 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuAMR: A Hungarian AMR Parser and Dataset
Feb 27, 2025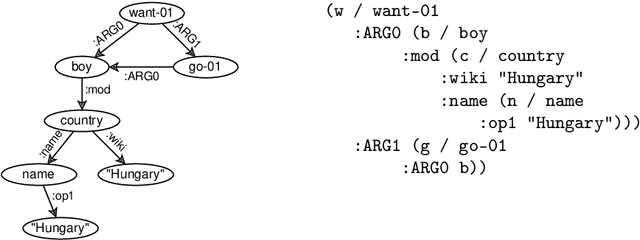
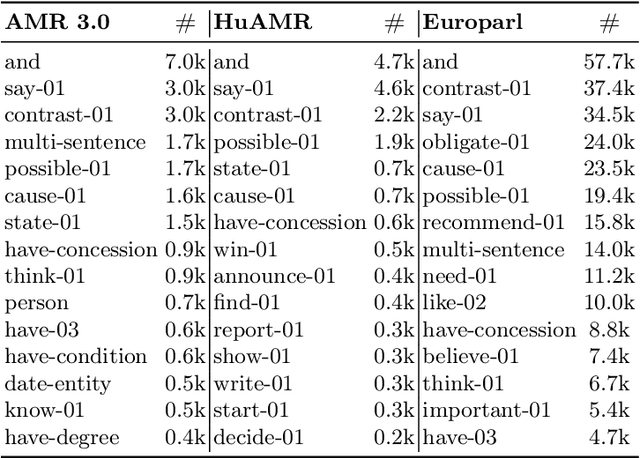
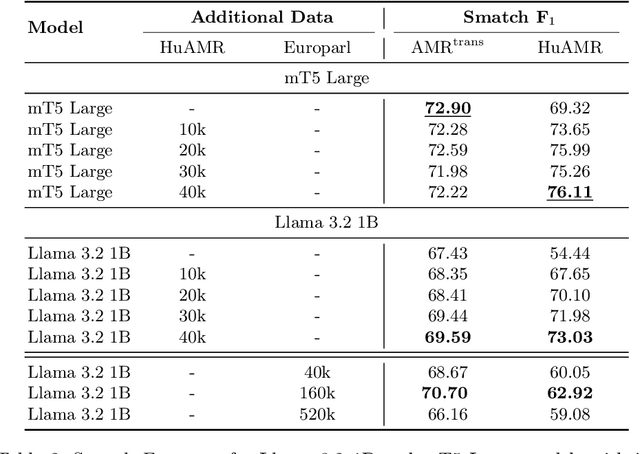
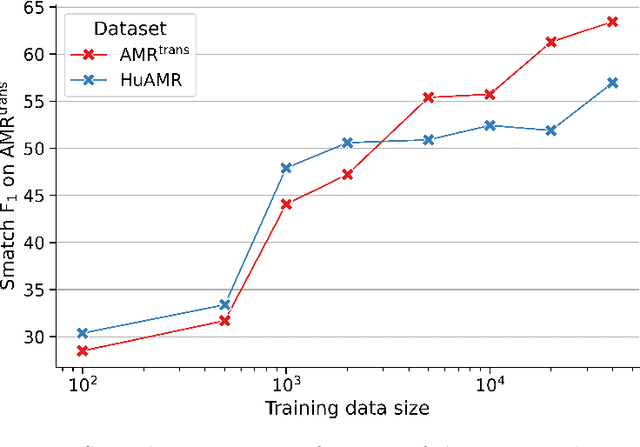
We present HuAMR, the first Abstract Meaning Representation (AMR) dataset and a suite of large language model-based AMR parsers for Hungarian, targeting the scarcity of semantic resources for non-English languages. To create HuAMR, we employed Llama-3.1-70B to automatically generate silver-standard AMR annotations, which we then refined manually to ensure quality. Building on this dataset, we investigate how different model architectures - mT5 Large and Llama-3.2-1B - and fine-tuning strategies affect AMR parsing performance. While incorporating silver-standard AMRs from Llama-3.1-70B into the training data of smaller models does not consistently boost overall scores, our results show that these techniques effectively enhance parsing accuracy on Hungarian news data (the domain of HuAMR). We evaluate our parsers using Smatch scores and confirm the potential of HuAMR and our parsers for advancing semantic parsing research.
From News to Summaries: Building a Hungarian Corpus for Extractive and Abstractive Summarization
Apr 12, 2024Training summarization models requires substantial amounts of training data. However for less resourceful languages like Hungarian, openly available models and datasets are notably scarce. To address this gap our paper introduces HunSum-2 an open-source Hungarian corpus suitable for training abstractive and extractive summarization models. The dataset is assembled from segments of the Common Crawl corpus undergoing thorough cleaning, preprocessing and deduplication. In addition to abstractive summarization we generate sentence-level labels for extractive summarization using sentence similarity. We train baseline models for both extractive and abstractive summarization using the collected dataset. To demonstrate the effectiveness of the trained models, we perform both quantitative and qualitative evaluation. Our dataset, models and code are publicly available, encouraging replication, further research, and real-world applications across various domains.
TreeSwap: Data Augmentation for Machine Translation via Dependency Subtree Swapping
Nov 04, 2023Data augmentation methods for neural machine translation are particularly useful when limited amount of training data is available, which is often the case when dealing with low-resource languages. We introduce a novel augmentation method, which generates new sentences by swapping objects and subjects across bisentences. This is performed simultaneously based on the dependency parse trees of the source and target sentences. We name this method TreeSwap. Our results show that TreeSwap achieves consistent improvements over baseline models in 4 language pairs in both directions on resource-constrained datasets. We also explore domain-specific corpora, but find that our method does not make significant improvements on law, medical and IT data. We report the scores of similar augmentation methods and find that TreeSwap performs comparably. We also analyze the generated sentences qualitatively and find that the augmentation produces a correct translation in most cases. Our code is available on Github.
Data Augmentation for Machine Translation via Dependency Subtree Swapping
Jul 13, 2023



