 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster automata
Mar 27, 2025

We introduce a new class of clustered Moore automata (CMA), investigate their temporal behavior, and describe some applications.
Do Attention Heads Compete or Cooperate during Counting?
Feb 10, 2025We present an in-depth mechanistic interpretability analysis of training small transformers on an elementary task, counting, which is a crucial deductive step in many algorithms. In particular, we investigate the collaboration/competition among the attention heads: we ask whether the attention heads behave as a pseudo-ensemble, all solving the same subtask, or they perform different subtasks, meaning that they can only solve the original task in conjunction. Our work presents evidence that on the semantics of the counting task, attention heads behave as a pseudo-ensemble, but their outputs need to be aggregated in a non-uniform manner in order to create an encoding that conforms to the syntax. Our source code will be available upon publication.
Safety without alignment
Mar 18, 2023Currently, the dominant paradigm in AI safety is alignment with human values. Here we describe progress on developing an alternative approach to safety, based on ethical rationalism (Gewirth:1978), and propose an inherently safe implementation path via hybrid theorem provers in a sandbox. As AGIs evolve, their alignment may fade, but their rationality can only increase (otherwise more rational ones will have a significant evolutionary advantage) so an approach that ties their ethics to their rationality has clear long-term advantages.
Evaluating Transferability of BERT Models on Uralic Languages
Sep 13, 2021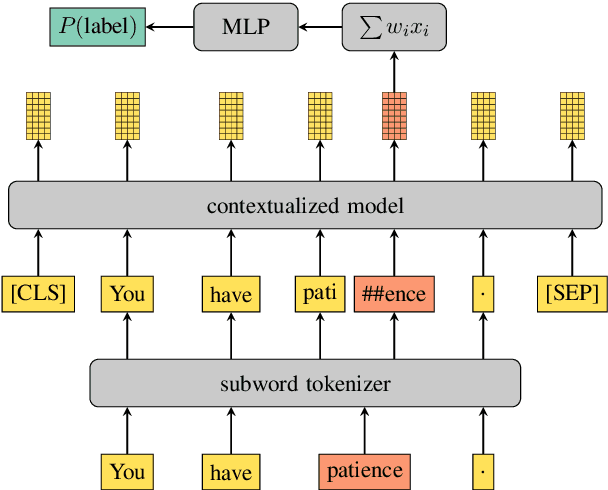
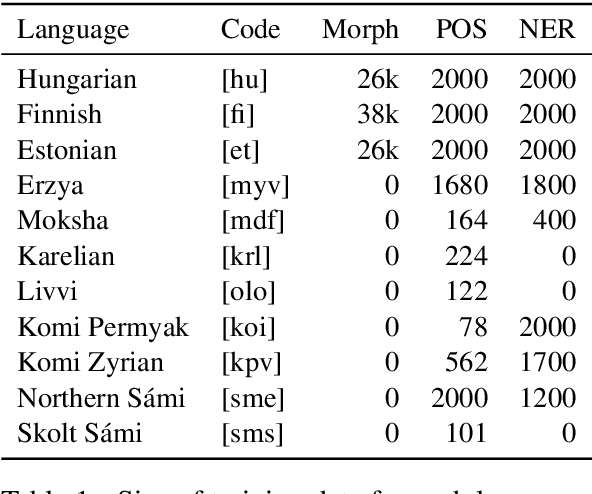

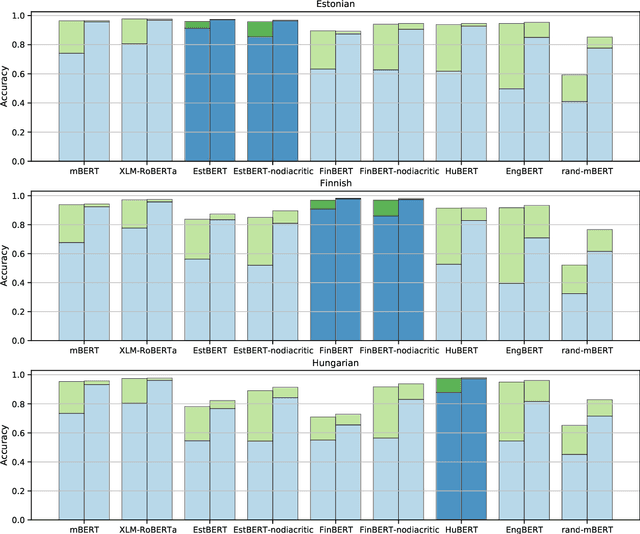
Transformer-based language models such as BERT have outperformed previous models on a large number of English benchmarks, but their evaluation is often limited to English or a small number of well-resourced languages. In this work, we evaluate monolingual, multilingual, and randomly initialized language models from the BERT family on a variety of Uralic languages including Estonian, Finnish, Hungarian, Erzya, Moksha, Karelian, Livvi, Komi Permyak, Komi Zyrian, Northern S\'ami, and Skolt S\'ami. When monolingual models are available (currently only et, fi, hu), these perform better on their native language, but in general they transfer worse than multilingual models or models of genetically unrelated languages that share the same character set. Remarkably, straightforward transfer of high-resource models, even without special efforts toward hyperparameter optimization, yields what appear to be state of the art POS and NER tools for the minority Uralic languages where there is sufficient data for finetuning.
