 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Wealth Index Predictions in Africa between three Multi-Source Inference Models
Aug 03, 2024Poverty map inference is a critical area of research, with growing interest in both traditional and modern techniques, ranging from regression models to convolutional neural networks applied to tabular data, images, and networks. Despite extensive focus on the validation of training phases, the scrutiny of final predictions remains limited. Here, we compare the Relative Wealth Index (RWI) inferred by Chi et al. (2021) with the International Wealth Index (IWI) inferred by Lee and Braithwaite (2022) and Esp\'in-Noboa et al. (2023) across six Sub-Saharan African countries. Our analysis focuses on identifying trends and discrepancies in wealth predictions over time. Our results show that the predictions by Chi et al. and Esp\'in-Noboa et al. align with general GDP trends, with differences expected due to the distinct time-frames of the training sets. However, predictions by Lee and Braithwaite diverge significantly, indicating potential issues with the validity of the model. These discrepancies highlight the need for policymakers and stakeholders in Africa to rigorously audit models that predict wealth, especially those used for decision-making on the ground. These and other techniques require continuous verification and refinement to enhance their reliability and ensure that poverty alleviation strategies are well-founded.
Initialisation and Topology Effects in Decentralised Federated Learning
Mar 23, 2024Fully decentralised federated learning enables collaborative training of individual machine learning models on distributed devices on a network while keeping the training data localised. This approach enhances data privacy and eliminates both the single point of failure and the necessity for central coordination. Our research highlights that the effectiveness of decentralised federated learning is significantly influenced by the network topology of connected devices. A simplified numerical model for studying the early behaviour of these systems leads us to an improved artificial neural network initialisation strategy, which leverages the distribution of eigenvector centralities of the nodes of the underlying network, leading to a radically improved training efficiency. Additionally, our study explores the scaling behaviour and choice of environmental parameters under our proposed initialisation strategy. This work paves the way for more efficient and scalable artificial neural network training in a distributed and uncoordinated environment, offering a deeper understanding of the intertwining roles of network structure and learning dynamics.
Coordination-free Decentralised Federated Learning on Complex Networks: Overcoming Heterogeneity
Dec 07, 2023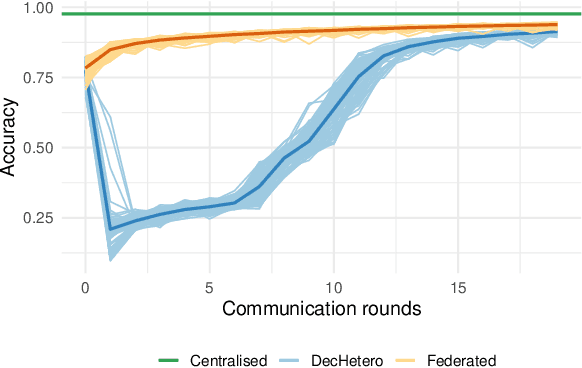
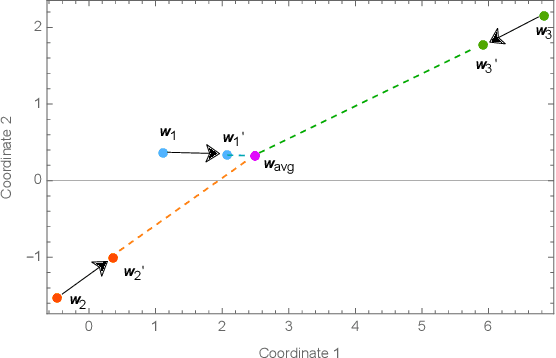
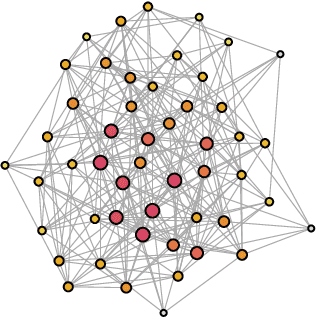
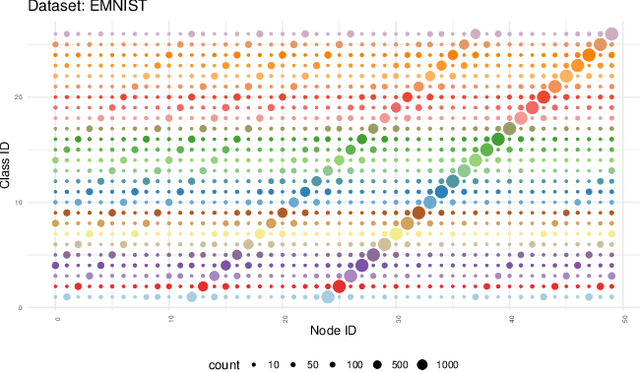
Federated Learning (FL) is a well-known framework for successfully performing a learning task in an edge computing scenario where the devices involved have limited resources and incomplete data representation. The basic assumption of FL is that the devices communicate directly or indirectly with a parameter server that centrally coordinates the whole process, overcoming several challenges associated with it. However, in highly pervasive edge scenarios, the presence of a central controller that oversees the process cannot always be guaranteed, and the interactions (i.e., the connectivity graph) between devices might not be predetermined, resulting in a complex network structure. Moreover, the heterogeneity of data and devices further complicates the learning process. This poses new challenges from a learning standpoint that we address by proposing a communication-efficient Decentralised Federated Learning (DFL) algorithm able to cope with them. Our solution allows devices communicating only with their direct neighbours to train an accurate model, overcoming the heterogeneity induced by data and different training histories. Our results show that the resulting local models generalise better than those trained with competing approaches, and do so in a more communication-efficient way.
