 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecHW: Heterogeneous Decentralized Federated Learning Exploiting Second-Order Information
Jan 16, 2026Decentralized Federated Learning (DFL) is a serverless collaborative machine learning paradigm where devices collaborate directly with neighbouring devices to exchange model information for learning a generalized model. However, variations in individual experiences and different levels of device interactions lead to data and model initialization heterogeneities across devices. Such heterogeneities leave variations in local model parameters across devices that leads to slower convergence. This paper tackles the data and model heterogeneity by explicitly addressing the parameter level varying evidential credence across local models. A novel aggregation approach is introduced that captures these parameter variations in local models and performs robust aggregation of neighbourhood local updates. Specifically, consensus weights are generated via approximation of second-order information of local models on their local datasets. These weights are utilized to scale neighbourhood updates before aggregating them into global neighbourhood representation. In extensive experiments with computer vision tasks, the proposed approach shows strong generalizability of local models at reduced communication costs.
The Built-In Robustness of Decentralized Federated Averaging to Bad Data
Feb 25, 2025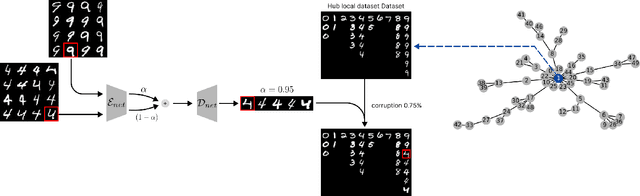
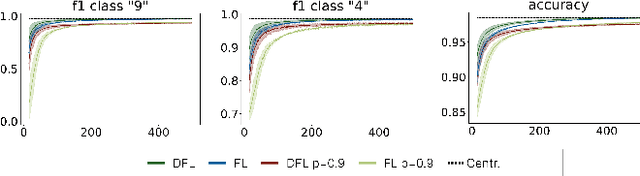

Decentralized federated learning (DFL) enables devices to collaboratively train models over complex network topologies without relying on a central controller. In this setting, local data remains private, but its quality and quantity can vary significantly across nodes. The extent to which a fully decentralized system is vulnerable to poor-quality or corrupted data remains unclear, but several factors could contribute to potential risks. Without a central authority, there can be no unified mechanism to detect or correct errors, and each node operates with a localized view of the data distribution, making it difficult for the node to assess whether its perspective aligns with the true distribution. Moreover, models trained on low-quality data can propagate through the network, amplifying errors. To explore the impact of low-quality data on DFL, we simulate two scenarios with degraded data quality -- one where the corrupted data is evenly distributed in a subset of nodes and one where it is concentrated on a single node -- using a decentralized implementation of FedAvg. Our results reveal that averaging-based decentralized learning is remarkably robust to localized bad data, even when the corrupted data resides in the most influential nodes of the network. Counterintuitively, this robustness is further enhanced when the corrupted data is concentrated on a single node, regardless of its centrality in the communication network topology. This phenomenon is explained by the averaging process, which ensures that no single node -- however central -- can disproportionately influence the overall learning process.
Robustness of Decentralised Learning to Nodes and Data Disruption
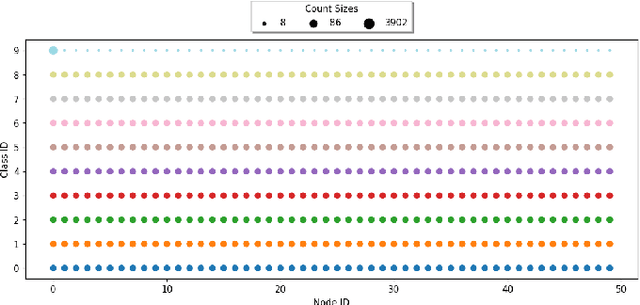
May 03, 2024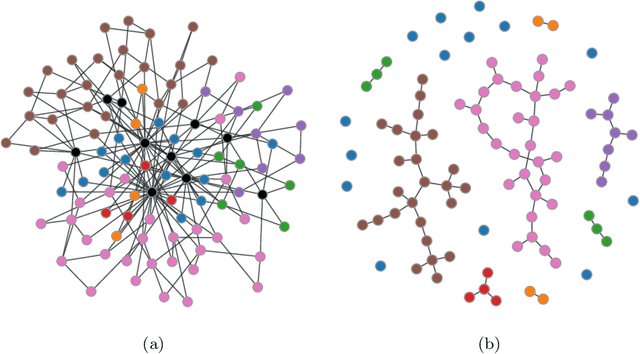


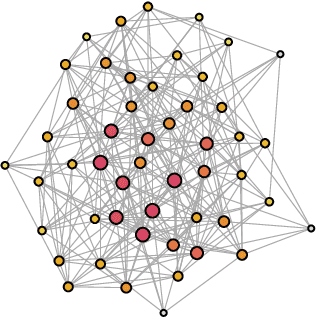
In the vibrant landscape of AI research, decentralised learning is gaining momentum. Decentralised learning allows individual nodes to keep data locally where they are generated and to share knowledge extracted from local data among themselves through an interactive process of collaborative refinement. This paradigm supports scenarios where data cannot leave local nodes due to privacy or sovereignty reasons or real-time constraints imposing proximity of models to locations where inference has to be carried out. The distributed nature of decentralised learning implies significant new research challenges with respect to centralised learning. Among them, in this paper, we focus on robustness issues. Specifically, we study the effect of nodes' disruption on the collective learning process. Assuming a given percentage