 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Wealth Index Predictions in Africa between three Multi-Source Inference Models
Aug 03, 2024Poverty map inference is a critical area of research, with growing interest in both traditional and modern techniques, ranging from regression models to convolutional neural networks applied to tabular data, images, and networks. Despite extensive focus on the validation of training phases, the scrutiny of final predictions remains limited. Here, we compare the Relative Wealth Index (RWI) inferred by Chi et al. (2021) with the International Wealth Index (IWI) inferred by Lee and Braithwaite (2022) and Esp\'in-Noboa et al. (2023) across six Sub-Saharan African countries. Our analysis focuses on identifying trends and discrepancies in wealth predictions over time. Our results show that the predictions by Chi et al. and Esp\'in-Noboa et al. align with general GDP trends, with differences expected due to the distinct time-frames of the training sets. However, predictions by Lee and Braithwaite diverge significantly, indicating potential issues with the validity of the model. These discrepancies highlight the need for policymakers and stakeholders in Africa to rigorously audit models that predict wealth, especially those used for decision-making on the ground. These and other techniques require continuous verification and refinement to enhance their reliability and ensure that poverty alleviation strategies are well-founded.
Robustness of Decentralised Learning to Nodes and Data Disruption
May 03, 2024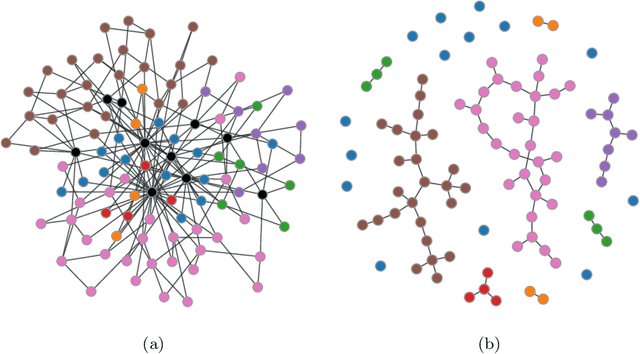


In the vibrant landscape of AI research, decentralised learning is gaining momentum. Decentralised learning allows individual nodes to keep data locally where they are generated and to share knowledge extracted from local data among themselves through an interactive process of collaborative refinement. This paradigm supports scenarios where data cannot leave local nodes due to privacy or sovereignty reasons or real-time constraints imposing proximity of models to locations where inference has to be carried out. The distributed nature of decentralised learning implies significant new research challenges with respect to centralised learning. Among them, in this paper, we focus on robustness issues. Specifically, we study the effect of nodes' disruption on the collective learning process. Assuming a given percentage of "central" nodes disappear from the network, we focus on different cases, characterised by (i) different distributions of data across nodes and (ii) different times when disruption occurs with respect to the start of the collaborative learning task. Through these configurations, we are able to show the non-trivial interplay between the properties of the network connecting nodes, the persistence of knowledge acquired collectively before disruption or lack thereof, and the effect of data availability pre- and post-disruption. Our results show that decentralised learning processes are remarkably robust to network disruption. As long as even minimum amounts of data remain available somewhere in the network, the learning process is able to recover from disruptions and achieve significant classification accuracy. This clearly varies depending on the remaining connectivity after disruption, but we show that even nodes that remain completely isolated can retain significant knowledge acquired before the disruption.
Milgram's experiment in the knowledge space: Individual navigation strategies
Apr 09, 2024Data deluge characteristic for our times has led to information overload, posing a significant challenge to effectively finding our way through the digital landscape. Addressing this issue requires an in-depth understanding of how we navigate through the abundance of information. Previous research has discovered multiple patterns in how individuals navigate in the geographic, social, and information spaces, yet individual differences in strategies for navigation in the knowledge space has remained largely unexplored. To bridge the gap, we conducted an online experiment where participants played a navigation game on Wikipedia and completed questionnaires about their personal information. Utilizing a graph embedding trained on the English Wikipedia, our study identified distinctive strategies that participants adopt: when the target is a famous person, participants typically use the geographical and occupational information of the target to navigate, reminiscent of hub-driven and proximity-driven approaches, respectively. We discovered that many participants playing the same game exhibit a "wisdom of the crowd" effect: The set of strategies provide a good estimate for the information landscape around the target indicating that the individual differences complement each other.