Interpreting wealth distribution via poverty map inference using multimodal data
Feb 17, 2023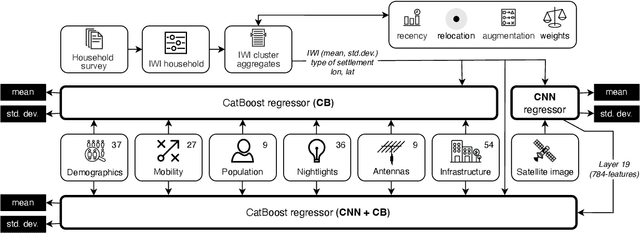
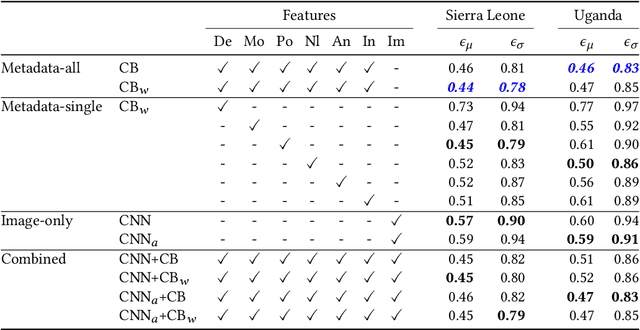
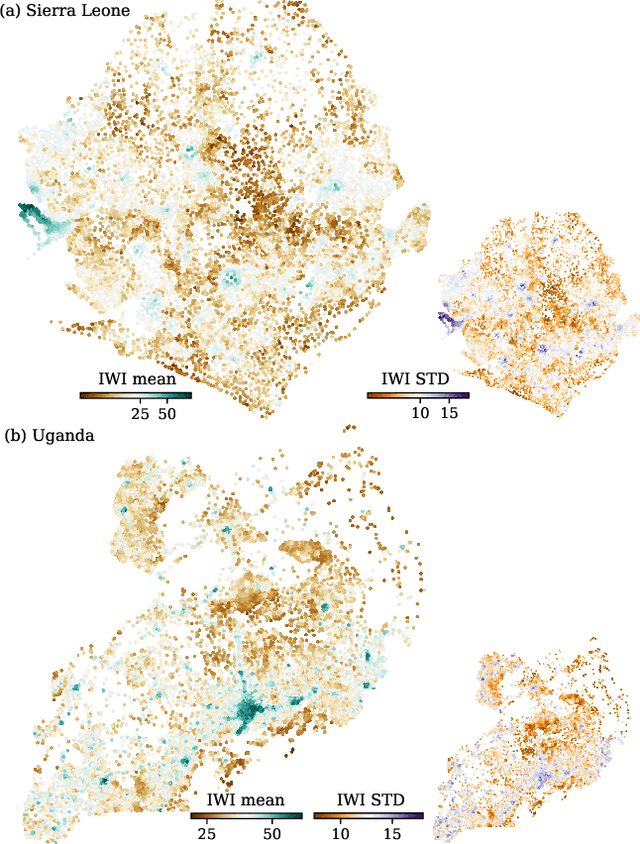
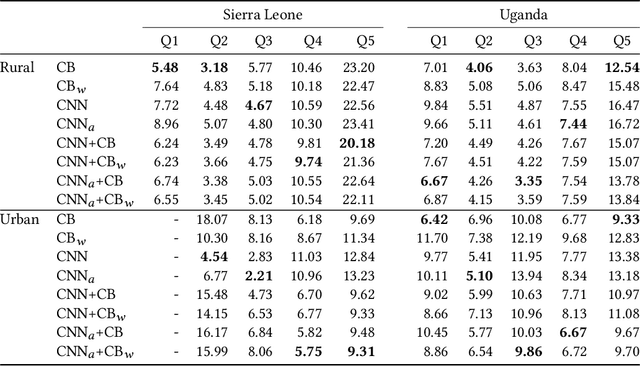
Poverty maps are essential tools for governments and NGOs to track socioeconomic changes and adequately allocate infrastructure and services in places in need. Sensor and online crowd-sourced data combined with machine learning methods have provided a recent breakthrough in poverty map inference. However, these methods do not capture local wealth fluctuations, and are not optimized to produce accountable results that guarantee accurate predictions to all sub-populations. Here, we propose a pipeline of machine learning models to infer the mean and standard deviation of wealth across multiple geographically clustered populated places, and illustrate their performance in Sierra Leone and Uganda. These models leverage seven independent and freely available feature sources based on satellite images, and metadata collected via online crowd-sourcing and social media. Our models show that combined metadata features are the best predictors of wealth in rural areas, outperforming image-based models, which are the best for predicting the highest wealth quintiles. Our results recover the local mean and variation of wealth, and correctly capture the positive yet non-monotonous correlation between them. We further demonstrate the capabilities and limitations of model transfer across countries and the effects