 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Attention Heads Compete or Cooperate during Counting?
Feb 10, 2025We present an in-depth mechanistic interpretability analysis of training small transformers on an elementary task, counting, which is a crucial deductive step in many algorithms. In particular, we investigate the collaboration/competition among the attention heads: we ask whether the attention heads behave as a pseudo-ensemble, all solving the same subtask, or they perform different subtasks, meaning that they can only solve the original task in conjunction. Our work presents evidence that on the semantics of the counting task, attention heads behave as a pseudo-ensemble, but their outputs need to be aggregated in a non-uniform manner in order to create an encoding that conforms to the syntax. Our source code will be available upon publication.
Towards Unbiased Exploration in Partial Label Learning
Jul 02, 2023We consider learning a probabilistic classifier from partially-labelled supervision (inputs denoted with multiple possibilities) using standard neural architectures with a softmax as the final layer. We identify a bias phenomenon that can arise from the softmax layer in even simple architectures that prevents proper exploration of alternative options, making the dynamics of gradient descent overly sensitive to initialisation. We introduce a novel loss function that allows for unbiased exploration within the space of alternative outputs. We give a theoretical justification for our loss function, and provide an extensive evaluation of its impact on synthetic data, on standard partially labelled benchmarks and on a contributed novel benchmark related to an existing rule learning challenge.
Safety without alignment
Mar 18, 2023Currently, the dominant paradigm in AI safety is alignment with human values. Here we describe progress on developing an alternative approach to safety, based on ethical rationalism (Gewirth:1978), and propose an inherently safe implementation path via hybrid theorem provers in a sandbox. As AGIs evolve, their alignment may fade, but their rationality can only increase (otherwise more rational ones will have a significant evolutionary advantage) so an approach that ties their ethics to their rationality has clear long-term advantages.
Lemmas: Generation, Selection, Application
Mar 10, 2023Noting that lemmas are a key feature of mathematics, we engage in an investigation of the role of lemmas in automated theorem proving. The paper describes experiments with a combined system involving learning technology that generates useful lemmas for automated theorem provers, demonstrating improvement for several representative systems and solving a hard problem not solved by any system for twenty years. By focusing on condensed detachment problems we simplify the setting considerably, allowing us to get at the essence of lemmas and their role in proof search.
Towards solving the 7-in-a-row game
Jul 05, 2021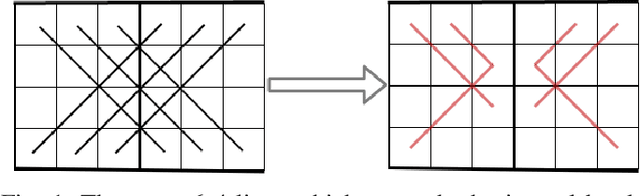
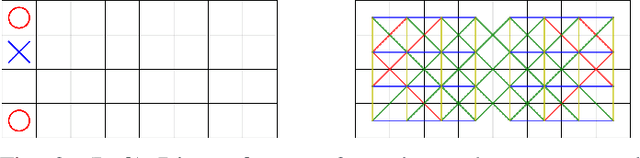
Our paper explores the game theoretic value of the 7-in-a-row game. We reduce the problem to solving a finite board game, which we target using Proof Number Search. We present a number of heuristic improvements to Proof Number Search and examine their effect within the context of this particular game. Although our paper does not solve the 7-in-a-row game, our experiments indicate that we have made significant progress towards it.