Initialisation and Topology Effects in Decentralised Federated Learning
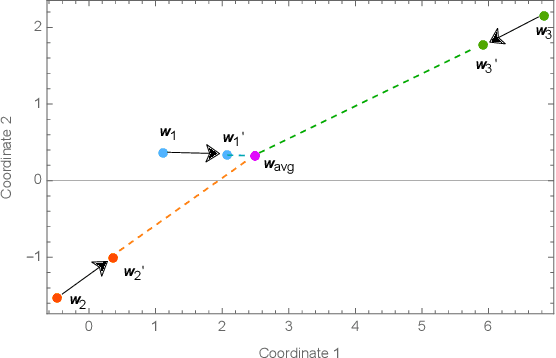
Mar 23, 2024Fully decentralised federated learning enables collaborative training of individual machine learning models on distributed devices on a network while keeping the training data localised. This approach enhances data privacy and eliminates both the single point of failure and the necessity for central coordination. Our research highlights that the effectiveness of decentralised federated learning is significantly influenced by the network topology of connected devices. A simplified numerical model for studying the early behaviour of these systems leads us to an improved artificial neural network initialisation strategy, which leverages the distribution of eigenvector centralities of the nodes of the underlying network, leading to a radically improved training efficiency. Additionally, our study explores the scaling behaviour and choice of environmental parameters under our proposed initialisation strategy. This work paves the way for more efficient and scalable artificial neural network training in a distributed and uncoordinated environment, offering a deeper understanding of the intertwining roles of network structure and learning dynamics.
Coordination-free Decentralised Federated Learning on Complex Networks: Overcoming Heterogeneity
Dec 07, 2023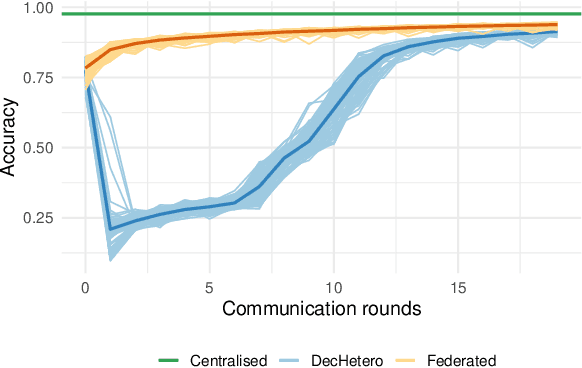
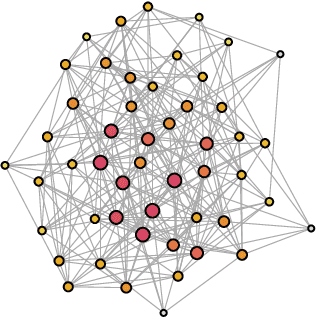
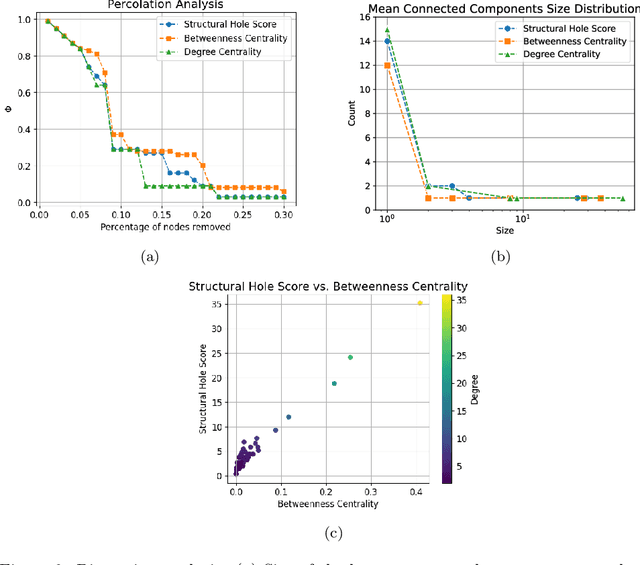
Federated Learning (FL) is a well-known framework for successfully performing a learning task in an edge computing scenario where the devices involved have limited resources and incomplete data representation. The basic assumption of FL is that the devices communicate directly or indirectly with a parameter server that centrally coordinates the whole process, overcoming several challenges associated with it. However, in highly pervasive edge scenarios, the presence of a central controller that oversees the process cannot always be guaranteed, and the interactions (i.e., the connectivity graph) between devices might not be predetermined, resulting in a complex network structure. Moreover, the heterogeneity of data and devices further complicates the learning process. This poses new challenges from a learning standpoint that we address by proposing a communication-efficient Decentralised Federated Learning (DFL) algorithm able to cope with them. Our solution allows devices communicating only with their direct neighbours to train an accurate model, overcoming the heterogeneity induced by data and different training histories. Our results show that the resulting local models generalise better than those trained with competing approaches, and do so in a more communication-efficient way.