of data recency and other biases. Our methodology provides open tools to build towards more transparent and interpretable models to help governments and NGOs to make informed decisions based on data availability, urbanization level, and poverty thresholds.
Socioeconomic correlations of urban patterns inferred from aerial images: interpreting activation maps of Convolutional Neural Networks
Apr 10, 2020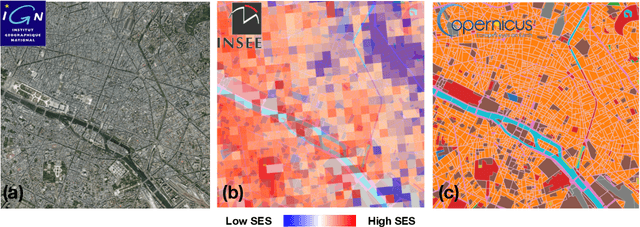
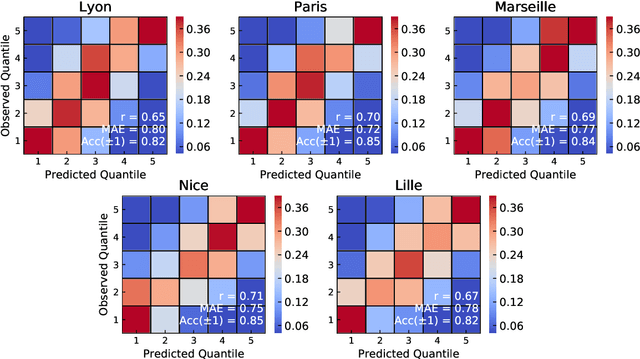
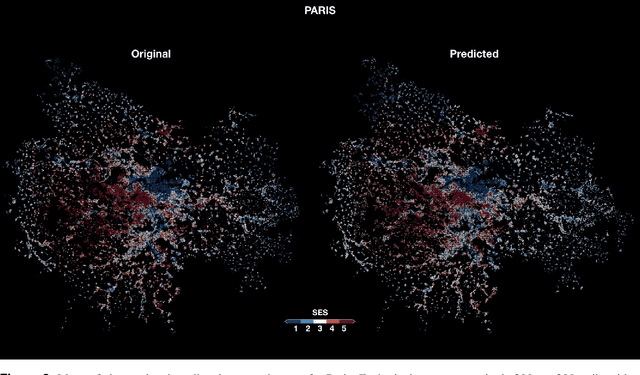

Urbanisation is a great challenge for modern societies, promising better access to economic opportunities while widening socioeconomic inequalities. Accurately tracking how this process unfolds has been challenging for traditional data collection methods, while remote sensing information offers an alternative to gather a more complete view on these societal changes. By feeding a neural network with satellite images one may recover the socioeconomic information associated to that area, however these models lack to explain how visual features contained in a sample, trigger a given prediction. Here we close this gap by predicting socioeconomic status across France from aerial images and interpreting class activation mappings in terms of urban topology. We show that the model disregards the spatial correlations existing between urban class and socioeconomic status to derive its predictions. These results pave the way to build interpretable models, which may help to better track and understand urbanisation and its consequences.
