 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict Mitigation in Shared Environments using Flow-Aware Multi-Agent Path Finding
Mar 13, 2026Deploying multi-robot systems in environments shared with dynamic and uncontrollable agents presents significant challenges, especially for large robot fleets. In such environments, individual robot operations can be delayed due to unforeseen conflicts with uncontrollable agents. While existing research primarily focuses on preserving the completeness of Multi-Agent Path Finding (MAPF) solutions considering delays, there is limited emphasis on utilizing additional environmental information to enhance solution quality in the presence of other dynamic agents. To this end, we propose Flow-Aware Multi-Agent Path Finding (FA-MAPF), a novel framework that integrates learned motion patterns of uncontrollable agents into centralized MAPF algorithms. Our evaluation, conducted on a diverse set of benchmark maps with simulated uncontrollable agents and on a real-world map with recorded human trajectories, demonstrates the effectiveness of FA-MAPF compared to state-of-the-art baselines. The experimental results show that FA-MAPF can consistently reduce conflicts with uncontrollable agents, up to 55%, without compromising task efficiency.
Seeing is Believing (and Predicting): Context-Aware Multi-Human Behavior Prediction with Vision Language Models
Dec 17, 2025Accurately predicting human behaviors is crucial for mobile robots operating in human-populated environments. While prior research primarily focuses on predicting actions in single-human scenarios from an egocentric view, several robotic applications require understanding multiple human behaviors from a third-person perspective. To this end, we present CAMP-VLM (Context-Aware Multi-human behavior Prediction): a Vision Language Model (VLM)-based framework that incorporates contextual features from visual input and spatial awareness from scene graphs to enhance prediction of humans-scene interactions. Due to the lack of suitable datasets for multi-human behavior prediction from an observer view, we perform fine-tuning of CAMP-VLM with synthetic human behavior data generated by a photorealistic simulator, and evaluate the resulting models on both synthetic and real-world sequences to assess their generalization capabilities. Leveraging Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), CAMP-VLM outperforms the best-performing baseline by up to 66.9% in prediction accuracy.
Context-Aware Human Behavior Prediction Using Multimodal Large Language Models: Challenges and Insights
Apr 01, 2025Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
GraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering
Dec 19, 2024



In Embodied Question Answering (EQA), agents must explore and develop a semantic understanding of an unseen environment in order to answer a situated question with confidence. This remains a challenging problem in robotics, due to the difficulties in obtaining useful semantic representations, updating these representations online, and leveraging prior world knowledge for efficient exploration and planning. Aiming to address these limitations, we propose GraphEQA, a novel approach that utilizes real-time 3D metric-semantic scene graphs (3DSGs) and task relevant images as multi-modal memory for grounding Vision-Language Models (VLMs) to perform EQA tasks in unseen environments. We employ a hierarchical planning approach that exploits the hierarchical nature of 3DSGs for structured planning and semantic-guided exploration. Through experiments in simulation on the HM-EQA dataset and in the real world in home and office environments, we demonstrate that our method outperforms key baselines by completing EQA tasks with higher success rates and fewer planning steps.
The Surprising Ineffectiveness of Pre-Trained Visual Representations for Model-Based Reinforcement Learning
Nov 15, 2024
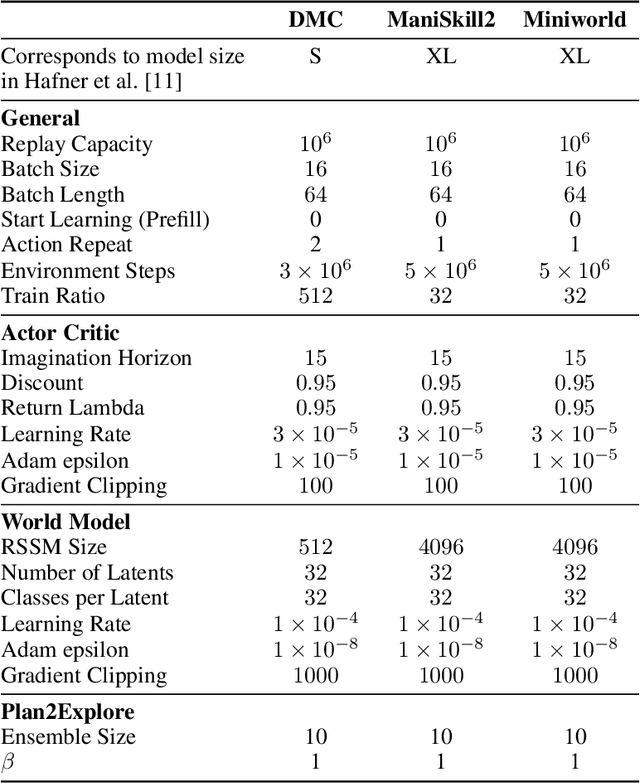