The Role of Entropy in Guiding a Connection Prover
May 31, 2021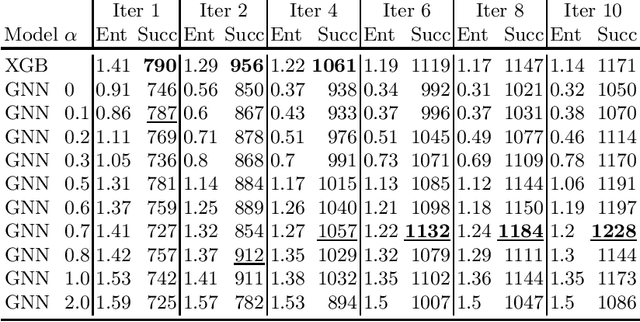
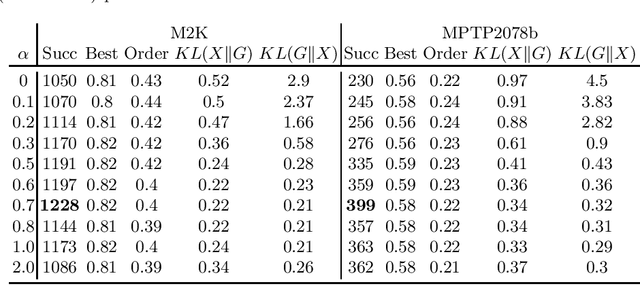
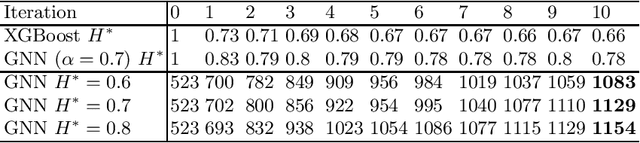
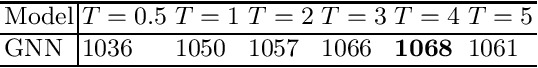
In this work we study how to learn good algorithms for selecting reasoning steps in theorem proving. We explore this in the connection tableau calculus implemented by leanCoP where the partial tableau provides a clean and compact notion of a state to which a limited number of inferences can be applied. We start by incorporating a state-of-the-art learning algorithm -- a graph neural network (GNN) -- into the plCoP theorem prover. Then we use it to observe the system's behaviour in a reinforcement learning setting, i.e., when learning inference guidance from successful Monte-Carlo tree searches on many problems. Despite its better pattern matching capability, the GNN initially performs worse than a simpler previously used learning algorithm. We observe that the simpler algorithm is less confident, i.e., its recommendations have higher