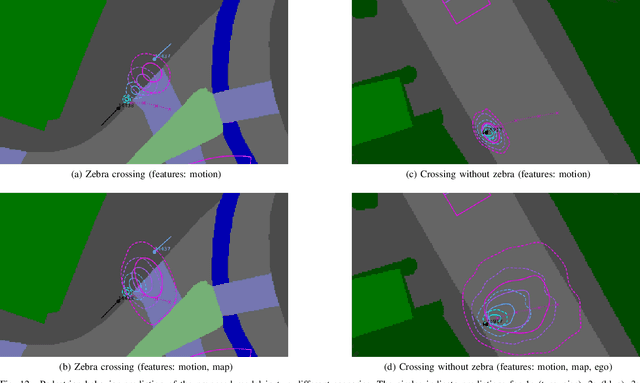
Automated vehicles require a comprehensive understanding of traffic situations to ensure safe and comfortable driving. In this context, the prediction of pedestrians is particularly challenging as pedestrian behavior can be influenced by multiple factors. In this paper, we thoroughly analyze the requirements on pedestrian behavior prediction for automated driving via a system-level approach: to this end we investigate real-world pedestrian-vehicle interactions with human drivers. Based on human driving behavior we then derive appropriate reaction patterns of an automated vehicle. Finally, requirements for the prediction of pedestrians are determined. This also includes a novel metric tailored to measure prediction performance from a system-level perspective. Furthermore, we present a pedestrian prediction model based on a Conditional Variational Auto-Encoder (CVAE) which incorporates multiple contextual cues to achieve accurate long-term prediction. The CVAE shows superior performance over a baseline prediction model, where prediction performance was evaluated on a large-scale data set comprising thousands of real-world pedestrian-vehicle-interactions. Finally, we investigate the impact of different contextual cues on prediction performance via an ablation study whose results can guide future research on the perception of relevant pedestrian attributes.
Wasserstein Adversarial Imitation Learning
Jun 19, 2019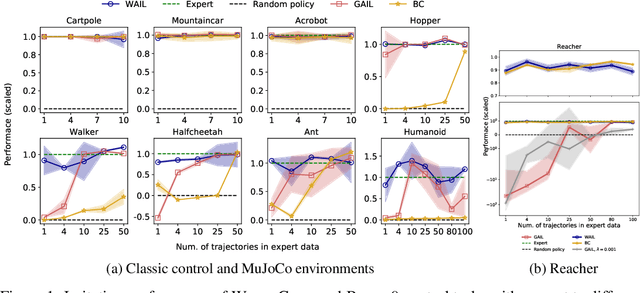
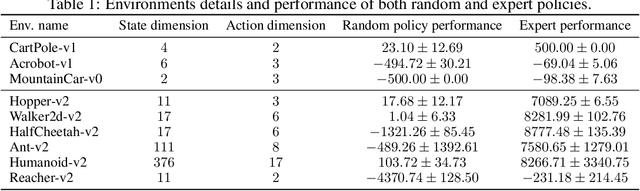
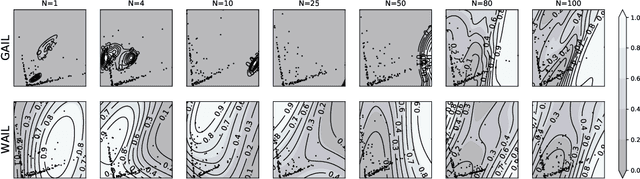
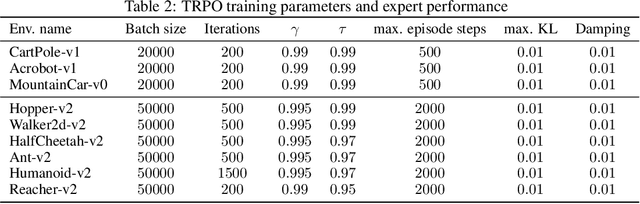
Imitation Learning describes the problem of recovering an expert policy from demonstrations. While inverse reinforcement learning approaches are known to be very sample-efficient in terms of expert demonstrations, they usually require problem-dependent reward functions or a (task-)specific reward-function regularization. In this paper, we show a natural connection between inverse reinforcement learning approaches and Optimal Transport, that enables more general reward functions with desirable properties (e.g., smoothness). Based on our observation, we propose a novel approach called Wasserstein Adversarial Imitation Learning. Our approach considers the Kantorovich potentials as a reward function and further leverages regularized optimal transport to enable large-scale applications. In several robotic experiments, our approach outperforms the baselines in terms of average cumulative rewards and shows a significant improvement in sample-efficiency, by requiring just one expert demonstration.