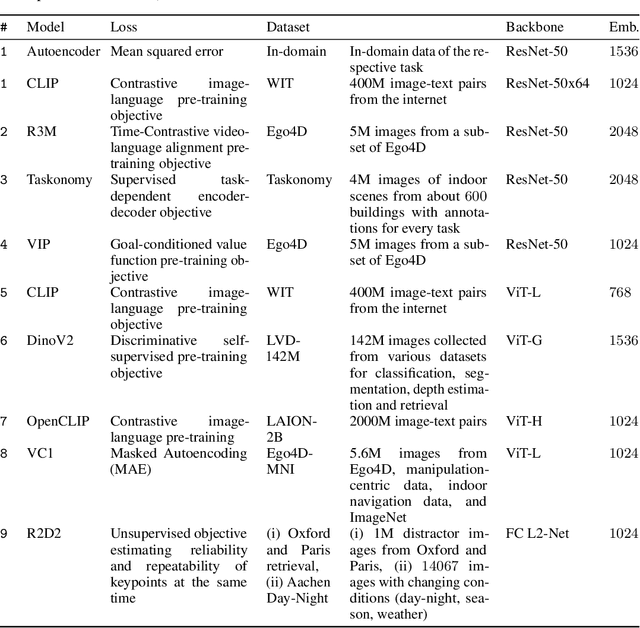
Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.
Fast Online Learning of CLiFF-maps in Changing Environments
Oct 16, 2024
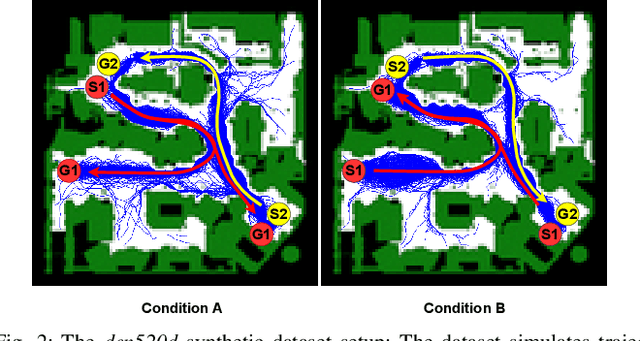
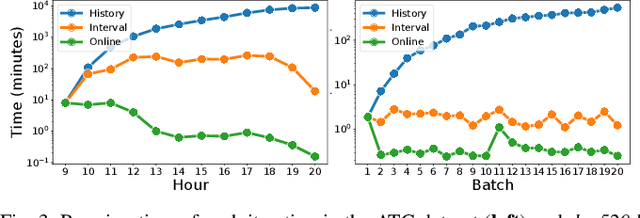

Maps of dynamics are effective representations of motion patterns learned from prior observations, with recent research demonstrating their ability to enhance performance in various downstream tasks such as human-aware robot navigation, long-term human motion prediction, and robot localization. Current advancements have primarily concentrated on methods for learning maps of human flow in environments where the flow is static, i.e., not assumed to change over time. In this paper we propose a method to update the CLiFF-map, one type of map of dynamics, for achieving efficient life-long robot operation. As new observations are collected, our goal is to update a CLiFF-map to effectively and accurately integrate new observations, while retaining relevant historic motion patterns. The proposed online update method maintains a probabilistic representation in each observed location, updating parameters by continuously tracking sufficient statistics. In experiments using both synthetic and real-world datasets, we show that our method is able to maintain accurate representations of human motion dynamics, contributing to high performance flow-compliant planning downstream tasks, while being orders of magnitude faster than the comparable baselines.
Towards Using Fast Embedded Model Predictive Control for Human-Aware Predictive Robot Navigation
May 21, 2024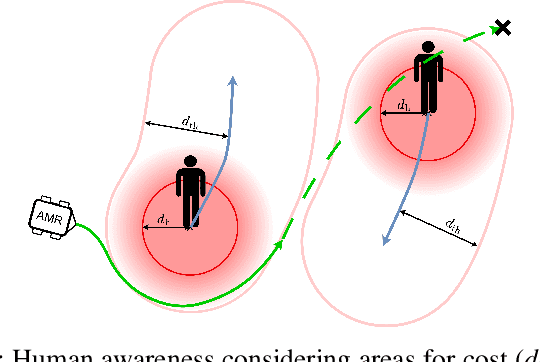
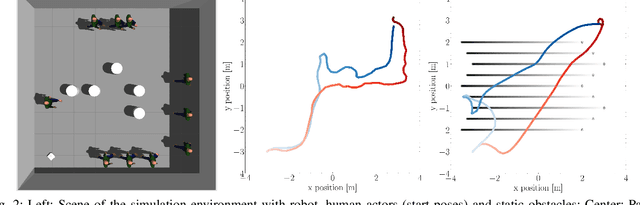