entropy. This leads us to explore how the entropy of the inference selection implemented via the neural network influences the proof search. This is related to research in human decision-making under uncertainty, and in particular the probability matching theory. Our main result shows that a proper entropy regularisation, i.e., training the GNN not to be overconfident, greatly improves plCoP's performance on a large mathematical corpus.
Data-dependent Pruning to find the Winning Lottery Ticket
Jun 25, 2020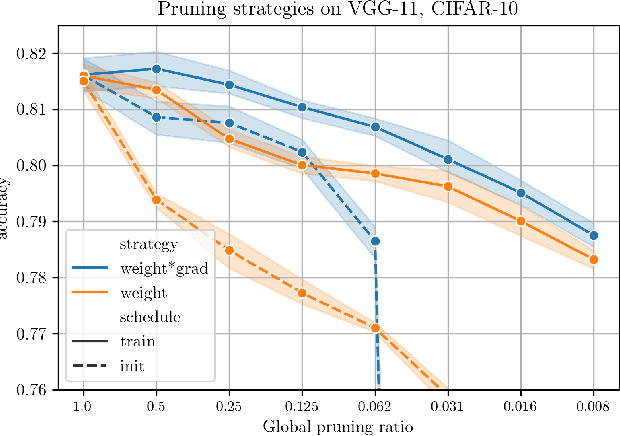
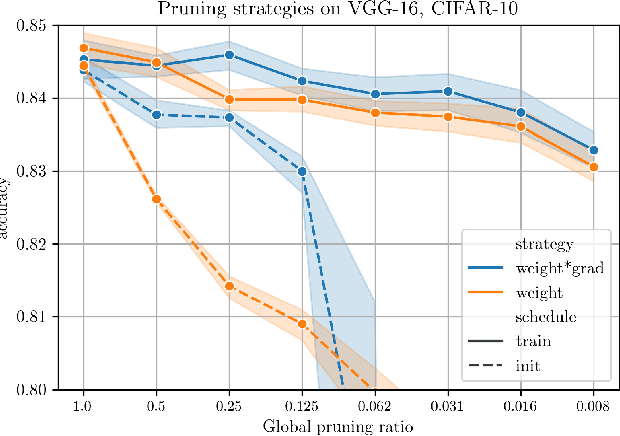
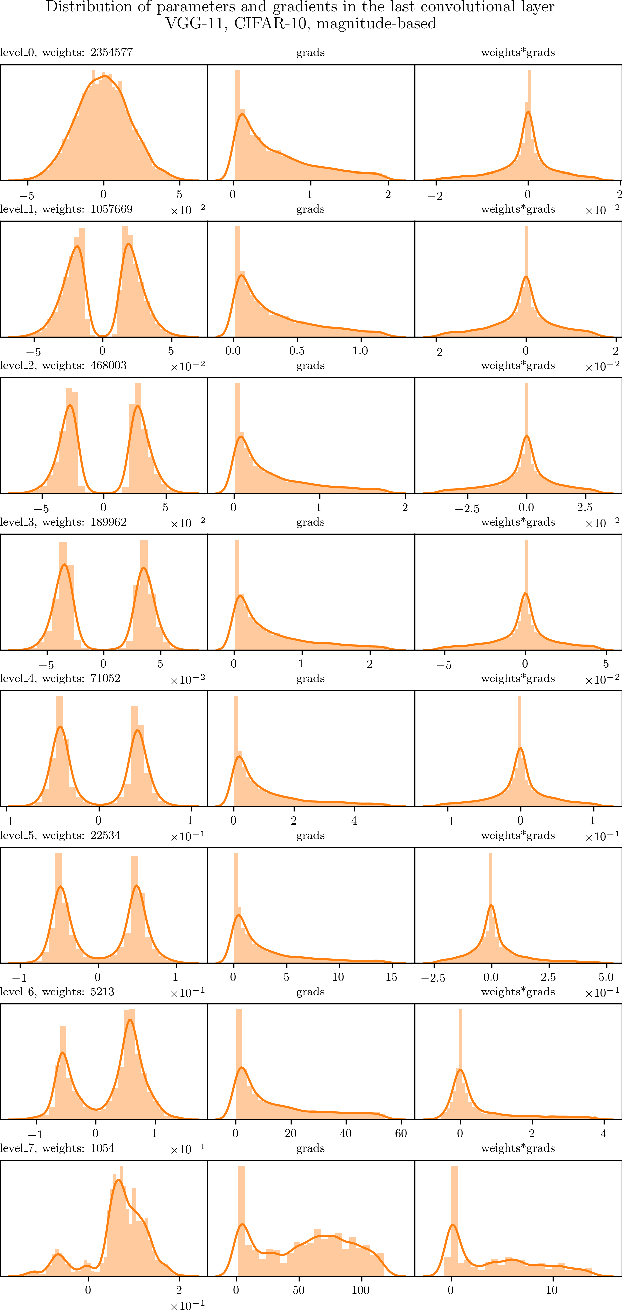
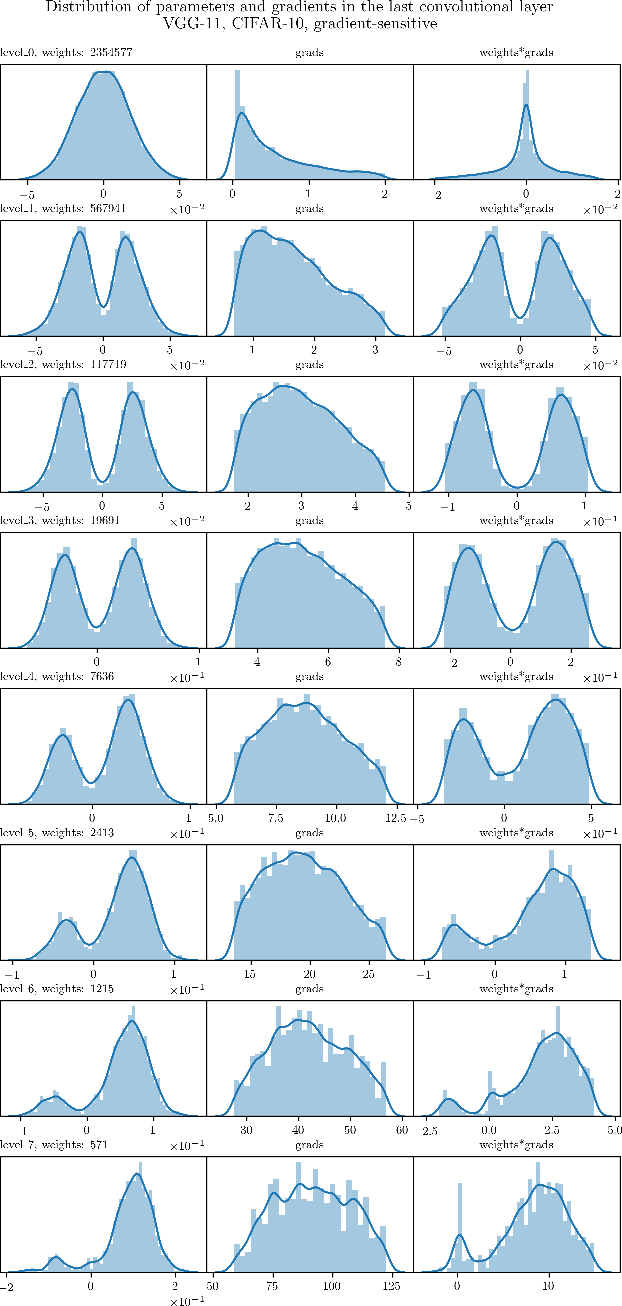
The Lottery Ticket Hypothesis postulates that a freshly initialized neural network contains a small subnetwork that can be trained in isolation to achieve similar performance as the full network. Our paper examines several alternatives to search for such subnetworks. We conclude that incorporating a data dependent component into the pruning criterion in the form of the gradient of the training loss -- as done in the SNIP method -- consistently improves the performance of existing pruning algorithms.
Prolog Technology Reinforcement Learning Prover
Apr 15, 2020

We present a reinforcement learning toolkit for experiments with guiding automated theorem proving in the connection calculus. The core of the toolkit is a compact and easy to extend Prolog-based automated theorem prover called plCoP. plCoP builds on the leanCoP Prolog implementation and adds learning-guided Monte-Carlo Tree Search as done in the rlCoP system. Other components include a Python interface to plCoP and machine learners, and an external proof checker that verifies the validity of plCoP proofs. The toolkit is evaluated on two benchmarks and we demonstrate its extendability by two additions: (1) guidance is extended to reduction steps and (2) the standard leanCoP calculus is extended with rewrite steps and their learned guidance. We argue that the Prolog setting is suitable for combining statistical and symbolic learning methods. The complete toolkit is publicly released.