Human Motion Trajectory Prediction: A Survey
May 15, 2019
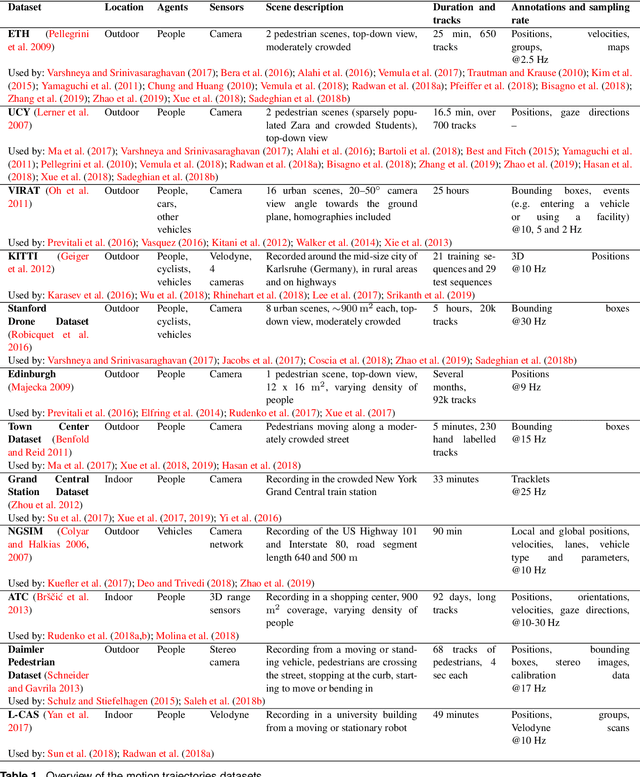
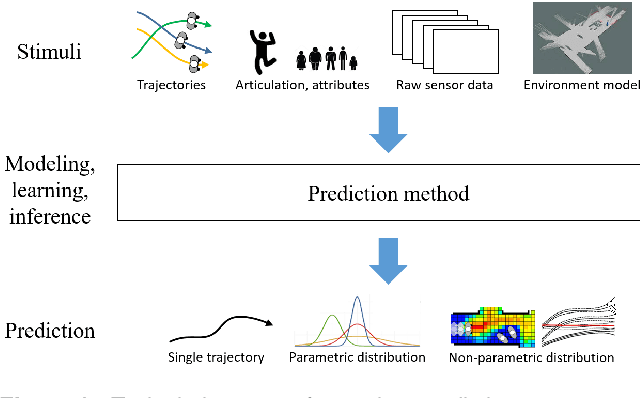
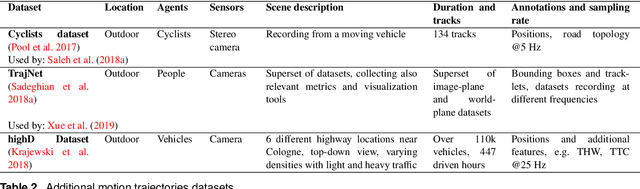
With growing numbers of intelligent systems in human environments, the ability of such systems to perceive, understand and anticipate human behavior becomes increasingly important. Specifically, predicting future positions of dynamic agents and planning considering such predictions are key tasks for self-driving vehicles, service robots and advanced surveillance systems. This paper provides a survey of human motion trajectory prediction. We review, analyze and structure a large selection of work from different communities and propose a taxonomy that categorizes existing approaches based on the motion modeling approach and level of contextual information used. We provide an overview of the existing datasets and performance metrics. We discuss limitations of the state of the art and outline directions for further research.