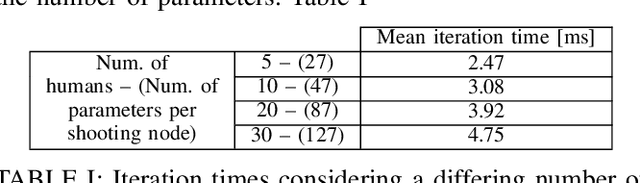
Predictive planning is a key capability for robots to efficiently and safely navigate populated environments. Particularly in densely crowded scenes, with uncertain human motion predictions, predictive path planning, and control can become expensive to compute in real time due to the curse of dimensionality. With the goal of achieving pro-active and legible robot motion in shared environments, in this paper we present HuMAN-MPC, a computationally efficient algorithm for Human Motion Aware Navigation using fast embedded Model Predictive Control. The approach consists of a novel model predictive control (MPC) formulation that leverages a fast state-of-the-art optimization backend based on a sequential quadratic programming real-time iteration scheme while also providing feasibility monitoring. Our experiments, in simulation and on a fully integrated ROS-based platform, show that the approach achieves great scalability with fast computation times without penalizing path quality and efficiency of the resulting avoidance behavior.
Robustness of Decentralised Learning to Nodes and Data Disruption
May 03, 2024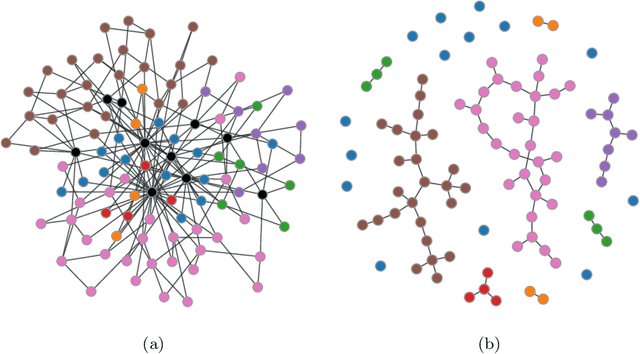