We present a generic framework for data augmentation via dependency subtree swapping that is applicable to machine translation. We extract corresponding subtrees from the dependency parse trees of the source and target sentences and swap these across bisentences to create augmented samples. We perform thorough filtering based on graphbased similarities of the dependency trees and additional heuristics to ensure that extracted subtrees correspond to the same meaning. We conduct resource-constrained experiments on 4 language pairs in both directions using the IWSLT text translation datasets and the Hunglish2 corpus. The results demonstrate consistent improvements in BLEU score over our baseline models in 3 out of 4 language pairs. Our code is available on GitHub.
HunSum-1: an Abstractive Summarization Dataset for Hungarian
Feb 01, 2023



We introduce HunSum-1: a dataset for Hungarian abstractive summarization, consisting of 1.14M news articles. The dataset is built by collecting, cleaning and deduplicating data from 9 major Hungarian news sites through CommonCrawl. Using this dataset, we build abstractive summarizer models based on huBERT and mT5. We demonstrate the value of the created dataset by performing a quantitative and qualitative analysis on the models' results. The HunSum-1 dataset, all models used in our experiments and our code are available open source.
Syntax-based data augmentation for Hungarian-English machine translation
Jan 18, 2022



We train Transformer-based neural machine translation models for Hungarian-English and English-Hungarian using the Hunglish2 corpus. Our best models achieve a BLEU score of 40.0 on HungarianEnglish and 33.4 on English-Hungarian. Furthermore, we present results on an ongoing work about syntax-based augmentation for neural machine translation. Both our code and models are publicly available.
Evaluating Transferability of BERT Models on Uralic Languages
Sep 13, 2021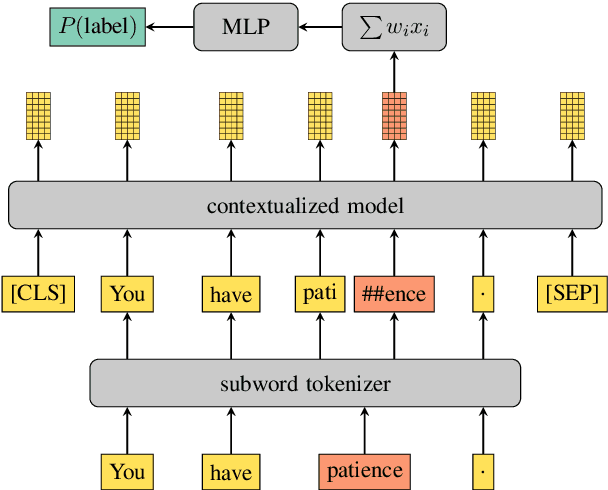
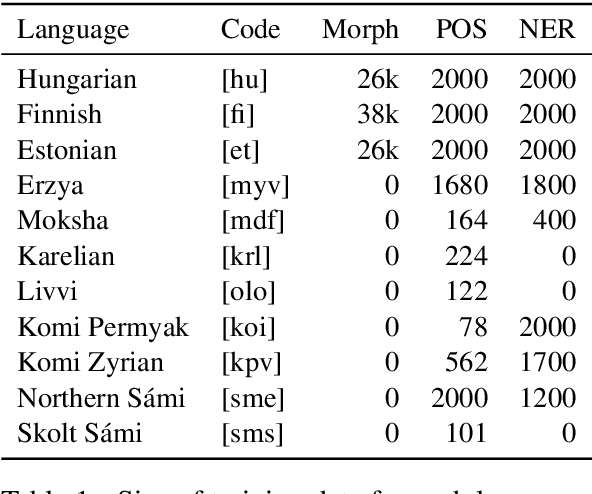