of "central" nodes disappear from the network, we focus on different cases, characterised by (i) different distributions of data across nodes and (ii) different times when disruption occurs with respect to the start of the collaborative learning task. Through these configurations, we are able to show the non-trivial interplay between the properties of the network connecting nodes, the persistence of knowledge acquired collectively before disruption or lack thereof, and the effect of data availability pre- and post-disruption. Our results show that decentralised learning processes are remarkably robust to network disruption. As long as even minimum amounts of data remain available somewhere in the network, the learning process is able to recover from disruptions and achieve significant classification accuracy. This clearly varies depending on the remaining connectivity after disruption, but we show that even nodes that remain completely isolated can retain significant knowledge acquired before the disruption.
Initialisation and Topology Effects in Decentralised Federated Learning
Mar 23, 2024Fully decentralised federated learning enables collaborative training of individual machine learning models on distributed devices on a network while keeping the training data localised. This approach enhances data privacy and eliminates both the single point of failure and the necessity for central coordination. Our research highlights that the effectiveness of decentralised federated learning is significantly influenced by the network topology of connected devices. A simplified numerical model for studying the early behaviour of these systems leads us to an improved artificial neural network initialisation strategy, which leverages the distribution of eigenvector centralities of the nodes of the underlying network, leading to a radically improved training efficiency. Additionally, our study explores the scaling behaviour and choice of environmental parameters under our proposed initialisation strategy. This work paves the way for more efficient and scalable artificial neural network training in a distributed and uncoordinated environment, offering a deeper understanding of the intertwining roles of network structure and learning dynamics.
Impact of network topology on the performance of Decentralized Federated Learning
Feb 28, 2024



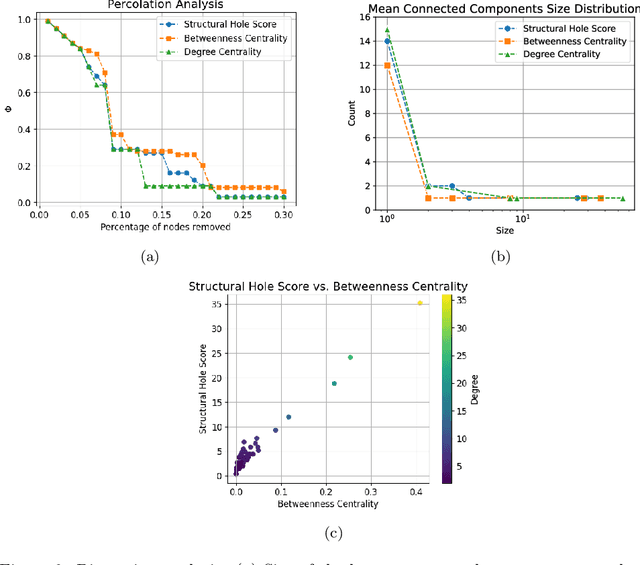
Fully decentralized learning is gaining momentum for training AI models at the Internet's edge, addressing infrastructure challenges and privacy concerns. In a decentralized machine learning system, data is distributed across multiple nodes, with each node training a local model based on its respective dataset. The local models are then shared and combined to form a global model capable of making accurate predictions on new data. Our exploration focuses on how different types of network structures influence the spreading of knowledge - the process by which nodes incorporate insights gained from learning patterns in data available on other nodes across the network. Specifically, this study investigates the intricate interplay between network structure and learning performance using three network topologies and six data distribution methods. These methods consider different vertex properties, including degree centrality, betweenness centrality, and clustering coefficient, along with whether nodes exhibit high or low values of these metrics. Our findings underscore the significance of global centrality metrics (degree, betweenness) in correlating with learning performance, while local clustering proves less predictive. We highlight the challenges in transferring knowledge from peripheral to central nodes, attributed to a dilution effect during model aggregation. Additionally, we observe that central nodes exert a pull effect, facilitating the spread of knowledge. In examining degree distribution, hubs in Barabasi-Albert networks positively impact learning for central nodes but exacerbate dilution when knowledge originates from peripheral nodes. Finally, we demonstrate the formidable challenge of knowledge circulation outside of segregated communities.