weg2vec: Event embedding for temporal networks
Nov 06, 2019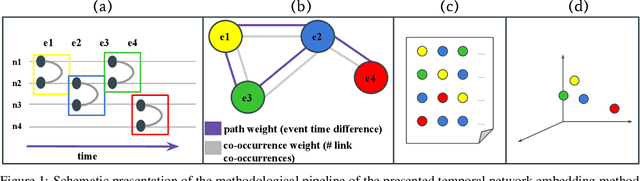
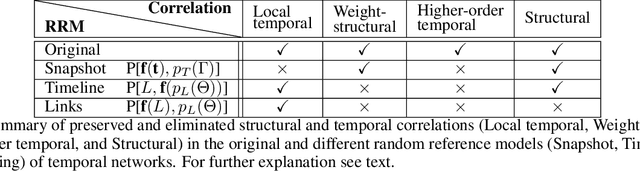


Network embedding techniques are powerful to capture structural regularities in networks and to identify similarities between their local fabrics. However, conventional network embedding models are developed for static structures, commonly consider nodes only and they are seriously challenged when the network is varying in time. Temporal networks may provide an advantage in the description of real systems, but they code more complex information, which could be effectively represented only by a handful of methods so far. Here, we propose a new method of event embedding of temporal networks, called weg2vec, which builds on temporal and structural similarities of events to learn a low dimensional representation of a temporal network. This projection successfully captures latent structures and similarities between events involving different nodes at different times and provides ways to predict the final outcome of spreading processes unfolding on the temporal structure.
Joint embedding of structure and features via graph convolutional networks
May 23, 2019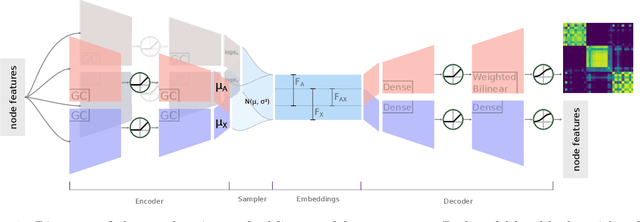
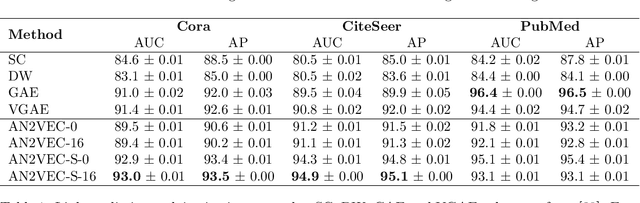
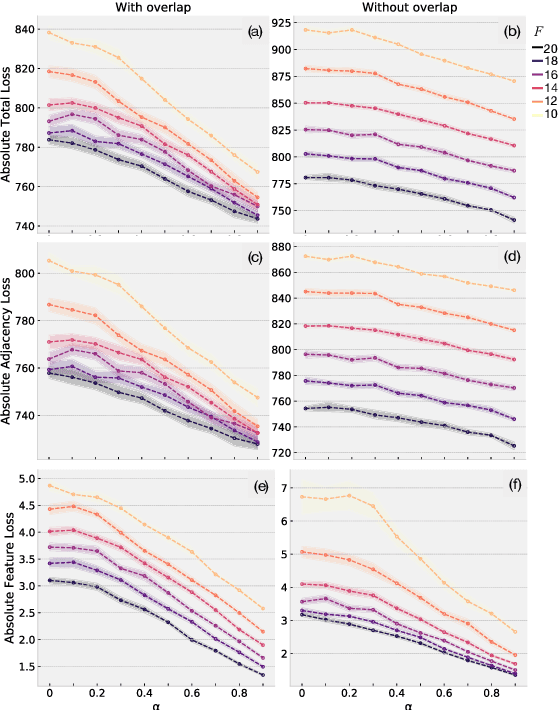
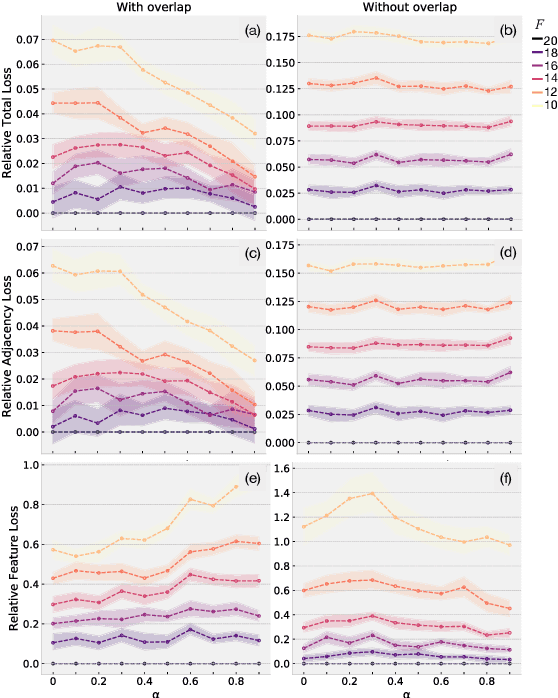
The creation of social ties is largely determined by the entangled effects of people's similarities in terms of individual characters and friends. However, feature and structural characters of people usually appear to be correlated, making it difficult to determine which has greater responsibility in the formation of the emergent network structure. We propose \emph{AN2VEC}, a node embedding method which ultimately aims at disentangling the information shared by the structure of a