Functionally Modular and Interpretable Temporal Filtering for Robust Segmentation
Oct 15, 2018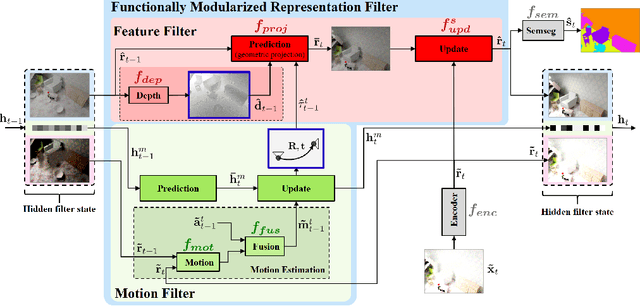


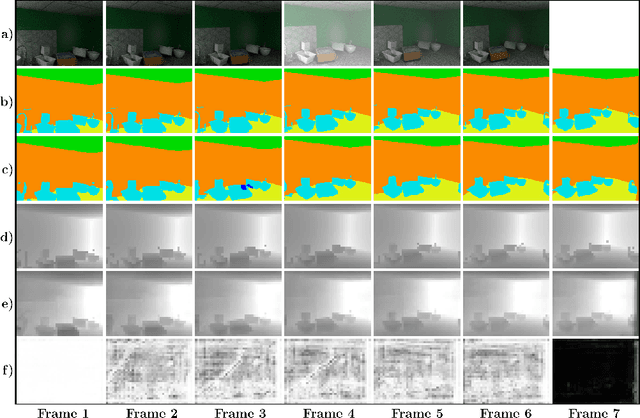
The performance of autonomous systems heavily relies on their ability to generate a robust representation of the environment. Deep neural networks have greatly improved vision-based perception systems but still fail in challenging situations, e.g. sensor outages or heavy weather. These failures are often introduced by data-inherent perturbations, which significantly reduce the information provided to the perception system. We propose a functionally modularized temporal filter, which stabilizes an abstract feature representation of a single-frame segmentation model using information of previous time steps. Our filter module splits the filter task into multiple less complex and more interpretable subtasks. The basic structure of the filter is inspired by a Bayes estimator consisting of a prediction and an update step. To make the prediction more transparent, we implement it using a geometric projection and estimate its parameters. This additionally enables the decomposition of the filter task into static representation filtering and low-dimensional motion filtering. Our model can cope with missing frames and is trainable in an end-to-end fashion. Using photorealistic, synthetic video data, we show the ability of the proposed architecture to overcome data-inherent perturbations. The experiments especially highlight advantages introduced by an interpretable and explicit filter module.
Inverse Reinforcement Learning with Simultaneous Estimation of Rewards and Dynamics
Apr 13, 2016
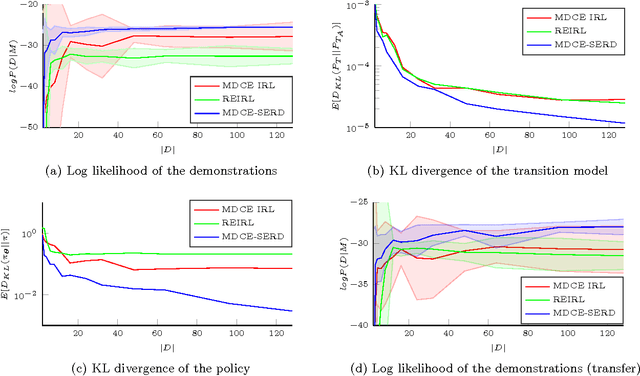
Inverse Reinforcement Learning (IRL) describes the problem of learning an unknown reward function of a Markov Decision Process (MDP) from observed behavior of an agent. Since the agent's behavior originates in its policy and MDP policies depend on both the stochastic system dynamics as well as the reward function, the solution of the inverse problem is significantly influenced by both. Current IRL approaches assume that if the transition model is unknown, additional samples from the system's dynamics are accessible, or the observed behavior provides enough samples of the system's dynamics to solve the inverse problem accurately. These assumptions are often not satisfied. To overcome this, we present a gradient-based IRL approach that simultaneously estimates the system's dynamics. By solving the combined optimization problem, our approach takes into account the bias of the demonstrations, which stems from the generating policy. The evaluation on a synthetic MDP and a transfer learning task shows improvements regarding the sample efficiency as well as the accuracy of the estimated reward functions and transition models.