Subword Pooling Makes a Difference
Feb 22, 2021
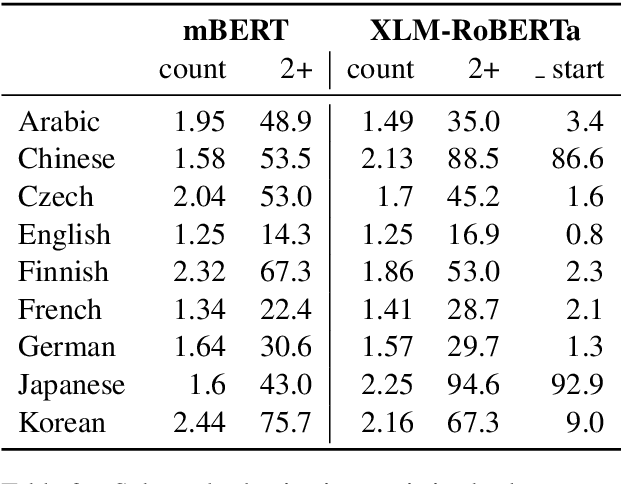

Contextual word-representations became a standard in modern natural language processing systems. These models use subword tokenization to handle large vocabularies and unknown words. Word-level usage of such systems requires a way of pooling multiple subwords that correspond to a single word. In this paper we investigate how the choice of subword pooling affects the downstream performance on three tasks: morphological probing, POS tagging and NER, in 9 typologically diverse languages. We compare these in two massively multilingual models, mBERT and XLM-RoBERTa. For morphological tasks, the widely used `choose the first subword' is the worst strategy and the best results are obtained by using attention over the subwords. For POS tagging both of these strategies perform poorly and the best choice is to use a small LSTM over the subwords. The same strategy works best for NER and we show that mBERT is better than XLM-RoBERTa in all 9 languages. We publicly release all code, data and the full result tables at \url{https://github.com/juditacs/subword-choice}.