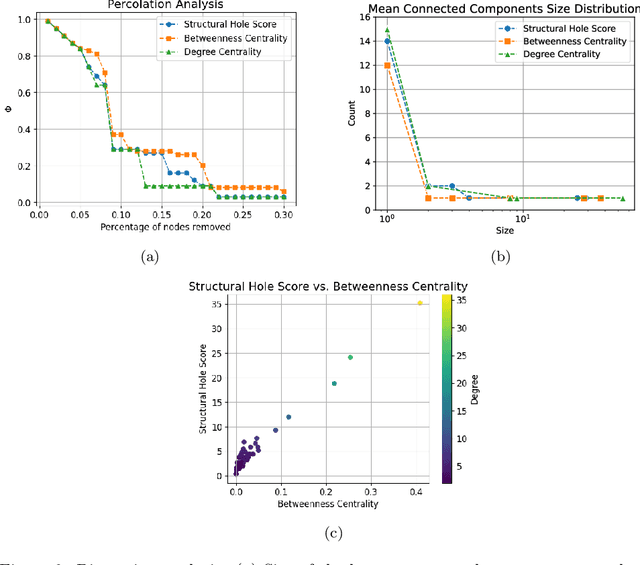

In the vibrant landscape of AI research, decentralised learning is gaining momentum. Decentralised learning allows individual nodes to keep data locally where they are generated and to share knowledge extracted from local data among themselves through an interactive process of collaborative refinement. This paradigm supports scenarios where data cannot leave local nodes due to privacy or sovereignty reasons or real-time constraints imposing proximity of models to locations where inference has to be carried out. The distributed nature of decentralised learning implies significant new research challenges with respect to centralised learning. Among them, in this paper, we focus on robustness issues. Specifically, we study the effect of nodes' disruption on the collective learning process. Assuming a given percentage of "central" nodes disappear from the network, we focus on different cases, characterised by (i) different distributions of data across nodes and (ii) different times when disruption occurs with respect to the start of the collaborative learning task. Through these configurations, we are able to show the non-trivial interplay between the properties of the network connecting nodes, the persistence of knowledge acquired collectively before disruption or lack thereof, and the effect of data availability pre- and post-disruption. Our results show that decentralised learning processes are remarkably robust to network disruption. As long as even minimum amounts of data remain available somewhere in the network, the learning process is able to recover from disruptions and achieve significant classification accuracy. This clearly varies depending on the remaining connectivity after disruption, but we show that even nodes that remain completely isolated can retain significant knowledge acquired before the disruption.
Towards Human Awareness in Robot Task Planning with Large Language Models
Apr 17, 2024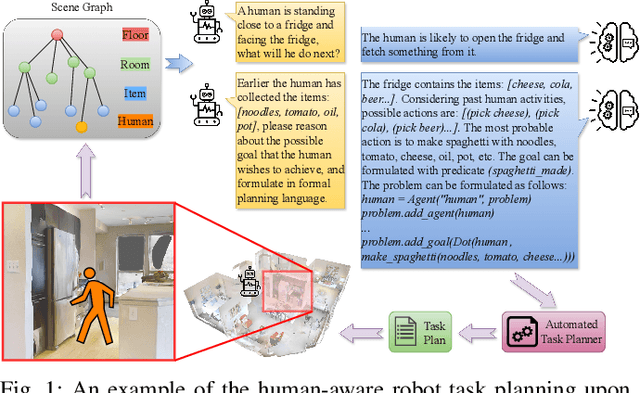
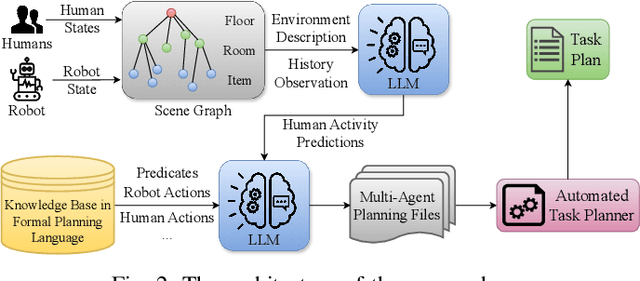
The recent breakthroughs in the research on Large Language Models (LLMs) have triggered a transformation across several research domains. Notably, the integration of LLMs has greatly enhanced performance in robot Task And Motion Planning (TAMP). However, previous approaches often neglect the consideration of dynamic environments, i.e., the presence of dynamic objects such as humans. In this paper, we propose a novel approach to address this gap by incorporating human awareness into LLM-based robot task planning. To obtain an effective representation of the dynamic environment, our approach integrates humans' information into a hierarchical scene graph. To ensure the plan's executability, we leverage LLMs to ground the environmental topology and actionable knowledge into formal planning language. Most importantly, we use LLMs to predict future human activities and plan tasks for the robot considering the predictions. Our contribution facilitates the development of integrating human awareness into LLM-driven robot task planning, and paves the way for proactive robot decision-making in dynamic environments.
DELTA: Decomposed Efficient Long-Term Robot Task Planning using Large Language Models
Apr 04, 2024



Recent advancements in Large Language Models (LLMs) have sparked a revolution across various research fields. In particular, the integration of common-sense knowledge from LLMs into robot task and motion planning has been proven to be a game-changer, elevating performance in terms of explainability and downstream task efficiency to unprecedented heights. However, managing the vast knowledge encapsulated within these large models has posed challenges, often resulting in infeasible plans generated by LLM-based planning systems due to hallucinations or missing domain information. To overcome these challenges and obtain even greater planning feasibility and computational efficiency, we propose a novel LLM-driven task planning approach called DELTA. For achieving better grounding from environmental topology into actionable knowledge, DELTA leverages the power of scene graphs as environment representations within LLMs, enabling the fast generation of precise planning problem descriptions. For obtaining higher planning performance, we use LLMs to decompose the long-term task goals into an autoregressive sequence of sub-goals for an automated task planner to solve. Our contribution enables a more efficient and fully automatic task planning pipeline, achieving higher planning success rates and significantly shorter planning times compared to the state of the art.