Coordination-free Decentralised Federated Learning on Complex Networks: Overcoming Heterogeneity
Dec 07, 2023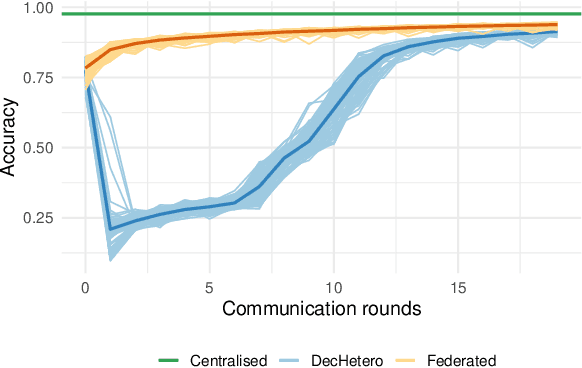
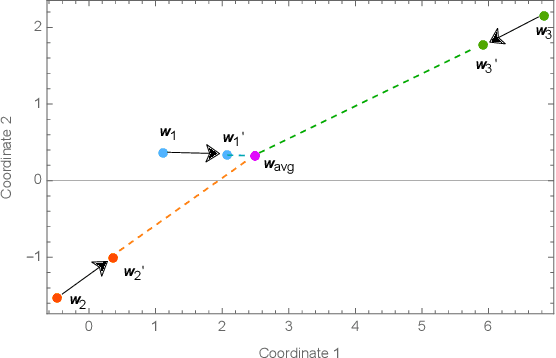
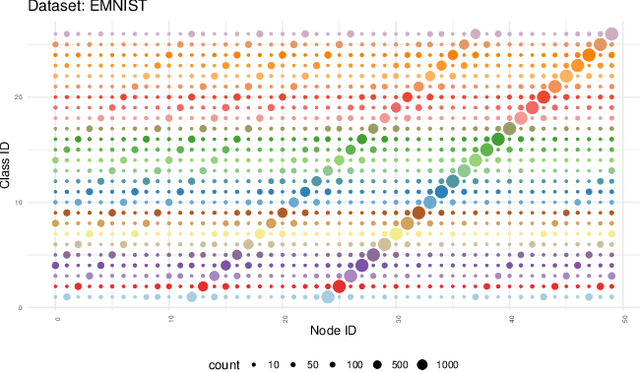
Federated Learning (FL) is a well-known framework for successfully performing a learning task in an edge computing scenario where the devices involved have limited resources and incomplete data representation. The basic assumption of FL is that the devices communicate directly or indirectly with a parameter server that centrally coordinates the whole process, overcoming several challenges associated with it. However, in highly pervasive edge scenarios, the presence of a central controller that oversees the process cannot always be guaranteed, and the interactions (i.e., the connectivity graph) between devices might not be predetermined, resulting in a complex network structure. Moreover, the heterogeneity of data and devices further complicates the learning process. This poses new challenges from a learning standpoint that we address by proposing a communication-efficient Decentralised Federated Learning (DFL) algorithm able to cope with them. Our solution allows devices communicating only with their direct neighbours to train an accurate model, overcoming the heterogeneity induced by data and different training histories. Our results show that the resulting local models generalise better than those trained with competing approaches, and do so in a more communication-efficient way.