Evaluating Contextualized Language Models for Hungarian
Feb 22, 2021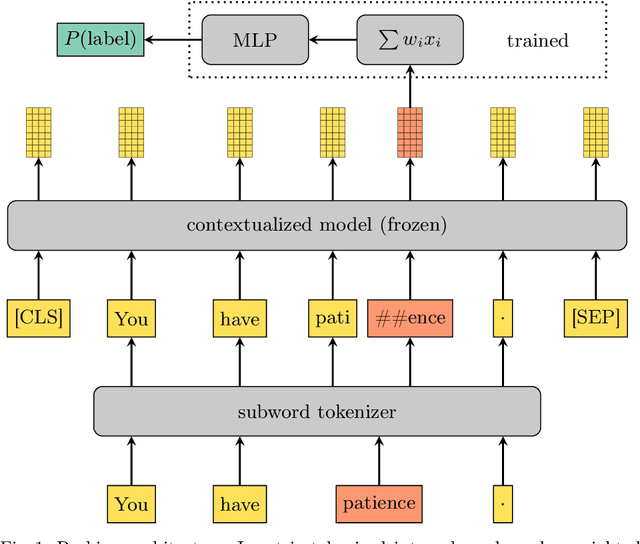
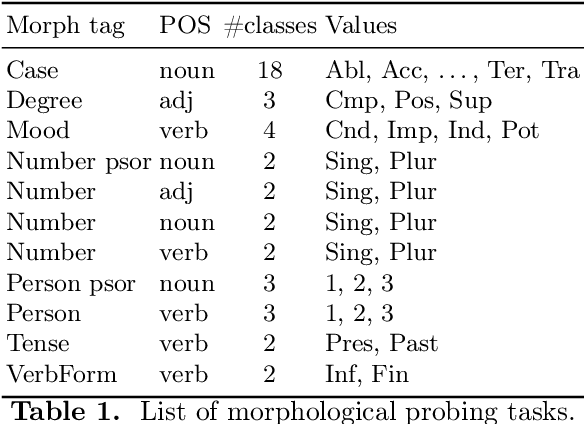


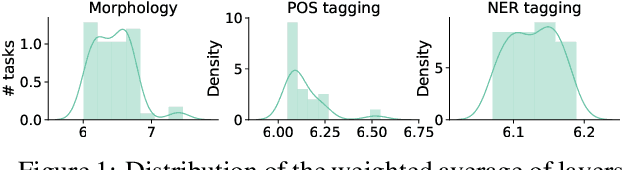
We present an extended comparison of contextualized language models for Hungarian. We compare huBERT, a Hungarian model against 4 multilingual models including the multilingual BERT model. We evaluate these models through three tasks, morphological probing, POS tagging and NER. We find that huBERT works better than the other models, often by a large margin, particularly near the global optimum (typically at the middle layers). We also find that huBERT tends to generate fewer subwords for one word and that using the last subword for token-level tasks is generally a better choice than using the first one.
Sentence Length
May 22, 2019



The distribution of sentence length in ordinary language is not well captured by the existing models. Here we survey previous models of sentence length and present our random walk model that offers both a better fit with the data and a better understanding of the distribution. We develop a generalization of KL divergence, discuss measuring the noise inherent in a corpus, and present a hyperparameter-free Bayesian model comparison method that has strong conceptual ties to Minimal Description Length modeling. The models we obtain require only a few dozen bits, orders of magnitude less than the naive nonparametric MDL models would.
A practical approach to language complexity: a Wikipedia case study
Aug 18, 2012



In this paper we present statistical analysis of English texts from Wikipedia. We try to address the issue of language complexity empirically by comparing the simple English Wikipedia (Simple) to comparable samples of the main English Wikipedia (Main). Simple is supposed to use a more simplified language with a limited vocabulary, and editors are explicitly requested to follow this guideline, yet in practice the vocabulary richness of both samples are at the same level. Detailed analysis of longer units (n-grams of words and part of speech tags) shows that the language of Simple is less complex than that of Main primarily due to the use of shorter sentences, as opposed to drastically simplified syntax or vocabulary. Comparing the two language varieties by the Gunning readability index supports this conclusion. We also report on the topical dependence of language complexity, e.g. that the language is more advanced in conceptual articles compared to person-based (biographical) and object-based articles. Finally, we investigate the relation between conflict and language complexity by analyzing the content of the talk pages associated to controversial and peacefully developing articles, concluding that controversy has the effect of reducing language complexity.
