 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Transferability of BERT Models on Uralic Languages
Sep 13, 2021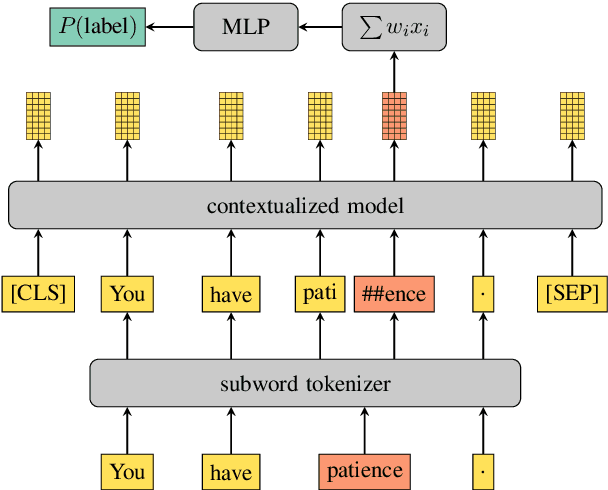
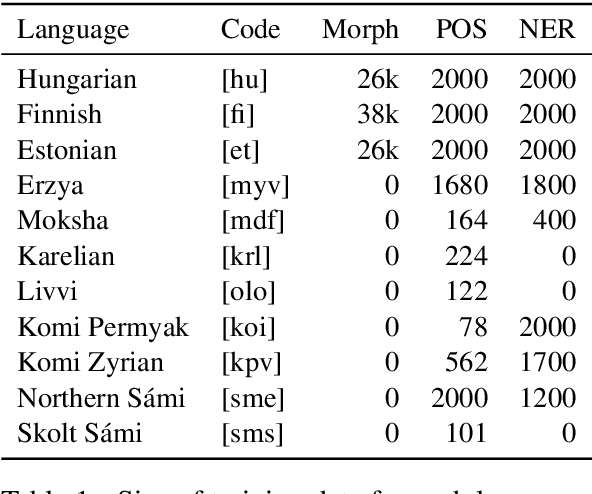

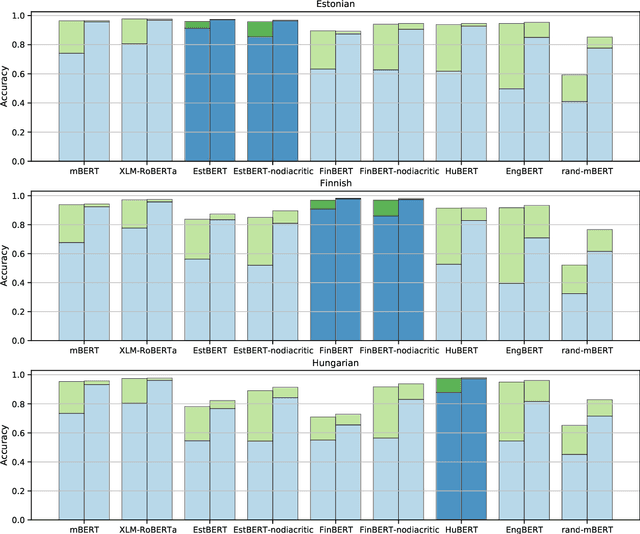
Transformer-based language models such as BERT have outperformed previous models on a large number of English benchmarks, but their evaluation is often limited to English or a small number of well-resourced languages. In this work, we evaluate monolingual, multilingual, and randomly initialized language models from the BERT family on a variety of Uralic languages including Estonian, Finnish, Hungarian, Erzya, Moksha, Karelian, Livvi, Komi Permyak, Komi Zyrian, Northern S\'ami, and Skolt S\'ami. When monolingual models are available (currently only et, fi, hu), these perform better on their native language, but in general they transfer worse than multilingual models or models of genetically unrelated languages that share the same character set. Remarkably, straightforward transfer of high-resource models, even without special efforts toward hyperparameter optimization, yields what appear to be state of the art POS and NER tools for the minority Uralic languages where there is sufficient data for finetuning.
Evaluating Contextualized Language Models for Hungarian
Feb 22, 2021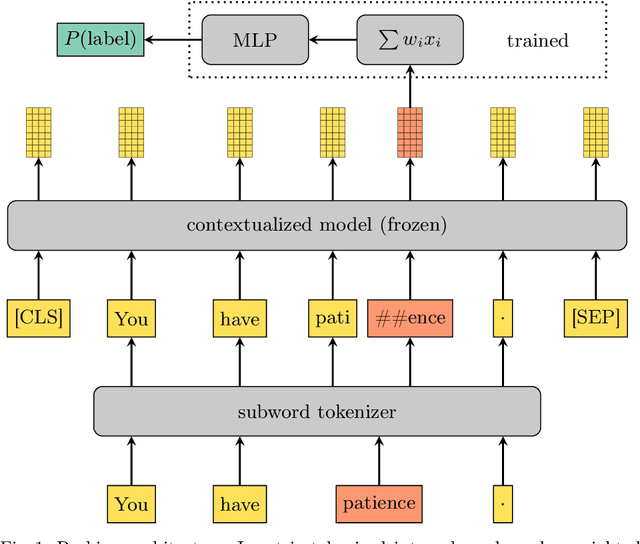


We present an extended comparison of contextualized language models for Hungarian. We compare huBERT, a Hungarian model against 4 multilingual models including the multilingual BERT model. We evaluate these models through three tasks, morphological probing, POS tagging and NER. We find that huBERT works better than the other models, often by a large margin, particularly near the global optimum (typically at the middle layers). We also find that huBERT tends to generate fewer subwords for one word and that using the last subword for token-level tasks is generally a better choice than using the first one.