Exploring the Impact of Disrupted Peer-to-Peer Communications on Fully Decentralized Learning in Disaster Scenarios
Oct 04, 2023
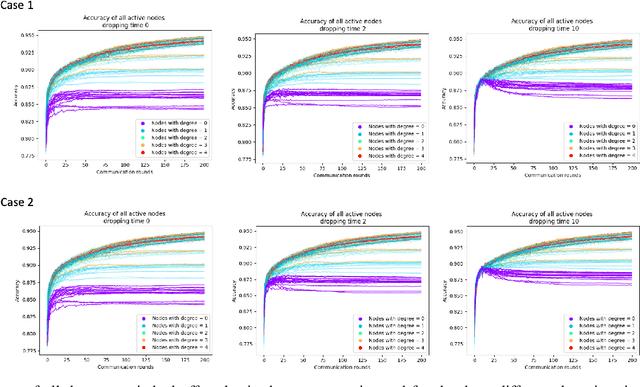
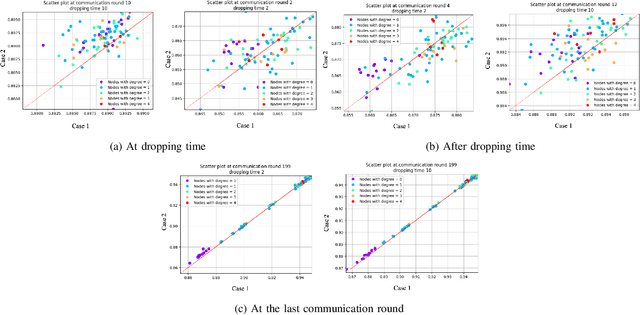
Fully decentralized learning enables the distribution of learning resources and decision-making capabilities across multiple user devices or nodes, and is rapidly gaining popularity due to its privacy-preserving and decentralized nature. Importantly, this crowdsourcing of the learning process allows the system to continue functioning even if some nodes are affected or disconnected. In a disaster scenario, communication infrastructure and centralized systems may be disrupted or completely unavailable, hindering the possibility of carrying out standard centralized learning tasks in these settings. Thus, fully decentralized learning can help in this case. However, transitioning from centralized to peer-to-peer communications introduces a dependency between the learning process and the topology of the communication graph among nodes. In a disaster scenario, even peer-to-peer communications are susceptible to abrupt changes, such as devices running out of battery or getting disconnected from others due to their position. In this study, we investigate the effects of various disruptions to peer-to-peer communications on decentralized learning in a disaster setting. We examine the resilience of a decentralized learning process when a subset of devices drop from the process abruptly. To this end, we analyze the difference between losing devices holding data, i.e., potential knowledge, vs. devices contributing only to the graph connectivity, i.e., with no data. Our findings on a Barabasi-Albert graph topology, where training data is distributed across nodes in an IID fashion, indicate that the accuracy of the learning process is more affected by a loss of connectivity than by a loss of data. Nevertheless, the network remains relatively robust, and the learning process can achieve a good level of accuracy.
The effect of network topologies on fully decentralized learning: a preliminary investigation
Jul 29, 2023



In a decentralized machine learning system, data is typically partitioned among multiple devices or nodes, each of which trains a local model using its own data. These local models are then shared and combined to create a global model that can make accurate predictions on new data. In this paper, we start exploring the role of the network topology connecting nodes on the performance of a Machine Learning model trained through direct collaboration between nodes. We investigate how different types of topologies impact the "spreading of knowledge", i.e., the ability of nodes to incorporate in their local model the knowledge derived by learning patterns in data available in other nodes across the networks. Specifically, we highlight the different roles in this process of more or less connected nodes (hubs and leaves), as well as that of macroscopic network properties (primarily, degree distribution and modularity). Among others, we show that, while it is known that even weak connectivity among network components is sufficient for information spread, it may not be sufficient for knowledge spread. More intuitively, we also find that hubs have a more significant role than leaves in spreading knowledge, although this manifests itself not only for heavy-tailed distributions but also when "hubs" have only moderately more connections than leaves. Finally, we show that tightly knit communities severely hinder knowledge spread.