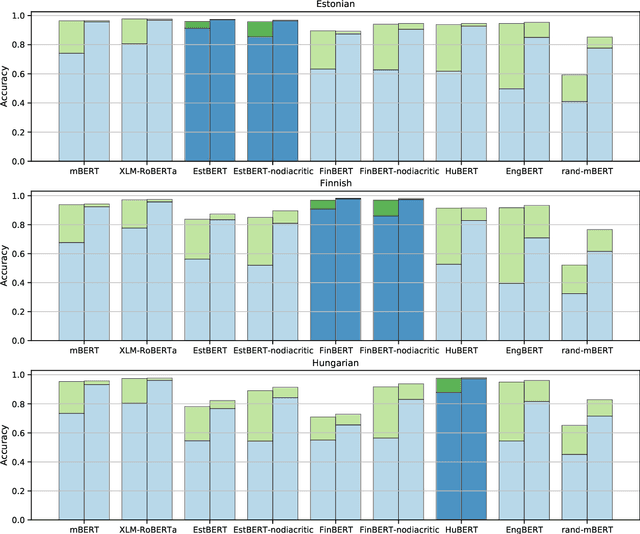
Transformer-based language models such as BERT have outperformed previous models on a large number of English benchmarks, but their evaluation is often limited to English or a small number of well-resourced languages. In this work, we evaluate monolingual, multilingual, and randomly initialized language models from the BERT family on a variety of Uralic languages including Estonian, Finnish, Hungarian, Erzya, Moksha, Karelian, Livvi, Komi Permyak, Komi Zyrian, Northern S\'ami, and Skolt S\'ami. When monolingual models are available (currently only et, fi, hu), these perform better on their native language, but in general they transfer worse than multilingual models or models of genetically unrelated languages that share the same character set. Remarkably, straightforward transfer of high-resource models, even without special efforts toward hyperparameter optimization, yields what appear to be state of the art POS and NER tools for the minority Uralic languages where there is sufficient data for finetuning.
Subword Pooling Makes a Difference
Feb 22, 2021
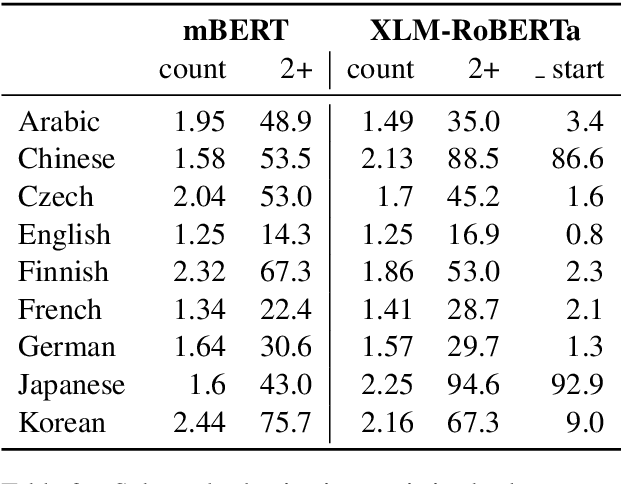