Towards Finding Longer Proofs
May 30, 2019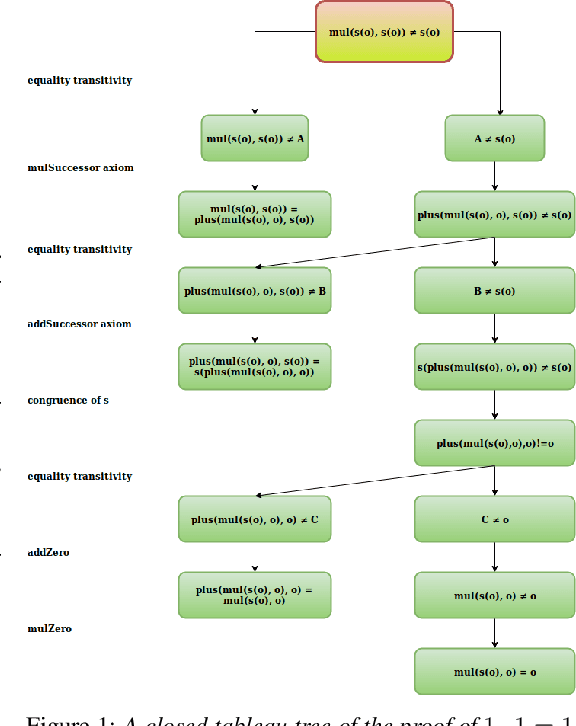
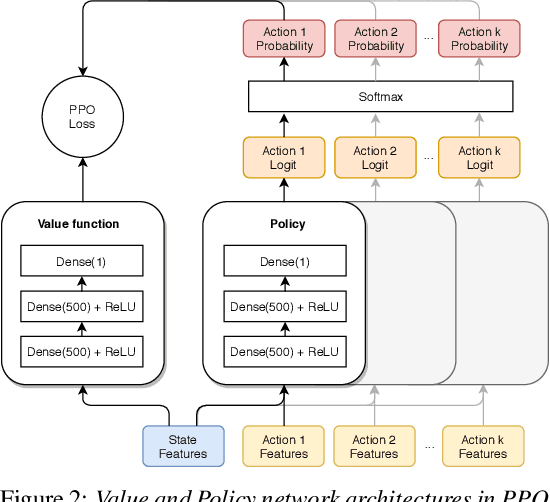
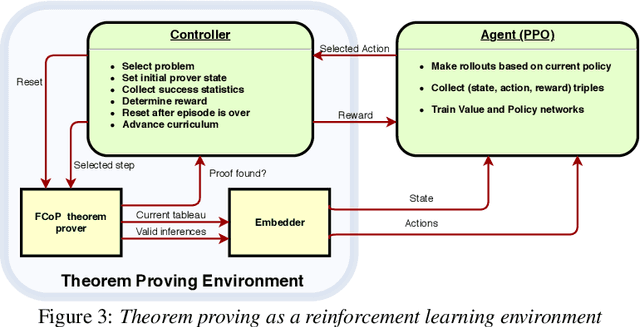
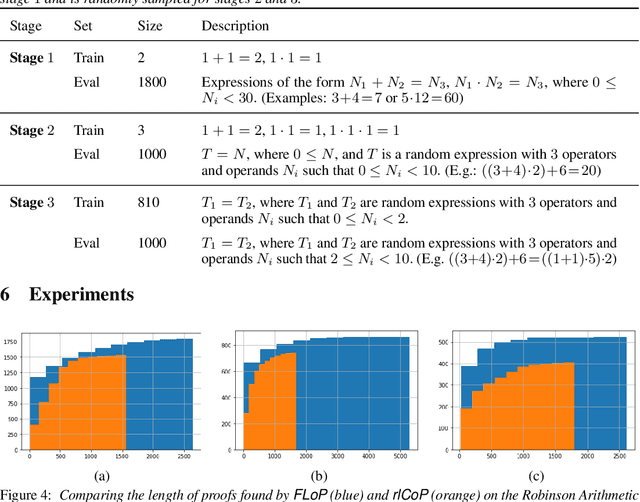
We present a reinforcement learning (RL) based guidance system for automated theorem proving geared towards Finding Longer Proofs (FLoP). FLoP focuses on generalizing from short proofs to longer ones of similar structure. To achieve that, FLoP uses state-of-the-art RL approaches that were previously not applied in theorem proving. In particular, we show that curriculum learning significantly outperforms previous learning-based proof guidance on a synthetic dataset of increasingly difficult arithmetic problems.
Gradient Regularization Improves Accuracy of Discriminative Models
May 24, 2018



Regularizing the gradient norm of the output of a neural network with respect to its inputs is a powerful technique, rediscovered several times. This paper presents evidence that gradient regularization can consistently improve classification accuracy on vision tasks, using modern deep neural networks, especially when the amount of training data is small. We introduce our regularizers as members of a broader class of Jacobian-based regularizers. We demonstrate empirically on real and synthetic data that the learning process leads to gradients controlled beyond the training points, and results in solutions that generalize well.