Data-dependent Pruning to find the Winning Lottery Ticket
Jun 25, 2020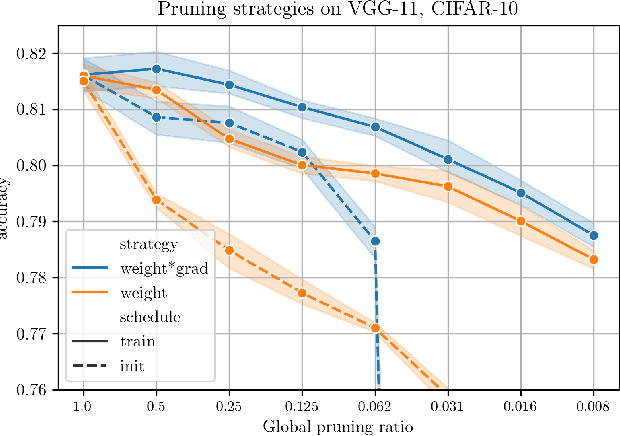
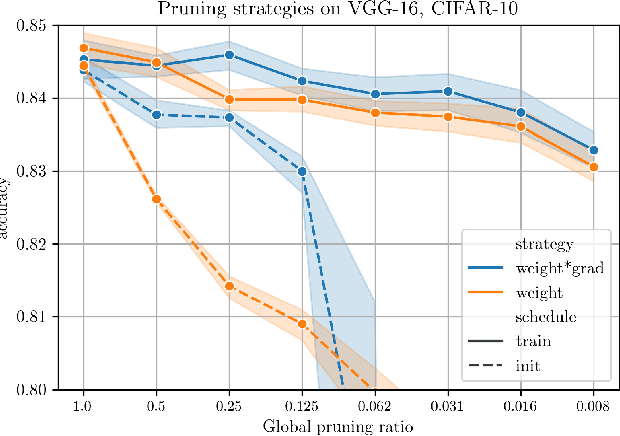
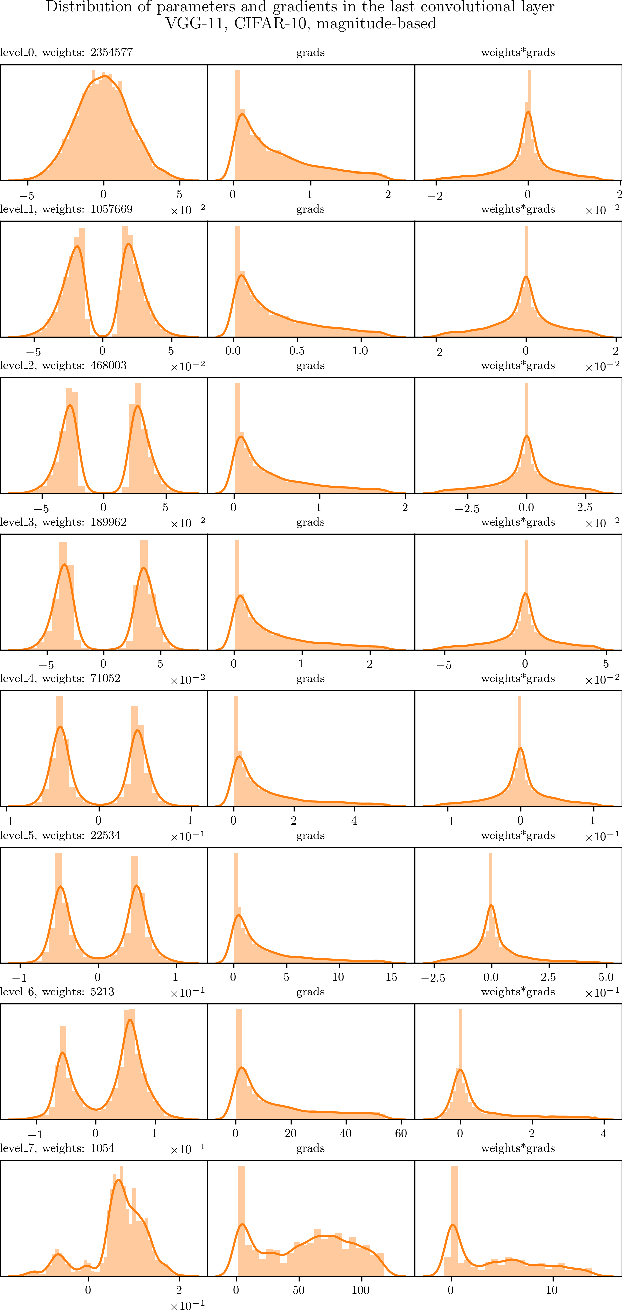
The Lottery Ticket Hypothesis postulates that a freshly initialized neural network contains a small subnetwork that can be trained in isolation to achieve similar performance as the full network. Our paper examines several alternatives to search for such subnetworks. We conclude that incorporating a data dependent component into the pruning criterion in the form of the gradient of the training loss -- as done in the SNIP method -- consistently improves the performance of existing pruning algorithms.