 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural invariants and semantic fingerprints in the "ego network" of words
Paper and Code
Mar 01, 2022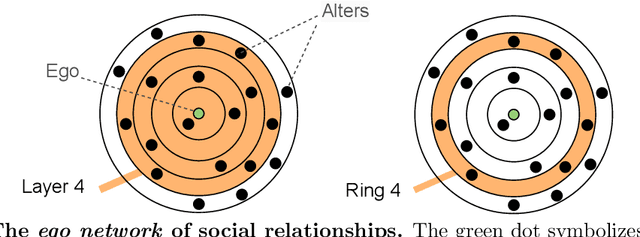
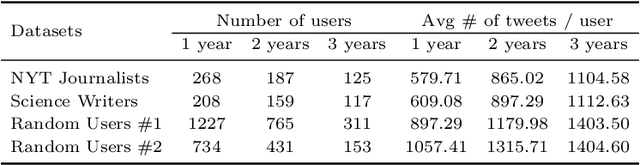
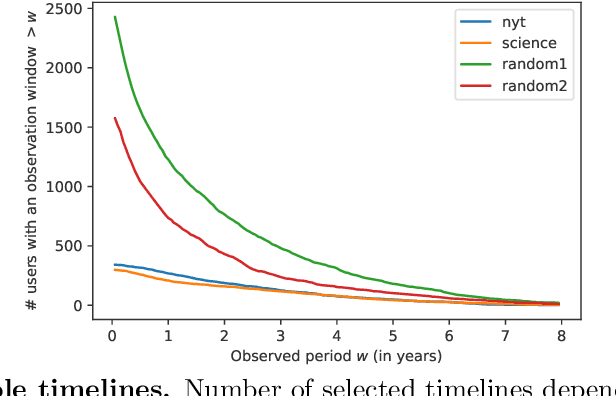

Well-established cognitive models coming from anthropology have shown that, due to the cognitive constraints that limit our "bandwidth" for social interactions, humans organize their social relations according to a regular structure. In this work, we postulate that similar regularities can be found in other cognitive processes, such as those involving language production. In order to investigate this claim, we analyse a dataset containing tweets of a heterogeneous group of Twitter users (regular users and professional writers). Leveraging a methodology similar to the one used to uncover the well-established social cognitive constraints, we find regularities at both the structural and semantic level. At the former, we find that a concentric layered structure (which we call ego network of words, in analogy to the ego network of social relationships) very well captures how individuals organise the words they use. The size of the layers in this structure regularly grows (approximately 2-3 times with respect to the previous one) when moving outwards, and the two penultimate external layers consistently account for approximately 60% and 30% of the used words, irrespective of the number of the total number of layers of the user. For the semantic analysis, each ring of each ego network is described by a semantic profile, which captures the topics associated with the words in the ring. We find that ring #1 has a special role in the model. It is semantically the most dissimilar and the most diverse among the rings. We also show that the topics that are important in the innermost ring also have the characteristic of being predominant in each of the other rings, as well as in the entire ego network. In this respect, ring #1 can be seen as the semantic fingerprint of the ego network of words.