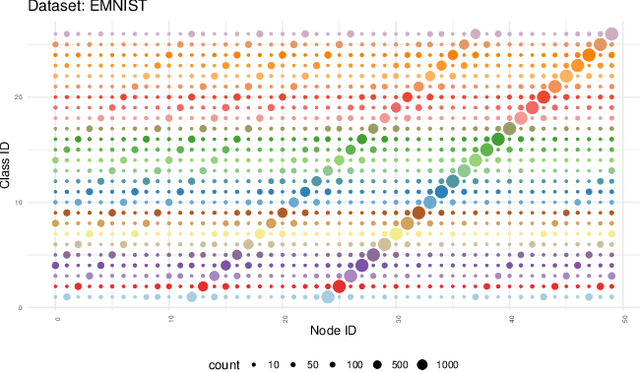
Interpreting wealth distribution via poverty map inference using multimodal data
Feb 17, 2023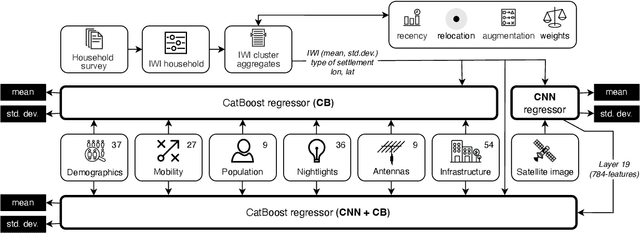
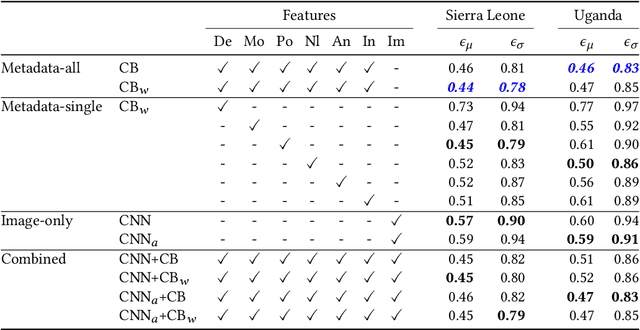
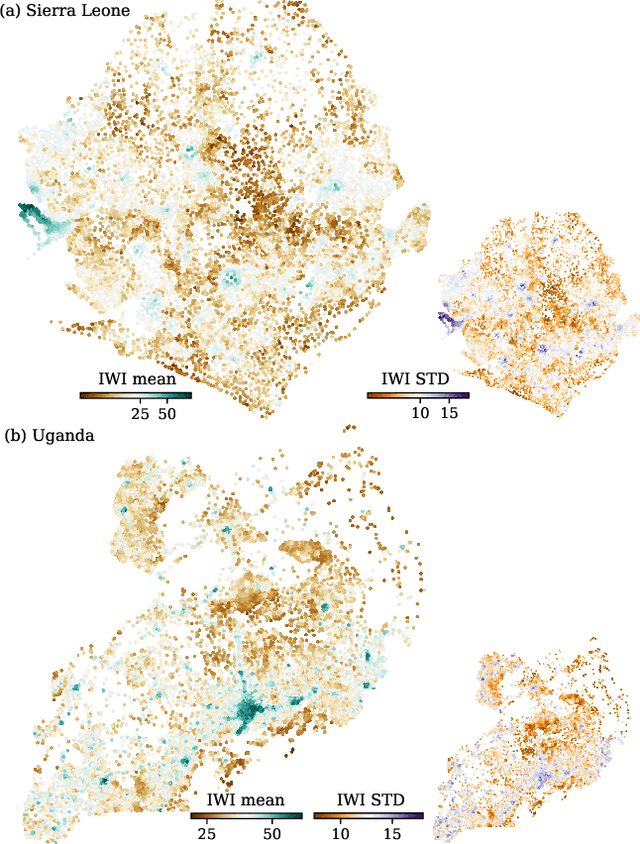
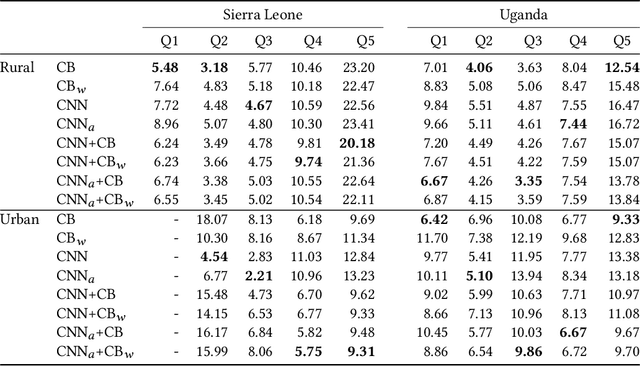
Poverty maps are essential tools for governments and NGOs to track socioeconomic changes and adequately allocate infrastructure and services in places in need. Sensor and online crowd-sourced data combined with machine learning methods have provided a recent breakthrough in poverty map inference. However, these methods do not capture local wealth fluctuations, and are not optimized to produce accountable results that guarantee accurate predictions to all sub-populations. Here, we propose a pipeline of machine learning models to infer the mean and standard deviation of wealth across multiple geographically clustered populated places, and illustrate their performance in Sierra Leone and Uganda. These models leverage seven independent and freely available feature sources based on satellite images, and metadata collected via online crowd-sourcing and social media. Our models show that combined metadata features are the best predictors of wealth in rural areas, outperforming image-based models, which are the best for predicting the highest wealth quintiles. Our results recover the local mean and variation of wealth, and correctly capture the positive yet non-monotonous correlation between them. We further demonstrate the capabilities and limitations of model transfer across countries and the effects of data recency and other biases. Our methodology provides open tools to build towards more transparent and interpretable models to help governments and NGOs to make informed decisions based on data availability, urbanization level, and poverty thresholds.