network and the features of its nodes. Building on the recent developments of Graph Convolutional Networks (GCN), we develop a multitask GCN Variational Autoencoder where different dimensions of the generated embeddings can be dedicated to encoding feature information, network structure, and shared feature-network information. We explore the interaction between these disentangled characters by comparing the embedding reconstruction performance to a baseline case where no shared information is extracted. We use synthetic datasets with different levels of interdependency between feature and network characters and show (i) that shallow embeddings relying on shared information perform better than the corresponding reference with unshared information, (ii) that this performance gap increases with the correlation between network and feature structure, and (iii) that our embedding is able to capture joint information of structure and features. Our method can be relevant for the analysis and prediction of any featured network structure ranging from online social systems to network medicine.
Location, Occupation, and Semantics based Socioeconomic Status Inference on Twitter
Jan 16, 2019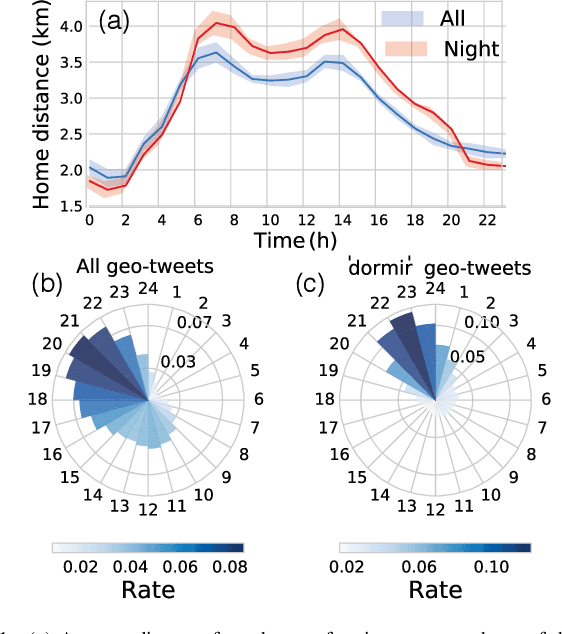
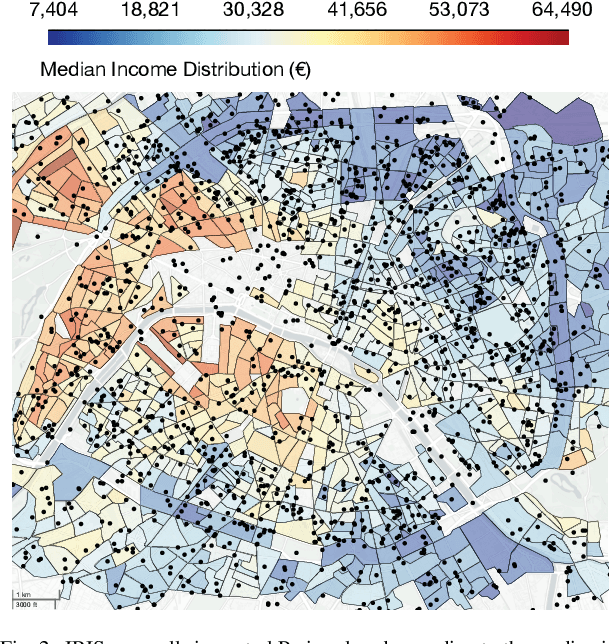
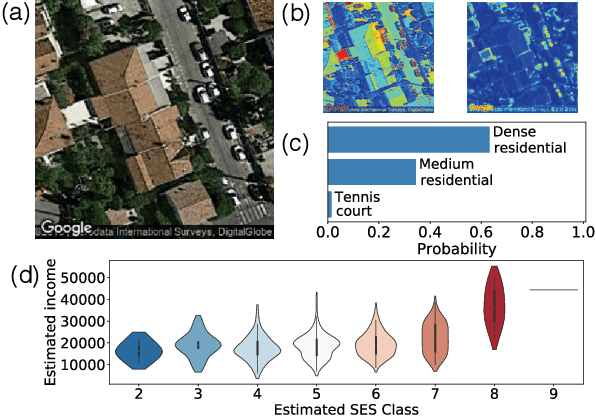
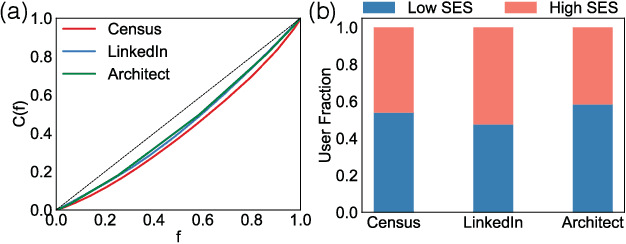
The socioeconomic status of people depends on a combination of individual characteristics and environmental variables, thus its inference from online behavioral data is a difficult task. Attributes like user semantics in communication, habitat, occupation, or social network are all known to be determinant predictors of this feature. In this paper we propose three different data collection and combination methods to first estimate and, in turn, infer the socioeconomic status of French Twitter users