Structural invariants and semantic fingerprints in the "ego network" of words
Mar 01, 2022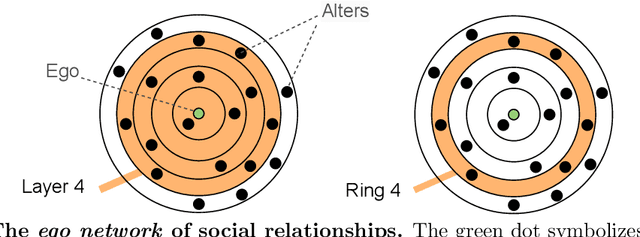
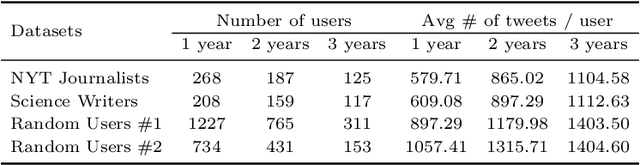
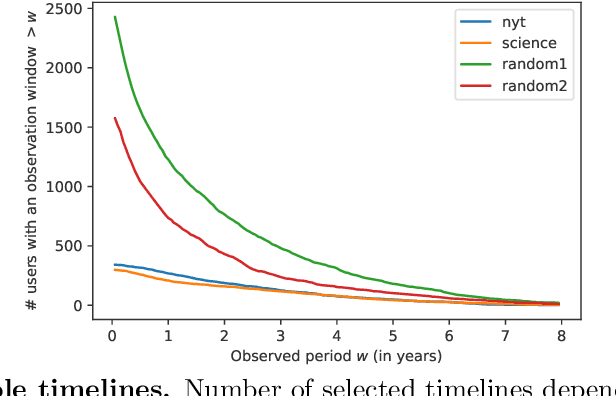

Well-established cognitive models coming from anthropology have shown that, due to the cognitive constraints that limit our "bandwidth" for social interactions, humans organize their social relations according to a regular structure. In this work, we postulate that similar regularities can be found in other cognitive processes, such as those involving language production. In order to investigate this claim, we analyse a dataset containing tweets of a heterogeneous group of Twitter users (regular users and professional writers). Leveraging a methodology similar to the one used to uncover the well-established social cognitive constraints, we find regularities at both the structural and semantic level. At the former, we find that a concentric layered structure (which we call ego network of words, in analogy to the ego network of social relationships) very well captures how individuals organise the words they use. The size of the layers in this structure regularly grows (approximately 2-3 times with respect to the previous one) when moving outwards, and the two penultimate external layers consistently account for approximately 60% and 30% of the used words, irrespective of the number of the total number of layers of the user. For the semantic analysis, each ring of each ego network is described by a semantic profile, which captures the topics associated with the words in the ring. We find that ring #1 has a special role in the model. It is semantically the most dissimilar and the most diverse among the rings. We also show that the topics that are important in the innermost ring also have the characteristic of being predominant in each of the other rings, as well as in the entire ego network. In this respect, ring #1 can be seen as the semantic fingerprint of the ego network of words.
Weak Signals in the Mobility Landscape: Car Sharing in Ten European Cities
Sep 20, 2021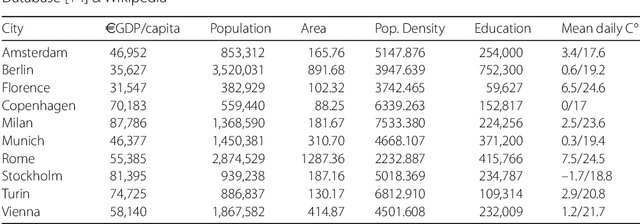

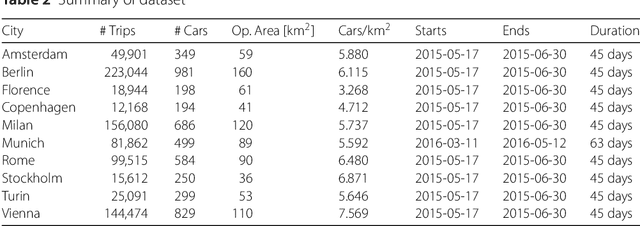
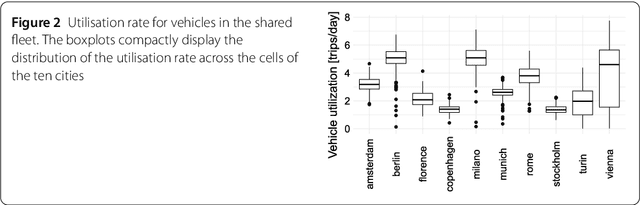
Car sharing is one the pillars of a smart transportation infrastructure, as it is expected to reduce traffic congestion, parking demands and pollution in our cities. From the point of view of demand modelling, car sharing is a weak signal in the city landscape: only a small percentage of the population uses it, and thus it is difficult to study reliably with traditional techniques such as households travel diaries. In this work, we depart from these traditional approaches and we leverage web-based, digital records about vehicle availability in 10 European cities for one of the major active car sharing operators. We discuss which sociodemographic and urban activity indicators are associated with variations in car sharing demand, which forecasting approach (among the most popular in the related literature) is better suited to predict pickup and drop-off events, and how the spatio-temporal information about vehicle availability can be used to infer how different zones in a city are used by customers. We conclude the paper by presenting a direct application of the analysis of the dataset, aimed at identifying where to locate maintenance facilities within the car sharing operation area.
* This work was partially funded by the ESPRIT, REPLICATE and SoBigData projects, which have received funding from the European Union's Horizon 2020 research and innovation programme under grant agreements No 653395, No 691735, and No 654024, respectively. arXiv admin note: text overlap with arXiv:1708.00497