* 2 new figures, 1 new section, and 2 new supporting texts
Edit wars in Wikipedia
Feb 09, 2012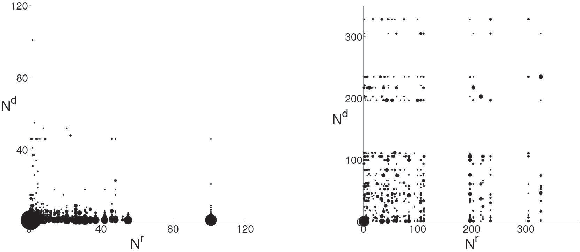
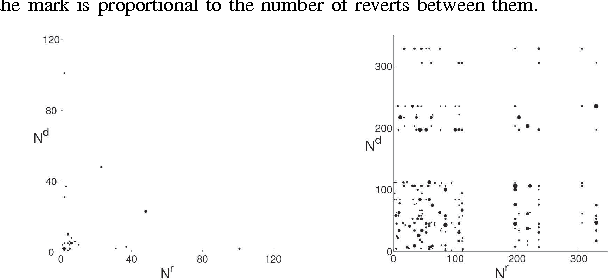
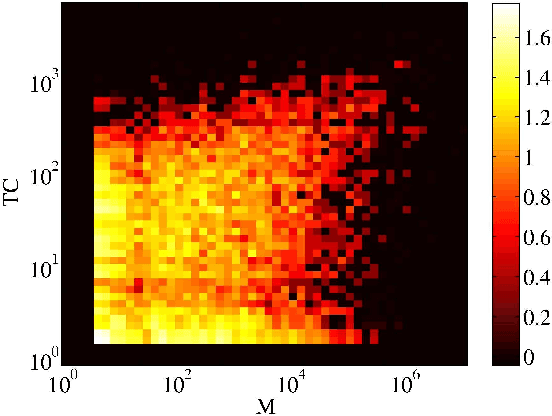
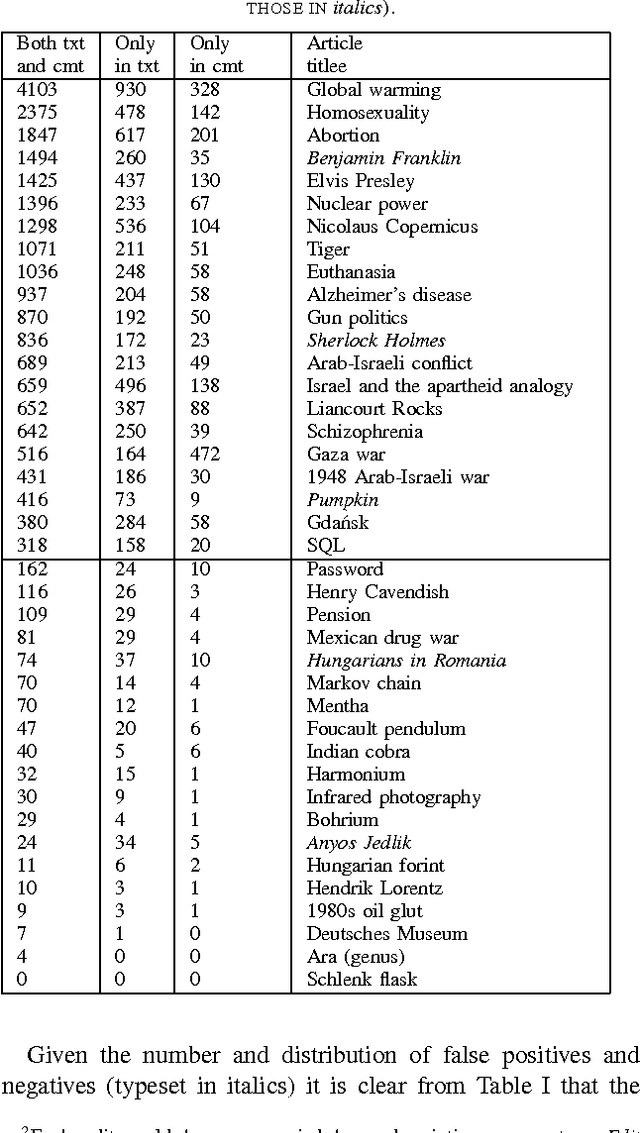
We present a new, efficient method for automatically detecting severe conflicts `edit wars' in Wikipedia and evaluate this method on six different language WPs. We discuss how the number of edits, reverts, the length of discussions, the burstiness of edits and reverts deviate in such pages from those following the general workflow, and argue that earlier work has significantly over-estimated the contentiousness of the Wikipedia editing process.
* 4 pages, 2 figures, 3 tables. The current version is shortened to be published in SocialCom 2011