from their online semantics. Our methods are based on open census data, crawled professional profiles, and remotely sensed, expert annotated information on living environment. Our inference models reach similar performance of earlier results with the advantage of relying on broadly available datasets and of providing a generalizable framework to estimate socioeconomic status of large numbers of Twitter users. These results may contribute to the scientific discussion on social stratification and inequalities, and may fuel several applications.
Socioeconomic Dependencies of Linguistic Patterns in Twitter: A Multivariate Analysis
Apr 03, 2018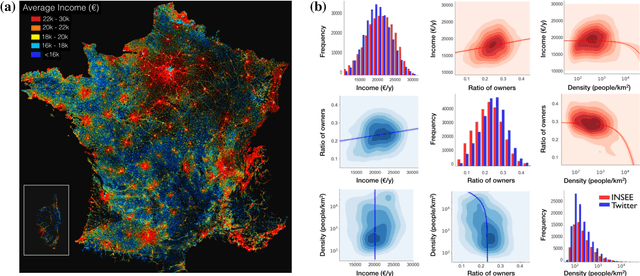
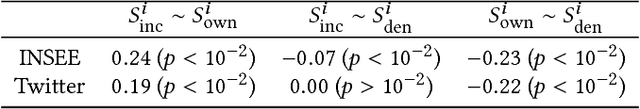
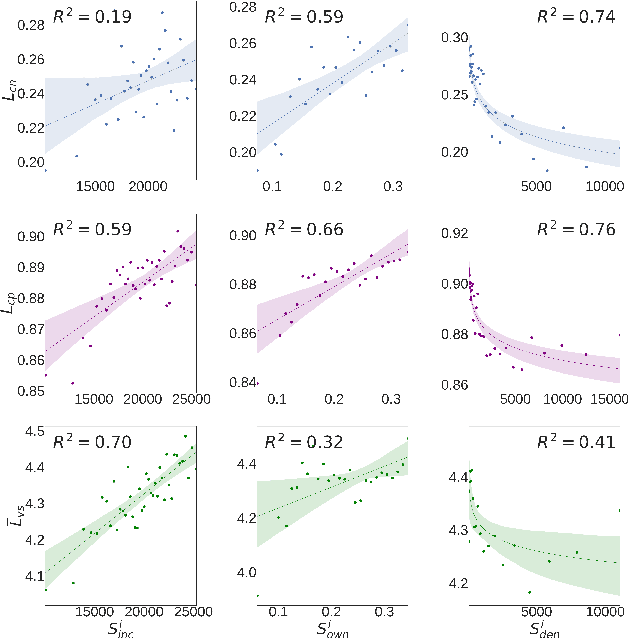
Our usage of language is not solely reliant on cognition but is arguably determined by myriad external factors leading to a global variability of linguistic patterns. This issue, which lies at the core of sociolinguistics and is backed by many small-scale studies on face-to-face communication, is addressed here by constructing a dataset combining the largest French Twitter corpus to date with detailed socioeconomic maps obtained from national census in France. We show how key linguistic variables measured in individual Twitter streams depend on factors like socioeconomic status, location, time, and the social network of individuals. We found that (i) people of higher socioeconomic status, active to a greater degree during the daytime, use a more standard language; (ii) the southern part of the country is more prone to use more standard language than the northern one, while locally the used variety or dialect is determined by the spatial distribution of socioeconomic status; and (iii) individuals connected in the social network are closer linguistically than disconnected ones, even after the effects of status homophily have been removed. Our results inform sociolinguistic theory and may inspire novel learning methods for the inference of socioeconomic status of people from the way they tweet.