Contextual word-representations became a standard in modern natural language processing systems. These models use subword tokenization to handle large vocabularies and unknown words. Word-level usage of such systems requires a way of pooling multiple subwords that correspond to a single word. In this paper we investigate how the choice of subword pooling affects the downstream performance on three tasks: morphological probing, POS tagging and NER, in 9 typologically diverse languages. We compare these in two massively multilingual models, mBERT and XLM-RoBERTa. For morphological tasks, the widely used `choose the first subword' is the worst strategy and the best results are obtained by using attention over the subwords. For POS tagging both of these strategies perform poorly and the best choice is to use a small LSTM over the subwords. The same strategy works best for NER and we show that mBERT is better than XLM-RoBERTa in all 9 languages. We publicly release all code, data and the full result tables at \url{https://github.com/juditacs/subword-choice}.
Evaluating Contextualized Language Models for Hungarian
Feb 22, 2021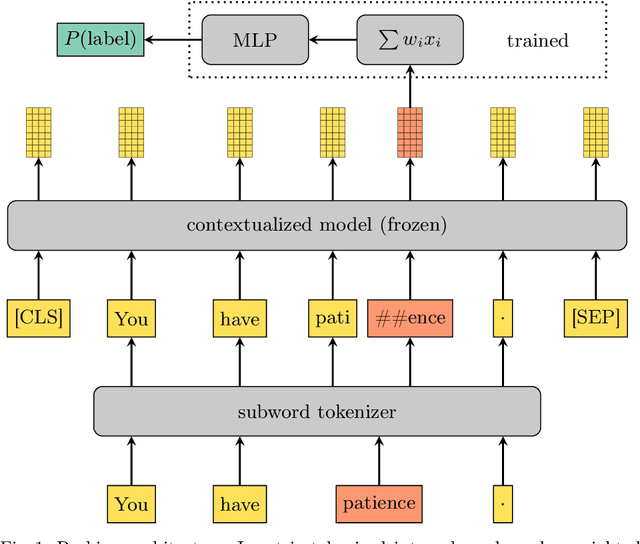
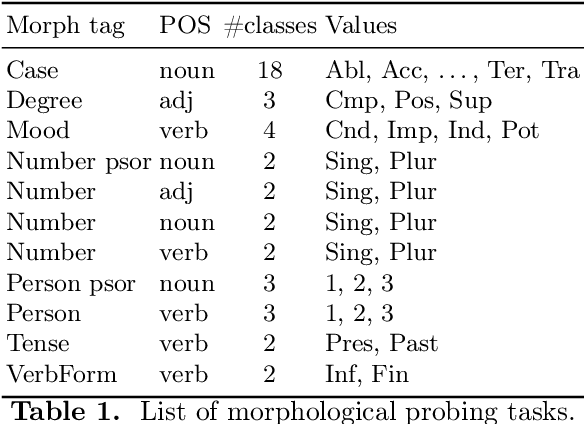


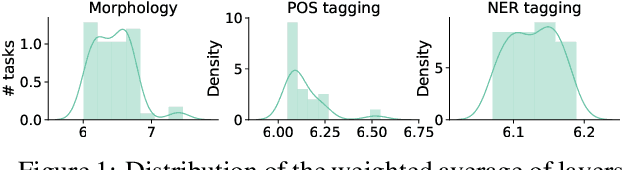
We present an extended comparison of contextualized language models for Hungarian. We compare huBERT, a Hungarian model against 4 multilingual models including the multilingual BERT model. We evaluate these models through three tasks, morphological probing, POS tagging and NER. We find that huBERT works better than the other models, often by a large margin, particularly near the global optimum (typically at the middle layers). We also find that huBERT tends to generate fewer subwords for one word and that using the last subword for token-level tasks is generally a better choice than using the first one.
Automatic punctuation restoration with BERT models
Jan 18, 2021



We present an approach for automatic punctuation restoration with BERT models for English and Hungarian. For English, we conduct our experiments on Ted Talks, a commonly used benchmark for punctuation restoration, while for Hungarian we evaluate our models on the Szeged Treebank dataset. Our best models achieve a macro-averaged $F_1$-score of 79.8 in English and 82.2 in Hungarian. Our code is publicly available.