The most controversial topics in Wikipedia: A multilingual and geographical analysis
Jul 08, 2013
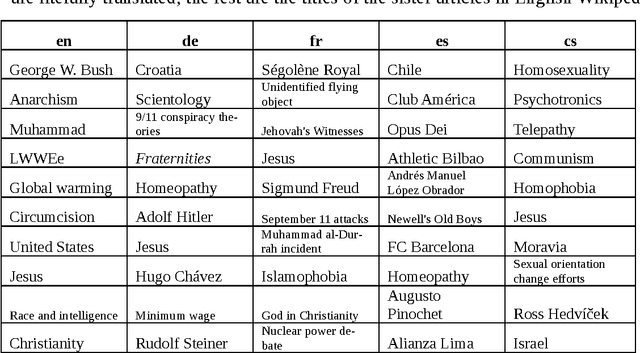
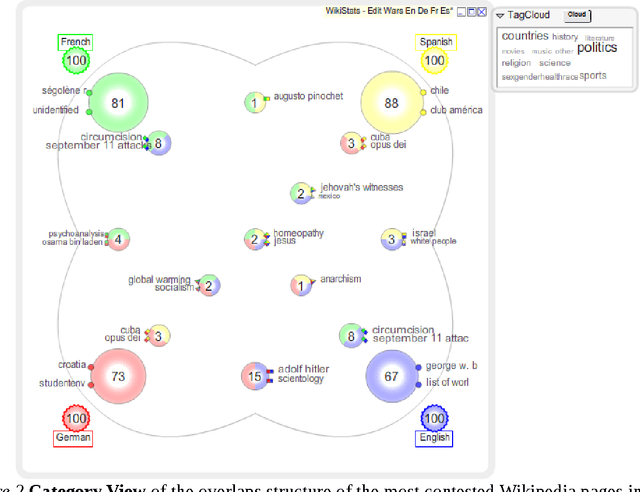
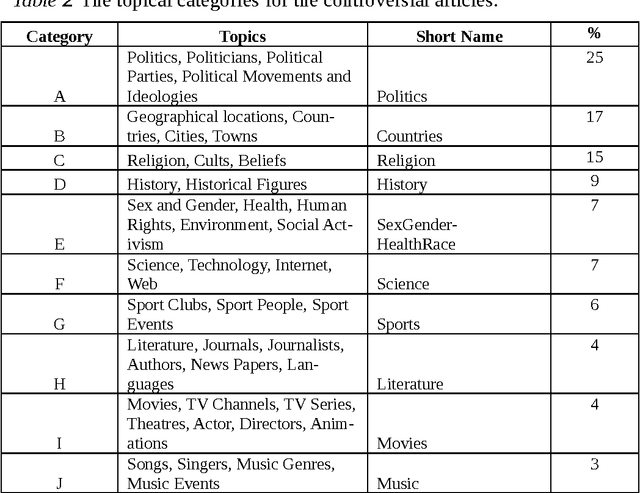
We present, visualize and analyse the similarities and differences between the controversial topics related to "edit wars" identified in 10 different language versions of Wikipedia. After a brief review of the related work we describe the methods developed to locate, measure, and categorize the controversial topics in the different languages. Visualizations of the degree of overlap between the top 100 lists of most controversial articles in different languages and the content related to geographical locations will be presented. We discuss what the presented analysis and visualizations can tell us about the multicultural aspects of Wikipedia and practices of peer-production. Our results indicate that Wikipedia is more than just an encyclopaedia; it is also a window into convergent and divergent social-spatial priorities, interests and preferences.
A practical approach to language complexity: a Wikipedia case study
Aug 18, 2012



In this paper we present statistical analysis of English texts from Wikipedia. We try to address the issue of language complexity empirically by comparing the simple English Wikipedia (Simple) to comparable samples of the main English Wikipedia (Main). Simple is supposed to use a more simplified language with a limited vocabulary, and editors are explicitly requested to follow this guideline, yet in practice the vocabulary richness of both samples are at the same level. Detailed analysis of longer units (n-grams of words and part of speech tags) shows that the language of Simple is less complex than that of Main primarily due to the use of shorter sentences, as opposed to drastically simplified syntax or vocabulary. Comparing the two language varieties by the Gunning readability index supports this conclusion. We also report on the topical dependence of language complexity, e.g. that the language is more advanced in conceptual articles compared to person-based (biographical) and object-based articles. Finally, we investigate the relation between conflict and language complexity by analyzing the content of the talk pages associated to controversial and peacefully developing articles, concluding that controversy has the effect of reducing language complexity.