Prepaid or Postpaid? That is the question. Novel Methods of Subscription Type Prediction in Mobile Phone Services
Jun 30, 2017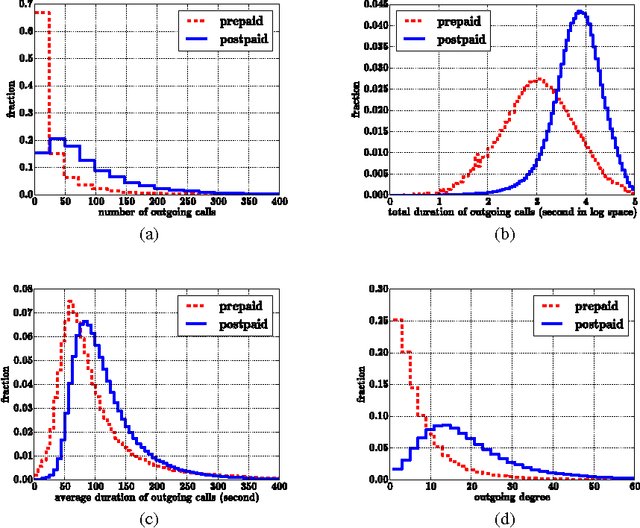


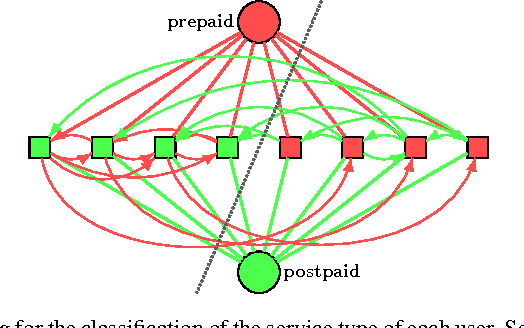
In this paper we investigate the behavioural differences between mobile phone customers with prepaid and postpaid subscriptions. Our study reveals that (a) postpaid customers are more active in terms of service usage and (b) there are strong structural correlations in the mobile phone call network as connections between customers of the same subscription type are much more frequent than those between customers of different subscription types. Based on these observations we provide methods to detect the subscription type of customers by using information about their personal call statistics, and also their egocentric networks simultaneously. The key of our first approach is to cast this classification problem as a problem of graph labelling, which can be solved by max-flow min-cut algorithms. Our experiments show that, by using both user attributes and relationships, the proposed graph labelling approach is able to achieve a classification accuracy of $\sim 87\%$, which outperforms by $\sim 7\%$ supervised learning methods using only user attributes. In our second problem we aim to infer the subscription type of customers of external operators. We propose via approximate methods to solve this problem by using node attributes, and a two-ways indirect inference method based on observed homophilic structural correlations. Our results have straightforward applications in behavioural prediction and personal marketing.