* 2 new figures, 1 new section, and 2 new supporting texts
Edit wars in Wikipedia
Feb 09, 2012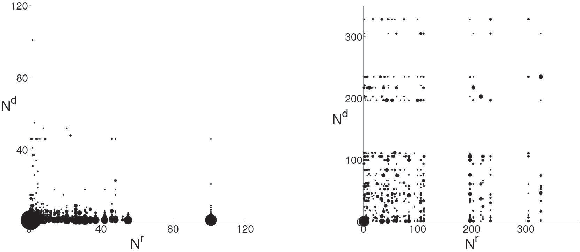
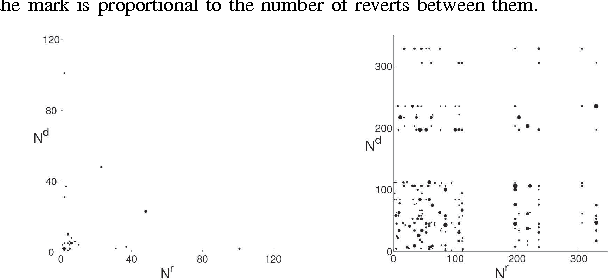
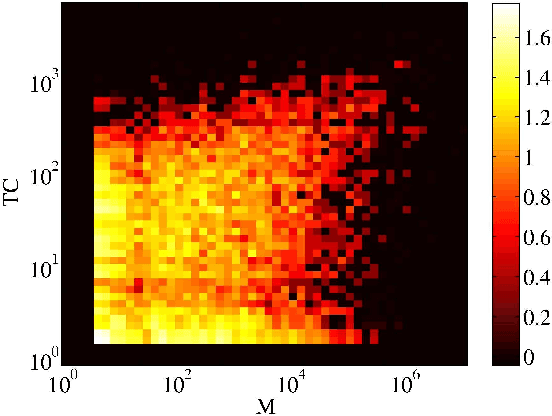
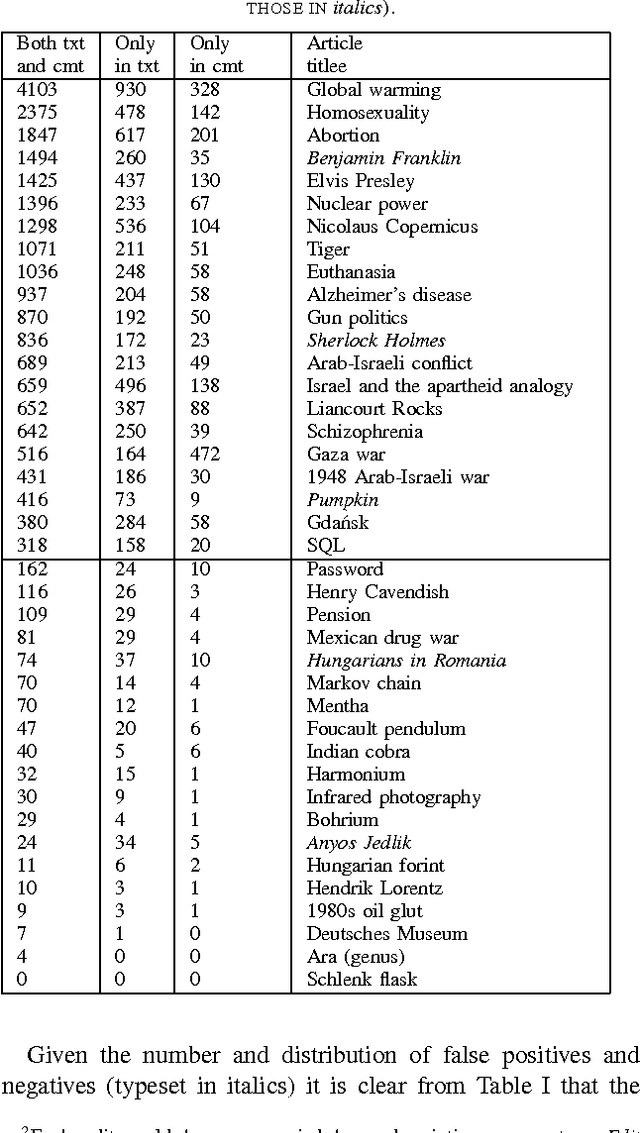
We present a new, efficient method for automatically detecting severe conflicts `edit wars' in Wikipedia and evaluate this method on six different language WPs. We discuss how the number of edits, reverts, the length of discussions, the burstiness of edits and reverts deviate in such pages from those following the general workflow, and argue that earlier work has significantly over-estimated the contentiousness of the Wikipedia editing process.
* 4 pages, 2 figures, 3 tables. The current version is shortened to be published in SocialCom 2011